关于知识图谱,我们接下来该研究什么?斯坦福教授们给出了答案

本文整理了斯坦福大学 CS 520 知识图谱研讨会课程的第 10 集的内容,主要是关于知识图谱未来的研究方向,推荐给研究知识图谱的同学们~
1 使用强化学习进行多跳知识图谱推理
第一位演讲者:Richard Sochar
Richard 认为知识图谱未来的一个重要研究方向是使用强化学习进行多跳知识图谱推理。
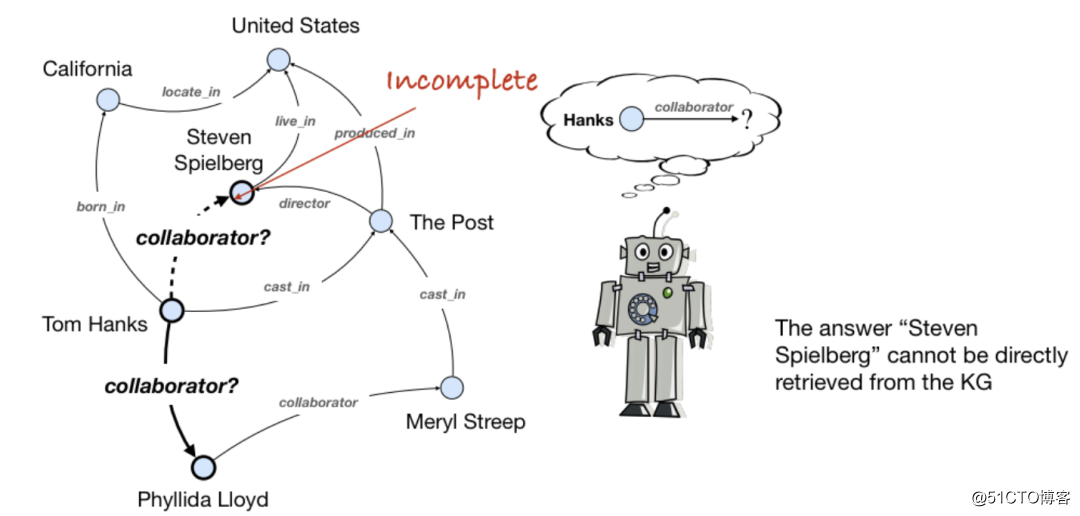
知识图谱的缺陷之一是不完整性,即知识图谱能存储的事实是有限的。对于知识图谱的重要应用——聊天机器人(Chatbot),也就是对话系统或者问答系统,其交互形式可以是文本或是图像。在对话过程中需要根据知识图谱进行推理,但知识图谱关于目标问题的知识可能是残缺或者有噪音的,所以算法应当具有一定的鲁棒性。对于知识图谱的不完整性,有以下解决方案:
知识图谱嵌入
知识图谱嵌入是一种发现缺失事实的有效方法。它将知识图谱中的所有实体或关系嵌入到连续向量空间中。采用强化学习进行推理时,可以使用知识图谱嵌入,便于神经网络对实体进行处理。但是知识图谱嵌入通常缺少可解释性。
多跳推理模型
现有的多跳推理模型通常采用序列决策的思路。从问题中提取实体,然后在知识图谱中学习如何在实体间进行推理。
强化学习框架
强化学习中需要关注五个要素:
- 环境 environment:在该任务中,环境是一个知识图谱
状态 state:例如,当前已经遍历过的一个子图
动作 action:例如,选择一个结点进行扩展
转换 transition:采取一个动作后,状态发生改变,直到一个定义的推理终点
奖励 reward:在推理正确时获得奖励
使用强化学习进行推理可解释性较强,可以从算法给出的推理路径中分析结果的产生原因。
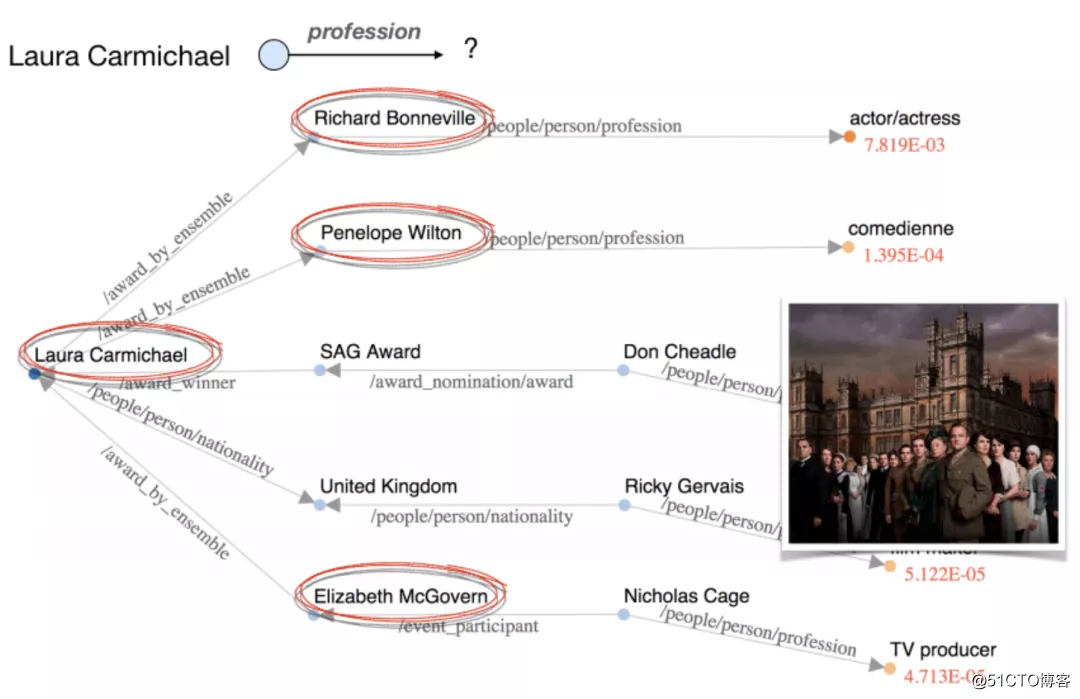
多跳推理是可解释的,但是准确较低。常常将知识图谱嵌入与强化学习框架结合使用,从而兼顾可解释性和准确性。
该方法还可以推广到联合知识图谱和文本的多跳推理上。
2 知识图谱到底知道什么?
第二位演讲者:Mark A. Musen 博士
Mark 想讨论的是非常根本的一个问题——我们知道了什么是图,但什么是知识?我们如何确保知识被存储到了图中?关于这个问题的答案,Mark从早年的研究历史开始谈起。
上世纪中叶,Stanford 想要开发一个专家系统,帮助医生做临床决策。他们先是考虑用语义网络来实现这一任务。还有一个早期用于帮助决策的专家系统,叫做MYCIN,出现于 70~80 年代。它是包含大量复杂的规则供专家进行决策。在这个年代,符号化的人工智能也被认为是医疗健康行业的未来。但是,对这类方法的质疑逐渐显现。包含大量规则的系统真的是可以维护的吗?语义网络(知识图谱)能够支持查找之外的任何形式的推理吗?什么样的知识表示可能可以支持一个最智能的系统呢?
Allen Newell 在 1980 年提出:我们应该停止争论如何表示知识,真正重要的是系统中有怎样的知识,而不是如何用计算机进行表示。知识是观察者赋予智能体的。知识是解决问题的能力。
- 我们无法“看见”知识,或将它写下来。所谓“道可道,非常道。名可名,非常名。”
- 我们永远无法得知智能体到底懂得了什么。所谓“子非鱼,安知鱼之乐。子非我,安知我不知鱼之乐。”
- 我们只能认为智能体有知识的条件是:
- 似乎有目标
- 似乎能选择行为能实现目标![]似乎能选择行为能实现目标
- 似乎能理智地选择行为
语义网被认为有希望在 Web 级别的数据上解决问题。但Mark 认为相关研究者似乎忽视了本体论和 Web 服务的作用,只顾玩弄链接数据的概念。日益增长的链接数据被表示为知识图谱。正如上个世纪那样,我们又开始过分关注知识表示的状态,而越来越少地讨论如何利用它解决问题。只有图,我们仍然做不了任何事情。
我们又重新开始研究如何将知识表示为图。如今,庞大的知识图谱相比当年的语义网络,拥有更加丰富的信息。我们已经知道一些表示和生成智能行为的方法了,但还有很多应用没有开始研究,有很多行为还没有想到如何去建模——这是我们未来可以努力的方向。
3 Data Commons
第三位演讲者:RV Guha
数据正在驱动很多应用,政策、新闻、健康、科学等。目前的问题不在于数据的缺乏,而是数据有太多的格式和规范。我们搜寻数据源、清洗数据、搞定数据存储……在这个过程中存在启动成本高昂,生态系统不完整,工具较少的问题。我们如何使数据的使用变得更加简单?
Data Commons 是一个 Google 发起的项目,尝试解决知识图谱构建中的上述问题,从不同数据源合成一个开放知识图谱。Guha 团队想要做的是,从原本搜索数据集、下载、清洗、归一化、融合的繁琐流程,简化到直接搜索谷歌即可获得数据集。
该项目的优势在于,通过清洗、归一化和将多个数据集进行融合的方式,轻松构建一个知识图谱,无需清理和加入数据。
目前通过 Data Commons 构建的知识图谱包括按地理区域的美国人口普查公报、美国国家海洋和大气管理局提供的天气历史与预报、美国劳工统计局的就业与失业统计等。
以上是对课程的简单的笔记,并不足以涵盖课程中的细节,感兴趣的同学们可以刷起来啦~

- 【2018 BDIC分赛区特等奖团队报道】大数据技术技能***采展示(上)
- 工业界求解NER问题的12条黄金法则
- 【周末AI课堂】基于贝叶斯推断的回归模型(代码篇)| 机器学习你会遇到的“坑”
- Java 持久层框架之 MyBatis
- 【周末AI课堂】基于贝叶斯推断的回归模型(理论篇)| 机器学习你会遇到的“坑”
- 超一流 | 从XLNet的多流机制看最新预训练模型的研究进展
- 算法工程师思维导图—数据结构与算法
- SQL学习(四)集合运算
- Java 持久层框架之 MyBatis
- 你以为虎扑和吴亦凡仅仅是“skr”那么简单吗?
- 13行代码搞定卷积计算?嗯哼,YES!
- FCES 2018 青年教师的内涵竞争力培养panel:帽子人才VS口碑人才
- 如何优雅地使用云原生 Prometheus 监控集群
- 如何优雅地使用云原生 Prometheus 监控集群
- .NET 云原生架构师训练营(模块二 基础巩固 路由与终结点)--学习笔记
- 浅析Linux 64位系统虚拟地址和物理地址的映射及验证方法
- Vue快速使用
- Azure Service Bus(二)在NET Core 控制台中如何操作 Service Bus Queue
- 机器学习知识点整理(三)
- 每日CSS_发光文本效果