【周末AI课堂】简单的自编码器(理论篇)| 机器学习你会遇到的“坑”
AI课堂开讲,就差你了!
很多人说,看了再多的文章,可是没有人手把手地教授,还是很难真正地入门AI。为了将AI知识体系以最简单的方式呈现给你,从这个星期开始,芯君邀请AI专业人士开设“周末学习课堂”——每周就AI学习中的一个重点问题进行深度分析,课程会分为理论篇和代码篇,理论与实操,一个都不能少!
来,退出让你废寝忘食的游戏页面,取消只有胡吃海塞的周末聚会吧。未来你与同龄人的差异,也许就从每周末的这堂AI课开启了!

我们在统计学习中曾经对无监督学习有了一定的了解,它不使用数据的label,在理论上主要分为两大类:
• 对特征进行降维,揭示数据自身的关系。线性办法如PCA,MDS,非线性办法主要有两类,一类加入Kernel trick,如KPCA,另一类则是流形学习,如LLE,t-SNE,ISOMAP等等。详情请看之前的课程《线性降维方法》和《非线性降维方法》的理论篇和代码篇。
此外,在特征选择过程中,我们所采用的filter方法,如相关系数,卡方检验,互信息等等。
• 对样本进行聚类,揭示数据之间的关系。根据指导思路的不同分为,基于原型聚类如k-means,基于密度的聚类如DBSCAN,基于集合的聚类如hierarchical clustering,基于网格的聚类等等。详情请看之前课程《聚类的几个重要问题》理论篇和代码篇。
在实际使用过程中,降维的重要性远远大于聚类的重要性。在深度学习中,隐层的作用都只是获得一个更好的表示,而降维的过程就是这样一个进行特征线性或者非线性组合组合的办法,而根据万能近似定理,在前馈神经网络中添加sigmoid(主要提供非线性)的足够多的神经元就可以拟合任意的函数,显然神经网络提取的特征可能具有更大的表示空间,只要使用合理,那么会有着更好的性能。
那么我们能否利用一个神经网络来做降维这件事情呢?其中,最简单的形式就是自编码器(Auto-encoder)。

简单Auto-Encoder的常用形式
作为一种无监督学习的简单模型,它有三个组成部分:输入,隐层,输出,由输入到隐层叫做编码(encoder),从隐层到输出叫做解码(decoder):
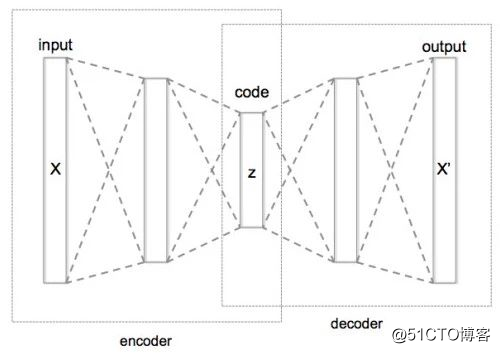
如图,我们假设维数最低的z为我们想要的结果,那么从X到z的过程就是编码,从z到输出X'的过程就叫做解码,这样的就叫做bottle layer。
我们将上面的结构可以理解为,编码的过程就是在利用将输入X变为z=f(X),然后再通过解码将z恢复为一个与X有一定关系的X'。我们可以认为z是X的一个低维表示,这一过程会很多人误解的4个问题:
• 只有z才能被看作低维表示吗?
事实上,就像上图向我们展示的那样,它总共包括三个隐层,每一个隐层都可以看作是输入的低维表示,我们这里特别选取z的原因并不是因为对称(这只在直觉意义上),而只是因为z的维数低,最符合我们的要求。
• 输出可以等于输入吗?
一般来说,我们不应该让输入等于输出,否则神经网络每一步都可能只是在执行简单的复制任务,这样的编码器就没有任何作用。
但这样的情况完全可以通过调节隐层维度来避免,如果我们强行设置隐层的维数少于输入的维数,这样的编码器叫做欠完备(undercomplete)自编码器,那么自编码器就会学习到低维表示。即便我们把每个隐层都在看作复制任务,维度的降低仍然需要神经网络考虑输入数据的哪些部分需要被优先考虑,以方便重构它。
• 编码器的深度如何确定?
一般来说,编码器的深度不适宜过深,同样是因为万能近似定理,容量太大的编码器可能会将任何输入都映射为相同的编码。我们希望对于不同的数据都得到不同的表示,而过深的编码器拟合能力太过强大,以至于编码不能反映出差异化的信息。
但是,同样根据万能近似定理,足够深的编码器更有可能获得更好的表示,对数据的压缩效果更好。合理的深度要根据我们将这样的特征嵌入到具体的任务中来观察。但总体来看,加深的优势更多。
• 自编码器与PCA的联系是什么?
当我们在神经网络中不使用任何激活函数,并且损失函数选择均方误差的时候,自编码器就与PCA等价,当我们在利用最小化重构误差的方式(而非最大化投影方差)来推导PCA的时候,就越能理解到这一点。
从上面的问题中可以看出,自编码器最主要的作用就是降维,这也是在历史上自编码器被提出的重要的动机,但是自编码器的形式并不局限于此。我在这里介绍自编码器的两个经典推广。

稀疏自编码器(SAE)
用于降维的自编码器有一个缺点,那就是我们需要设定好隐层的维度,在网络结构确定的情况下,隐。解决这个问题的思路是将隐层的维度扩大,让神经网络自己习得一个稀疏编码(大部分的神经元为零),高维但稀疏的表示更加灵活,更加符合我们的需要。
但如果我们将隐层的维度增加到比输入还高,那么这一层很有可能只是在执行复制操作。所以我们需要在损失函数中加入惩罚项来达到这一效果,原本的损失函数只是度量了输入与输出之间的差异:
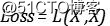
在添加惩罚项的时候,我们可以选择较为直接的方式,直接模仿我们的L1正则化方式,添加类似于LASSO的惩罚:
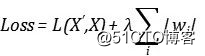
这样随着我们调节图片增加,权重就会越往靠近0的空间中移动,以达到稀疏化的结果。但是惩罚项的系数大小会成为一个需要调节的超参数,太大则有可能将表示过度压缩,稀疏化太严重,导致训练失败,因为根本无法重构出数据,太小则稀疏化程度不够,隐层只是在复制。
我们通常可以采用另一种惩罚项,神经单元的整体的稀疏程度可以用一个概率分布来表示:
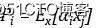
其中
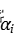 表示隐层单元的激活程度,激活程度是一个数值,在sigmoid函数中,越靠近1,激活程度越高,具体的量化形式要根据具体的激活函数而定。
表示隐层单元的激活程度,激活程度是一个数值,在sigmoid函数中,越靠近1,激活程度越高,具体的量化形式要根据具体的激活函数而定。
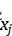 表示输入的数据。稀疏程度衡量的就是某个神经元在不同输入数据下的平均活跃度,之所以取平均,只是因为数据的数值如果过大,会拉高整体的活跃度,总体数据的平均会防止这一点。
表示输入的数据。稀疏程度衡量的就是某个神经元在不同输入数据下的平均活跃度,之所以取平均,只是因为数据的数值如果过大,会拉高整体的活跃度,总体数据的平均会防止这一点。
我们可以定义好我们所需要的稀疏程度P,并也将其看作一个概率分布,我们希望这两个分布越接近越好,交叉熵和相对熵这两个都可以作为我们的度量标准,都不具有对称性。(详情请看之前的课程《深度学习中的熵》)
但是当他们作为惩罚项时,就像L1、L2正则化一样,有时候我们希望它在理论上可以缩减到零。更重要的是,在计算上,交叉熵要比相对熵多计算一个训练分布的熵,计算成本主要体现在
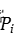 的估计上,在计算神经元的后向传播之前,训练样本每次前向传播,才能获取平均激活度,这不是固定的。
的估计上,在计算神经元的后向传播之前,训练样本每次前向传播,才能获取平均激活度,这不是固定的。
所以我们经常采用相对熵。(详情请看之前的课程《深度学习中的熵》)。假设隐层有m个神经元,损失函数最后会被写作:
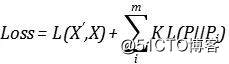

去噪自编码器(DAE)
去除噪声的过程就是寻找表示的过程,在得到的表示中,噪声项就不会得到表达,或者只得到微弱的表达。自编码器也可以实现去除噪声,而且方式较为简单粗暴,我们直接将添加噪声的数据作为输入,而将没有噪声的数据作为输出,隐层获得的表示就可以看作噪声并不会表达的表示,来达到去噪的效果。
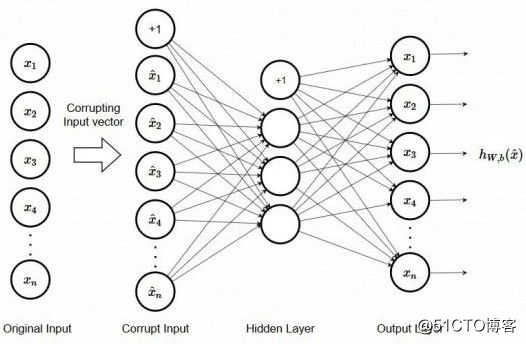
如图,我们将输入破坏,作为新的输入,以此来训练模型。
随之而来的问题是,我们会对隐层的维度不做要求,它可大可小,只要能执行去噪任务即可,一定程度上也可以实现去噪效果,但噪声一般比较小,即使执行复制任务,最后的损失函数可能也不会很大,甚至会出现Loss太小,参数更新非常慢的情况,那么我们还可以在损失函数中加入一个惩罚项:
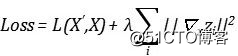
这个梯度项表示着隐层的单元对于输入x变化较为稳定,它越小,就代表着越稳定。这种添加梯度项作为正则化手段的损失函数并不是很常见,因为在深层网络中,它会变得非常难以计算,但在浅层网络中,实践和理论上都具有非常优美的结果。

读芯君开扒
课堂TIPS
• 除了普通的AE,DAE,SAE,我们还会在后续课程中介绍一种叫做VAE的生成式模型,与GAN放在一起。对于聚类问题,SOM网络通过保持拓扑性质可以直接打到聚类的目的,这一部分对于初学者理解起来较为困难,所以仍然在后面的课程中。

留言 点赞 发个朋友圈
我们一起分享AI学习与发展的干货
作者:唐僧不用海飞丝 如需转载,请后台留言,遵守转载规范
推荐文章阅读
【周末AI课堂 | 第五十讲】SELU和ResNet(代码篇)
【周末AI课堂 | 第四十九讲】SELU和ResNet(理论篇)
【周末AI课堂 | 第四十八讲】CNN在Keras中的实践
【周末AI课堂 | 第四十七讲】卷积之上的新操作(代码篇)
【周末AI课堂 | 第四十六讲】卷积之上的新操作(理论篇)
【周末AI课堂 | 第四十五讲】认识批标准化的三种境界(代码篇)
【周末AI课堂 | 第四十四讲】认识批标准化的三种境界(理论篇)
【周末AI课堂 | 第四十三讲】神经网络的正则化(代码篇)
【周末AI课堂 | 第四十二讲】神经网络的正则化(理论篇)
【周末AI课堂 | 第四十一讲】深度学习中的熵(代码篇)
【周末AI课堂 | 第四十讲】深度学习中的熵(理论篇)
【周末AI课堂 | 第三十九讲】理解softmax函数
【周末AI课堂 | 第三十八讲】常见隐藏单元(代码篇)
【周末AI课堂 | 第三十七讲】常见隐藏单元(理论篇)
【周末AI课堂 | 第三十六讲】隐藏单元的设计原则(代码篇)
【周末AI课堂 | 第三十五讲】隐藏单元的设计原则(理论篇)
【周末AI课堂 | 第三十四讲】神经网络综观(代码篇)
【周末AI课堂 | 第三十三讲】神经网络综观(理论篇)
【周末AI课堂 | 第三十二讲】从感知机到深度学习(代码篇)
【周末AI课堂 | 第三十一讲】从感知机到深度学习(理论篇)
【周末AI课堂 | 第三十讲】理解梯度下降(二)(代码篇)
【周末AI课堂 | 第二十九讲】理解梯度下降(二)(理论篇)
【周末AI课堂 | 第二十八讲】理解梯度下降(一)(代码篇)
【周末AI课堂 | 第二十七讲】理解梯度下降(一)(理论篇)
【周末AI课堂 | 第二十六讲】理解损失函数(代码篇)
【周末AI课堂 | 第二十五讲】理解损失函数(理论篇)
【周末AI课堂 | 第二十四讲】聚类的几个重要问题(代码篇)
【周末AI课堂 | 第二十三讲】聚类的几个重要问题(理论篇)
【周末AI课堂 | 第二十二讲】Boosting集成(代码篇)
【周末AI课堂 | 第二十一讲】Boosting集成(理论篇)
【周末AI课堂 | 第二十讲】bagging集成和stacking集成(代码篇)
【周末AI课堂 | 第十九讲】bagging集成和stacking集成(理论篇)
【周末AI课堂 | 第十八讲】非参模型进阶(代码篇)
【周末AI课堂 | 第十七讲】非参模型进阶(理论篇)
【周末AI课堂 | 第十六讲】非参模型初步(代码篇)
【周末AI课堂 | 第十五讲】非参模型初步(理论篇)
【周末AI课堂 | 第十四讲】基于贝叶斯推断的回归模型(代码篇)
【周末AI课堂 | 第十三讲】基于贝叶斯推断的回归模型(理论篇)
【周末AI课堂 | 第十二讲】基于贝叶斯推断的分类模型(代码篇)
【周末AI课堂 | 第十一讲】基于贝叶斯推断的分类模型(理论篇)
【周末AI课堂 | 第十讲】核技巧(代码篇)
【周末AI课堂 | 第九讲】核技巧(理论篇)
【周末AI课堂 | 第八讲】非线性降维方法(代码篇)
【周末AI课堂 | 第七讲】非线性降维方法(理论篇)
【周末AI课堂 | 第六讲】线性降维方法(代码篇)
【周末AI课堂 | 第五讲】线性降维方法(理论篇)
【周末AI课堂 | 第四讲】如何进行特征选择(代码篇)
【周末AI课堂 | 第三讲】如何进行特征选择(理论篇)
【周末AI课堂 | 第二讲】过拟合问题(代码篇)
【周末AI课堂 | 第一讲】过拟合问题(理论篇)
长按识别二维码可添加关注
读芯君爱你


- 机器学习-凸优化理论-课堂笔记
- AI机器学习(四)一些简单的思考
- 本人是新手,遇到有关AI的问题,想求助大侠们
- 学习ejb并配置一个简单的helloEjb是遇到问题后总结的经验。
- 苹果又发布一个机器学习框架,帮自家生态里的开发者降低AI门槛
- 阿里云机器学习系列直播--使用变分自编码器VAE训练出深度生成模型
- 机器学习之理论篇—线性模型
- 助力AI淘金:机器学习公开数据集
- 机器学习理论决策树理论第二卷
- 教你用OpenCV实现机器学习最简单的k-NN算法
- [异常解决] ubuntu上安装虚拟机遇到的问题(vmware坑了,virtual-box简单安装,在virtual-box中安装精简版win7)
- 机器学习相似度计算方法选择理论依据
- 【机器学习】文本数据简单向量化
- 读《高效ML:理论,算法及实践》:(1) 机器学习基本概念
- 利用简单图片欺骗AI监测系统
- 机器学习理论与实验2
- 简单的AI范围检测
- 【笔记】机器学习用到的“概率论与数理统计”知识简单回顾
- 这可能是最简单易懂的机器学习入门(小白必读)
- 使用node+mongodb搭建简单个人博客——第一章遇到的问题