大白话详解大数据hive知识点,老刘真的很用心(3)

前言:老刘不敢说写的有多好,但敢保证尽量用大白话把自己复习的内容详细解释出来,拒绝资料上的生搬硬套,做到有自己的了解!
1. hive知识点(3)
从这篇文章开始决定进行一些改变,老刘在博客上主要分享大数据每个模块的重点知识点,对这些重点内容进行详细解释,每个模块的完整知识点分享在公众号:努力的老刘。等有机会了,用视频的方式先对每次分享的知识点进行一次分析和总结,再发文章进行详细的解释。
现在开始正文,还是那句话,虽然这些都是hive的常用函数,很多人不在意,但是日常开发中会遇到很多业务需要用到这些函数,我们至少要熟悉一些常用函数,肚子里有点货。
本篇文章中的explode、行转列、列转行是重点中的重点,需要熟练掌握它们的实例。由于hive偏于实操,老刘也只对这些重点知识点进行详细的讲解。
2. hive当中的lateral view与explode
为什么会用到explode?
在实际开发过程中,会遇到很多复杂的array或者map结构,我们会根据一些业务要求把这些复杂的结构从一列拆成多行,这个时候就需要用到explode。可能你仍然不是很懂,现在就直接举例说明这个explode,一定要跟着老刘一起练习。光看不练,等于白学!
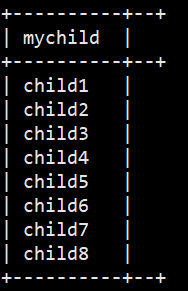
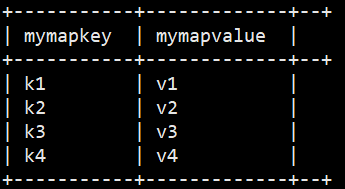
需求:现在有数据格式如下 zhangsan child1,child2,child3,child4 k1:v1,k2:v2 lisi child5,child6,child7,child8 k3:v3,k4:v4 字段之间使用\t分割,需求将所有的child进行拆开成为一列 +----------+--+ | mychild | +----------+--+ | child1 | | child2 | | child3 | | child4 | | child5 | | child6 | | child7 | | child8 | +----------+--+ 将map的key和value也进行拆开,成为如下结果 +-----------+-------------+--+ | mymapkey | mymapvalue | +-----------+-------------+--+ | k1 | v1 | | k2 | v2 | | k3 | v3 | | k4 | v4 | +-----------+-------------+--+
第一步:我们先创建数据库,并使用刚刚创建的数据库
create database hive_explode; use hive_explode;
第二步:创建完数据库后,就要开始创建hive的表
createtable hive_explode.t3(name string,children array<string>,address Map<string,string>) row format delimited fields terminated by '\t' collection items terminated by ',' map keys terminated by ':'stored as textFile;
注意注意,大家一定要看仔细咯,由于我们的需求,要创建name,这是字符串形式,但是child这块它是array形式,address是map形式,这一块老刘虽然没讲,但是这块真的很重要,根据这些复合函数里面的分隔符,我们的分割代码是这样写的:
平常的空格形式是
row format delimited fields terminated by '\t'
array里面的分割形式是
collection items terminated by ','
map里面的分割形式是
map keys terminated by ':'
这里面的区别,大家要好好记住!
第三步:加载数据
cd /kkb/install/hivedatas/ vim maparray 数据内容格式如下 zhangsan child1,child2,child3,child4 k1:v1,k2:v2 lisi child5,child6,child7,child8 k3:v3,k4:v4
然后利用hive加载数据
load data local inpath '/kkb/install/hivedatas/maparray' into table hive_explode.t3;
我们导入数据后,可以看看表里面的情况。

第四步:之前是把数据导入了表中,接下来就是对数据进行炸裂
将所有的child进行拆分成为一列
SELECT explode(children) AS myChild FROM hive_explode.t3;
接着将map的key和value也进行拆分
SELECT ex ad0 plode(address) AS (myMapKey, myMapValue) FROM hive_explode.t3;
由于lateral view 常常在行转列和列转行中使用,就不单独讲lateral view了。
3. 行转列
首先关于行转列和列转行要说的是,它们非常非常重要,会遇到很多需要进行列转换的需求。
但是呢,行转列和列转行并不是把1行转为1列和1列转为1行,很多资料对行转列和列转行都有自己的看法,常常是相反的。
老刘按照尚硅谷的来。咱们先不管这个概念,把它们的用法搞清楚即可。
行转列:就是把多个列里的数据变为1列。
用一个例子演示行转列。
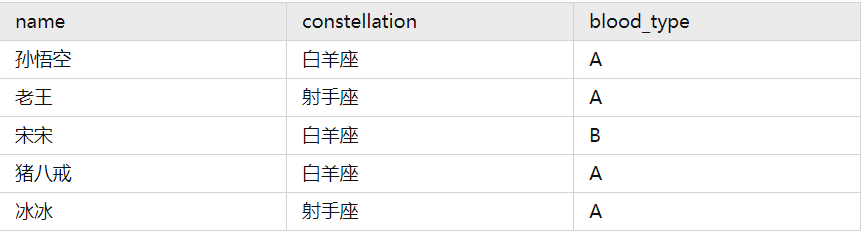
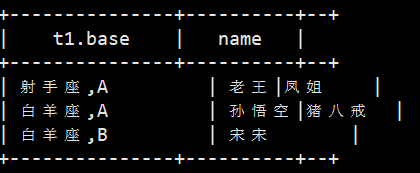
然后就是把星座和血型一样的人归类到一起,结果如下:
射手座,A 老王|冰冰 白羊座,A 孙悟空|猪八戒 白羊座,B 宋宋
这里面还涉及到concat函数,先讲一讲连接函数:
concat():返回输入字符串连接后的结果,支持任意个输入字符串;
concat_ws():这个就是把一个分隔符加到连接的字符串之间;
collect_set():将某字段进行去重汇总,产生array类型 3ba4 字段。
接下来,我们要做的就是创建表导入数据。
1、创建文件,注意数据使用\t进行分割
cd /kkb/install/hivedatas vim constellation.txt 孙悟空 白羊座 A 老王 射手座 A 宋宋 白羊座 B 猪八戒 白羊座 A 凤姐 射手座 A
2、创建hive表并加载数据
create table person_info(name string,constellation string,blood_type string) row format delimited fields terminated by "\t";
3、加载数据
load data local inpath '/kkb/install/hivedatas/constellation.txt' into table person_info;
可以查询一下导入表后的情况,select * from person_info.
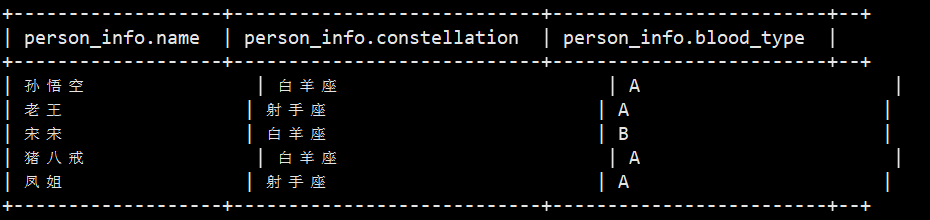
4、查询数据
注意注意,根据我们的需求,查询结果是需要进行concat_ws操作的。
select t1.base, concat_ws('|', collect_set(t1.name)) name from (select name, concat(constellation, "," , blood_type) base from person_info) t1 group by t1.base;
老刘解释一下,由于星座和血型用逗号连接,所以我们应该这样写代码
concat(constellation, "," , blood_type)
接着就是先根据星座和血型一样这个条件,查询出所有的人。
select name, concat(constellation, "," , blood_type) base from person_info
把这个临时表取名为t1,然后把查询出来的人根据需求,多行转一行。由于名字之间用 | 进行.连接的,所以我们应该这样写代码。
concat_ws('|', collect_set(t1.name))
最后的查询结果是这样的
select t1.base, concat_ws('|', collect_set(t1.name)) name from t1 group by t1.base;
4. 列转行
在列转行中,会涉及到两个非常重要的函数:explode和lateral view。
explode:将hive一列中复杂的array或者map结构拆分成多行。
lateral view:一般多用于将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
举例说明:
数据内容如下,字段之间都是使用\t进行分割
cd /kkb/install/hivedatas vim movie.txt 《疑犯追踪》 悬疑,动作,科幻,剧情 《Lie to me》 悬疑,警匪,动作,心理,剧情 《战狼2》 战争,动作,灾难
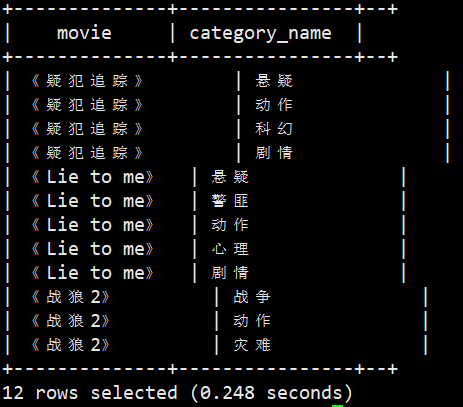
将电影分类中的数组数据展开,结果如下:
《疑犯追踪》 悬疑 《疑犯追踪》 动作 《疑犯追踪》 科幻 《疑犯追踪》 剧情 《Lie to me》 悬疑 《Lie to me》 警匪 《Lie to me》 动作 《Lie to me》 心理 《Lie to me》 剧情 《战狼2》 战争 《战狼2》 动作 《战狼2》 灾难
这就是典型的一行转为多行,使用lateral view和explode结合。
我们第一步要做的就是根据表的特征以及表里面数据的特征创建表,类别要创建为array类型。
create table movie_info(movie string, category array<string>) row format delimited fields terminated by "\t" collection items terminated by ",";
接着就是加载数据
load data local inpath "/kkb/install/hivedatas/movie.txt" into table movie_info;
最后根据需求查询表,由于类别里面是array类型,现在需要把类别利用lateral view炸开,然后就可以进行查询数据。
select movie, category_name from movie_info lateral view explode(category) table_tmp as category_name;
其中,table_tmp是表名,category_name是列名。
5. 总结
老刘主要就讲述了行转列和列转行,以及两个函数explode和lateral view,并且分别用了两个案列对他们进行了演示,大家一定要跟着案列练习一遍,光看不练,等于白学。
最后,完整的hive知识点(3)内容在公众号:努力的老刘里面。如果觉得有哪里写的不好或者有错误的地方,可以联系老刘,进行交流。希望能够对大数据开发感兴趣的同学有帮助,希望能够得到同学们的指导。
如果觉得写的不错,给老刘点个赞!
这就是典型的一行转为多行,使用lateral view和explode结合。
我们第一步要做的就是根据表的特征以及表里面数据的特征创建表,类别要创建为array类型。

- 大白话详解大数据HBase核心知识点,老刘真的很用心(3)
- 大白话详解大数据HBase核心知识点,老刘真的很用心(2)
- 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
- 016-Hadoop Hive sql语法详解6-job输入输出优化、数据剪裁、减少job数、动态分区
- 再谈Hive元数据如hive_metadata与Linux里MySQL的深入区别(图文详解)
- 详解Python数据分析--Pandas知识点
- 大数据生态系统入门必看:pig、hive、hadoop、storm、mapreduce等白话诠释
- Hadoop Hive sql语法详解--DQL 操作:数据查询SQL(4)
- C语言 数据存储方式知识点详解
- Hive表数据的导入和导出详解
- Hive最新数据操作详解(超级详细)
- 大数据Hive 面试以及知识点
- 大数据(二十三)Hive【Hive三种启动方式 、 HIVE Server2详解 、 jdbc链接HIVE】
- java核心知识点学习----多线程间的数据共享和对象独立,ThreadLocal详解
- hive-数据倾斜解决详解
- [一起学Hive]之十四-Hive的元数据表结构详解
- 大数据生态系统 - Hive详解
- hive与hbase数据交互的详解指南
- 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)