Hadoop生态圈
本章讲一下关于大数据技术hadoop,直接步入正题,在了解hadoop之前,先来说一下什么是大数据?
一.大数据
1.概述:是指无法在一定时间范围内无法用常规软件工具进行捕捉、管理和处理的数据集合,需要使用新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。主要解决海量数据的存储和分析计算问题。
2.特点(5V):
*Volume(大量):数据存储量;
*Velocity(高速):大数据区分于传统数据挖掘的最显著特征;
*Variety(多样):数据分为结构化数据和非结构化数据;
*value(低价值密度):低价值密度的高低与数据总量成反比;
*Veracity(真实性)。
3.应用场景:人工智能、保险的海量数据挖掘及风险预测、物流仓储、金融多维度体现用户特征......
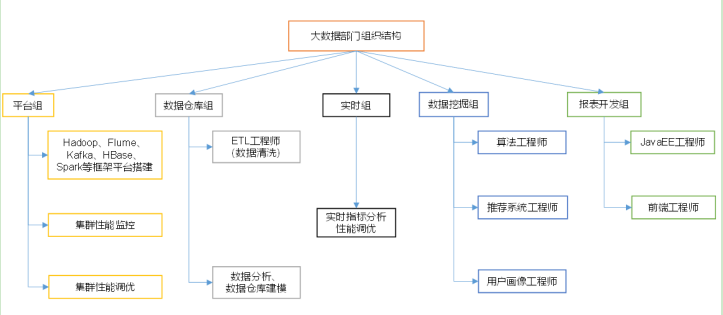
4.大数据部门组织结构:
二.Hadoop
1.概述:一个用于分布式大数据处理的开源框架,由Apache基金会所开发的分布式系统基础框架,允许使用简单的编程模型在跨计算机集群的分布式环境中存储和处理大数据。同常是指一个更广泛的概念-Hadoop生态圈。
2.Hadoop生态圈:
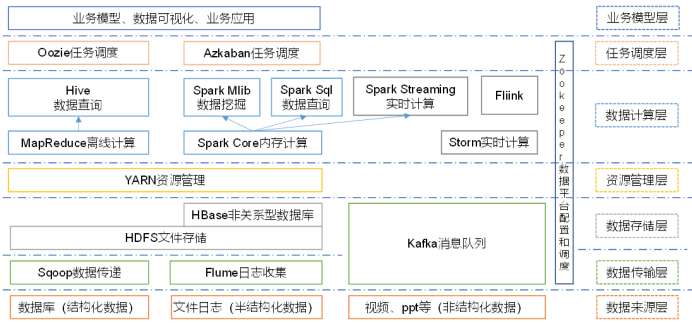
*Sqoop:一款开源工具,主要用在Hadoop、Hive与传统数据库(Mysql)间进行数据传递,可以将关系型数据库数据导入到Hadoop的HDFS中,也可以从HDFS中导入关系型数据库中;
*Flume:一个高可用、高可靠的分布式海量日志采集、聚合和传输系统,支持在日志系统中定制各类数据发送方,用于收集数据;
*Kafka:一种高吞吐量的分布式发布订阅消息系统;
*HBas ad8 e:一个建立在HDFS之上,面向列的针对性结构化数据的可伸缩、高可靠、高性能、分布式的动态数据库,保存的数据可以使用Mapreducer来处理,将数据存储和并行计算完美的结合在一起;
*Storm:对数据流做连续查询,在计算时就将结果以流动形式输出给用户,用于“连续计算”;
*Spark:一种基于内存的分布式计算框架,与Mapreducer不同的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法,内部提供了大量的库,如 Spark Sql、Spark Streaming等;
*Fiilnk:一种基于内存的分布式计算框架,用于实时计算场景较多;
*Oozie:一个管理hadoop job 的工作流程调动管理系统,用于协调多个MapReducer任务的执行;
*Hive:基于Hadoop的一个数据仓库工具,定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行。通常用于离线分析。
*Impala:用于处理存储在Hadoop集群中大量数据的MPP(大规模并行处理)SQL查询引擎,与Hive不同,不基于MapReducer算法。它实现了一个基于守护进程的分布式结构,负责在同一台机器上运行的查询执行所有方面,执行效率高于Hive。
3.三大发行版本:Apache、Cloudera、Hortonworks
4.优势:
*高可靠性:Hadoop底层维护多个数据副本,即使某个存储出现故障,也不会导致数据的丢失;
*高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点;
*高效性:hadoop是并行工作的,以加快任务处理速度;
*高容错性:能够自动将失败的任务从新分配。
5.组成:
*HDFS:分布式文件系统;
*MapReducer:分布式数据处理模型和执行环境(分布式计算);
*YARN:job调度和资源管 56c 理框架;
*Common:支持其他模块的工具模块(辅助工具)。
6.三种模式:
*单机模式:不需要配置,Hadoop被认为单独的java进程,经常用来做调试;
*伪分布式模式:可以看做只有一个节点的集群,在这个集群中,这个节点既是master,也是slave,既是namenode,也是datanode,既是jobtracker,也是tasktracker;
*完全分布式模式:Hadoop的守护进程运行在由多台主机搭建的集群上,是真正的生产环境。
后面我们会介绍到HDFS和MapReducer,期待...

- hadoop生态圈综合简介及架构案例
- 一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
- Hadoop 版本 生态圈 MapReduce模型
- 基于Hadoop生态圈的数据仓库实践 —— 环境搭建(三)
- 图画hadoop -- 生态圈
- Hadoop生态圈——Flume日志收集入门
- 小白自学搭建单机版的Hadoop生态圈(持续更新)
- 基于Hadoop生态圈的数据仓库实践 —— 进阶技术(二)
- Hadoop生态圈各软件初始化操作指南
- 学习地址 hadoop生态圈
- 一张图片看懂hadoop生态圈
- 基于Hadoop生态圈的数据仓库实践 —— 进阶技术(十一)
- 盘点Hadoop生态圈:13个让大象飞起来的开源工具
- Hadoop生态圈(一) -- 搭建伪分布式集群(二)
- 大数据之Hadoop生态圈中的MapReduce学习
- Hadoop生态圈
- 【科普杂谈】一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
- Hadoop导航:版本、生态圈及MapReduce模型
- 大数据时代之hadoop(六):hadoop 生态圈(pig,hive,hbase,ZooKeeper,Sqoop)
- 盘点Hadoop生态圈:13个让大象飞起来的开源工具