面试被问频率最高的几道Redis面试题
Redis相关面试题确实很多,主要是因为知识点很多,但是面试的时候,不可能都问个遍,所以本文就来总结一下,面试被问频率最高的几道
Redis的面试题。
请说一下Redis
支持的哪些数据类型
String(字符串)
list(列表):list 是字符串列表,按照插入顺序排序。元素可以在列表的头部(左边)或者尾部(右边)进行添加。
hash(哈希):
Redis hash
是一个键值对(key-value)集合。Redis hash
是一个 String 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。set(集合):
Redis
的 set 是 String 类型的无序集合。zset
(sorted set:有序集合):Redis zset
和 set 一样也是 String 类型元素的集合,且不允许重复的成员。不同的zset
是每个元素都会关联一个 double 类型的分数。zset
通过这个分数来为集合中所有元素进行从小到大的排序。zset
的成员是唯一的,但分数(score)却可以重复。
这个题目是不管你是初级、中级还是高级,被问到的概率很大。
Redis有哪些常见应用场景 ?
热点数据缓存:由于 Redis 访问速度块、支持的数据类型比较丰富,所以 Redis 很适合用来存储热点数据
限时业务实现:expire 命令设置 key 的生存时间,到时间后自动删除 key。收集验证码、优惠活动等业务场景。
计数器实现:incrby 命令可以实现原子性的递增,所以可以运用于高并发的秒杀活动、分布式序列号的生成。比如限制一个手机号发多少条短信、一个接口一分钟限制多少请求、一个接口一天限制调用多少次等等。
排行榜实现:借助 SortedSet 进行热点数据的排序。例如:下单量最多的用户排行榜,最热门的帖子(回复最多)等。
布式锁实现:利用 Redis 的 setnx 命令进行。后面会有详细的实现介绍。
队列机制实现:Redis 有 list push 和 list pop 这样的命令,所以能够很方便的执行队列操作。
就算你没有使用过Redis,但是你得知道,Redis的使用场景有哪些,当场景出现的时候,你就可以考虑一下能否把Redis用上,并且和其他方案进行对比。也就是相当于你多了一套方案而已。
缓存三大问题:缓存雪崩、缓存击穿、缓存穿透
缓存雪崩
什么是缓存雪崩?如果我们的缓存挂掉了,这意味着我们的全部请求都跑去数据库了(下图来源于网络)。
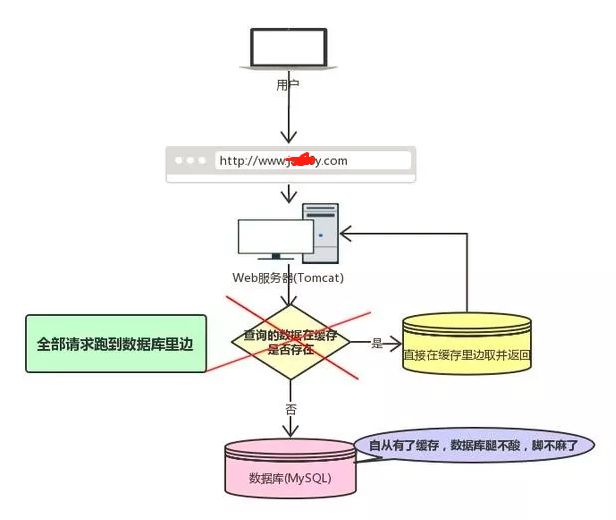
我们都知道Redis不可能把所有的数据都缓存起来(内存昂贵且有限),所以Redis需要对数据设置过期时间,并采用的是惰性删除+定期删除两种策略对过期键删除。
如果缓存数据设置的过期时间是相同的,并且Redis恰好将这部分数据全部删光了。这就会导致在这段时间内,这些缓存同时失效,全部请求到数据库中。
这就是缓存雪崩:Redis挂掉了,请求全部走数据库。
缓存雪崩如果发生了,很可能就把我们的数据库搞垮,导致整个服务瘫痪!
如何解决缓存雪崩?在缓存的时候给过期时间加上一个随机值,这样就会大幅度的减少缓存在同一时间过期。
首先强调的是缓存雪崩对底层系统的冲击非常可怕。但很遗憾的是目前并没有完美的解决方案。
场景解决方案
大多数设计者考虑“加锁”或者“队列”方式保证缓存的单线程(进程)写,从而避免大量并发请求落到底层存储系统上。比如某个Key只允许一个线程查询和写缓存,其他线程等待。
有一个简单处理方案,就是将缓存失效时间分散开,比如我们在原有失效时间上增加一个随机值,如1~5分钟随机,尽量让缓存不要同时失效,从而尽量避免缓存雪崩。
实现高可用架构,尽量避免
Redis
挂掉的情况。Redis
挂掉后采用本地缓存和限流策略,避免DB直接被干掉。Redis
持久化,Redis
挂掉后,重启后可以自动从磁盘中加载数据,能快速回复数据。
缓存击穿
什么是缓存击穿对于一些设置了过期时间的Key,当这些Key在被某些时间点大量高并发访问时,这个时候就需要考虑缓存被“击穿”的问题,这个问题和雪崩区别在于只针对某个Key的缓存,而缓存雪崩是针对多个Key的缓存。简单来说,就是当某个时间点某个Key被高并发访问,此时恰好缓存过期,那么所有请求都落到DB上了,这是瞬时的大并发就有可能导致将DB压垮,这种现象就叫缓存击穿。
如何解决缓存击穿?方案一:后台刷新
后台定义一个job(定时任务)专门主动更新缓存数据.比如,一个缓存中的数据过期时间是30分钟,那么job每隔29分钟定时刷新数据(将从数据库中查到的数据更新到缓存中).
这种方案比较容易理解,但会增加系统复杂度。比较适合那些 key 相对固定,cache 粒度较大的业务,key 比较分散的则不太适合,实现起来也比较复杂。方案二:检查更新
将缓存key的过期时间(绝对时间)一起保存到缓存中(可以拼接,可以添加新字段,可以采用单独的key保存..不管用什么方式,只要两者建立好关联关系就行).在每次执行get操作后,都将get出来的缓存过期时间与当前系统时间做一个对比,如果缓存过期时间-当前系统时间<=1分钟(自定义的一个值),则主动更新缓存.这样就能保证缓存中的数据始终是最新的(和方案一一样,让数据不过期.)
这种方案在特殊情况下也会有问题。假设缓存过期时间是12:00,而 11:59到 12:00这 1 分钟时间里恰好没有 get 请求过来,又恰好请求都在 11:30 分的时候高并发过来,那就悲剧了。这种情况比较极端,但并不是没有可能。因为“高并发”也可能是阶段性在某个时间点爆发。方案三:分级缓存
采用 L1 (一级缓存)和 L2(二级缓存) 缓存方式,L1 缓存失效时间短,L2 缓存失效时间长。请求优先从 L1 缓存获取数据,如果 L1缓存未命中则加锁,只有 1 个线程获取到锁,这个线程再从数据库中读取数据并将数据再更新到到 L1 缓存和 L2 缓存中,而其他线程依旧从 L2 缓存获取数据并返回。
这种方式,主要是通过避免缓存同时失效并结合锁机制实现。所以,当数据更新时,只能淘汰 L1 缓存,不能同时将 L1 和 L2 中的缓存同时淘汰。L2 缓存中可能会存在脏数据,需要业务能够容忍这种短时间的不一致。而且,这种方案可能会造成额外的缓存空间浪费。
方案四:加互斥锁
这种方案是通过异步方式 去获取缓存过程中,其他key 处于等待现象,必须等待第一个构建完缓存之后,释放锁,其他人才能通过该key才能访问数据;如下图所示
第一个key1 在查询db,获取数据 到放入缓存过程中,都有把锁 先锁住,其他人就必须等待,等待这个人把缓存设置成功,才去释放锁,那其他人就直接从缓存里面取数据;不会造成数据库的读写性能的缺陷;
缓存穿透
什么是缓存穿透缓存穿透是指查询一个一定不存在的数据。由于缓存不命中,并且出于容错考虑,如果从数据库查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,失去了缓存的意义。
这就是缓存穿透:
请求的数据在缓存大量不命中,导致请求走数据库。
缓存穿透如果发生了,也可能把我们的数据库搞垮,导致整个服务瘫痪!
如何解决缓存穿透?解决缓存穿透也有两种方案:
由于请求的参数是不合法的(每次都请求不存在的参数),于是我们可以使用布隆过滤器(BloomFilter)或者压缩filter提前拦截,不合法就不让这个请求到数据库层!
当我们从数据库找不到的时候,我们也将这个空对象设置到缓存里边去。下次再请求的时候,就可以从缓存里边获取了。
这种情况我们一般会将空对象设置一个较短的过期时间。
以上说的三种情况,就是缓存最容易出现的问题,所以你得知道,每个场景然后其场景的解决方案有哪些。
说一下Redis的持久化有哪些方式?
Redis的持久化有两种方式:RDB和AOF
RDB 持久化:原理是将 Reids 在内存中的数据库记录定时 dump 到磁盘上的 RDB 持久化。
AOF(append only file)持久化:原理是将 Redis 的操作日志以追加的方式写入文件。
继续说一下他们各自的区别及优缺点
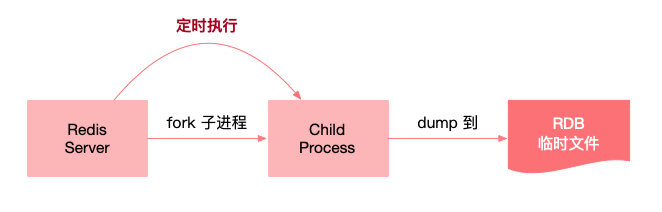
两者的区别RDB 持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,创建RDB文件有两种命令的方式,Save与BGSAVE,其中Save命令会阻塞redis服务器进程。导致这段期间服务器不能接受客户端的请求,BGSAVE命令会创建子进程来执行RDB文件的创建。所以BGSAVE不会阻塞服务器进程。BGSAVE实际操作过程是 fork 一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
默认为RDB方式持久化。
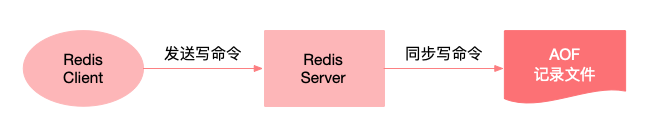
AOF 持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
RDB
优点
RDB 是紧凑的二进制文件,比较适合备份,全量复制等场景
RDB 恢复数据远快于 AOF
缺点
RDB 无法实现实时或者秒级持久化;
新老版本无法兼容
RDB
格式。
AOF
优点
可以更好地保护数据不丢失;
appen-only
模式写入性能比较高;适合做灾难性的误删除紧急恢复。
缺点:
对于同一份文件,AOF 文件要比 RDB 快照大;
AOF 开启后,会对写的 QPS 有所影响,相对于 RDB 来说 写 QPS 要下降;
数据库恢复比较慢, 不合适做冷备。
其实基本上都不会是单独使用每一种类解决持久化的。因为都存在问题。
Redis 淘汰策略有哪些?(内存满了怎么办)
Redis 可以看作是一个内存数据库,通过 Maxmemory 指令配置 Redis 的数据集使用指定量的内存。设置 Maxmemory 为 0,则表示无限制。
当内存使用达到 Maxmemory 极限时,需要使用某种淘汰算法来决定清理掉哪些数据,以保证新数据的存入。
Redis 的缓存淘汰策略有:
noeviction
:当内存使用达到上限,所有需要申请内存的命令都会异常报错。allkeys-lru
:先试图移除一部分最近未使用的 key。volatile-lru:淘汰一部分最近使用较少的(LRC),但只限于过期设置键。
allkeys-random:随机淘汰某一个键。
volatile-random:淘汰任意键,但只限于有过期设置的驱逐键。
volatile-ttl:优先移除具有更早失效时间的 key。
Redis内存满了,一般采用三种方式
增加内存(治根不治本,土豪另说)。
使用内存淘汰策略
Redis
集群
Redis 为什么设计成单线程的?
单线程,这里的单线程指的是 Redis 网络请求模块使用了一个线程(所以不需考虑并发安全性),即一个线程处理所有网络请求,其他模块仍用了多个线程。
Redis 为什么设计成单线程的?
绝大部分请求是纯粹的内存操作(非常快速)
采用单线程,避免了不必要的上下文切换和竞争条件
非阻塞 IO,内部采用 epoll,epoll 中的读、写、关闭、连接都转化成了事件,然后利用 epoll 的多路复用特性,避免 IO 代价。
为何单线程的 Redis 却能支撑高并发?
Redis 集群架构模式有哪几种?
Redis 单节点单机器部署
Redis 主从节点部署
Redis Sentinel(哨兵)模式部署
Redis 集群模式
说说Redis每种集群模式的优缺点
使用Redis 怎么实现分布式锁?
简单方案:
最简单的方法是使用 setnx 命令,set not exist 设置不存在key。释放锁的最简单方式是执行 del 指令。
问题:
锁超时:如果一个得到锁的线程在执行任务的过程中挂掉,来不及显式地释放锁,这块资源将会永远被锁住(死锁),别的线程再也别想进来。
优化方案:
setnx 没办法设置超时时间,如果利用 expire来设置超时时间,那么这两步操作不是原子性操作。设置过期时间是避免锁一直不释放或者释放失败的问题。
利用 set 指令增加了可选参数方式来替代 setnx。set 指令可以设置超时时间。
一种Redis实现分布式锁

- 熟悉这几道 Redis 高频面试题,面试不用愁
- 熟悉这几道 Redis 高频面试题,面试不用愁
- C++面试出现频率最高的面试题
- 面试几率最高的35个Redis面试题总结
- 面试前必知Redis面试题—缓存雪崩+穿透+缓存与数据库双写一致问题
- 11个提问频率最高的PHP面试题
- 面试前必须要知道的21道Redis面试题
- 数据分析 面试题解答:如何从10亿查询词找出出现频率最高的10个?
- [面试题]海量数据处理-从10亿个数中找频率最高的1000个数
- 面试还搞不懂redis,快看看这40道面试题(含答案和思维导图)
- C++面试出现频率最高的30道题目(二)
- 阿里电话面试问题----100万个URL如何找到出现频率最高的前100个?
- 11个提问频率最高的PHP面试题
- 11个提问频率最高的PHP面试题
- H面试程序(19): 统计出现频率的最高的K的字符串
- redis高频率被面试问到的内容
- 这几道Redis面试题都不懂,怎么拿到阿里后端offer?
- PHP中提问频率最高的11个面试题和答案
- C++面试出现频率最高的30道题目(三)
- 用友面试时出的几道面试题