深度学习在摄影技术上的发展_深度学习:发展最快的技术。 在世界上
深度学习在摄影技术上的发展
Have you ever wondered how cars drive by themselves? Have you ever wondered how Siri / Cortana respond to your commands sarcastically sometimes? Well, all these benchmark applications have a core algorithm embedded in their systems which are trained by human behaviour. Those who are familiar with the term “Artificial Intelligence” will say that the algorithms driving these benchmark applications are “Machine Learning” algorithms and particularly “Deep Learning” algorithms. But, whenever I hear the term Deep Learning, the image of a neural network pops up in my mind. But have you ever wondered how these clever networks learn? How these networks are built? Or, even, how does it all make sense to any of us?
您是否想过汽车如何自行驾驶? 您是否曾经想过Siri / Cortana有时会讽刺地响应您的命令? 好吧,所有这些基准测试应用程序都在其系统中嵌入了一种核心算法,该算法由人类行为进行训练。 那些熟悉“人工智能”一词的人会说,驱动这些基准测试应用程序的算法是“机器学习”算法,尤其是“深度学习”算法。 但是,每当我听到“深度学习”一词时,脑海中就会浮现出神经网络的图像。 但是您是否想知道这些聪明的网络如何学习? 这些网络是如何建立的? 甚至,这对我们每个人都有什么意义?
In this blog, I am going to give you a little tour of the world of Neural Networks, how they work and what they are made up of. So hold on till the end to get the utmost experience of this world.
在此博客中,我将向您简要介绍神经网络的世界,它们的工作原理和组成。 因此,坚持到底,以获得这个世界的最大体验。
Table of Contents:
目录:
· Perceptron and its resemblance with Human Neurons
·感知器及其与人类神经元的相似之处
· A Peek inside Perceptrons
·窥视感知器
· The major fault with Perceptrons( First AI Winter )
·Perceptrons的主要缺点(第一个AI Winter)
· Backpropagation: Algorithm that drives the learning of a multi- layer neural network architecture
·反向传播:驱动多层神经网络体系结构学习的算法
· Sigmoid neurons
·乙状神经元
· How multi-layered architectures work?
·多层体系结构如何工作?
· Types of Neural Network Architectures
·神经网络架构的类型
· Why Artificial Neural Networks have received a boom in the recent years?
·近年来,为什么人工神经网络Swift兴起?
· Recent advancements
·最新进展
感知器及其与人类神经元的相似性 (Perceptron and its resemblance with Human Neurons)
Human Beings are the most intelligent creatures in the Universe(as far as I know). So, instead of creating learning algorithms from scratch, it would be nice to know what algorithm works inside the human brain which gives us so much learning power. If we can figure out what algorithm works inside the brain, we can then mimic it to create a program which can Learn, Walk, Talk, Reproduce by itself and be aware of its own existence. Well, those were some heavy words but this is what humans have been trying to do from the last century.
人类是宇宙中最聪明的生物(据我所知)。 因此,与其从头创建学习算法,不如知道哪种算法在人脑内部起作用,这将给我们带来如此多的学习能力,这将是一个很好的选择。 如果我们能弄清楚哪种算法在大脑内部起作用,那么我们就可以模仿它来创建一个程序,该程序可以自己学习,走路,说话,复制并意识到自己的存在。 好吧,这些话有些沉重,但这是人类自上个世纪以来一直在尝试做的事情。
Our Nervous System is made up of cells known as neurons. These neurons are the core building blocks of the learning algorithm that works in our brain all the time. So, people have been trying hard to see if we can mimic a neuron and build a computer program which can learn on its own. These neurons are called Artificial Neurons.
我们的神经系统由称为神经元的细胞组成。 这些神经元是始终在我们的大脑中起作用的学习算法的核心组成部分。 因此,人们一直在努力查看我们是否可以模仿神经元,并构建可以自行学习的计算机程序。 这些神经元称为人工神经元。
The first Artificial Neuron was invented by Frank Rosenblatt in 1958 and is called Perceptron. Before diving into perceptron, let’s see how our own human neurons look like.
第一个人工神经元是弗兰克·罗森布拉特(Frank Rosenblatt)于1958年发明的,被称为Perceptron。 在深入研究感知器之前,让我们看看我们自己的人类神经元的样子。
窥视器内部 (A Peek inside Perceptron)
 Human Neuron 人类神经元
Human Neuron 人类神经元 This is what a human neuron looks like. Well, I am not a biologist to explain every part of it but I do know how it works. This cell has a cell body, dendrites and axon terminals. The dendrites are the little connections that help this neuron connect and receive information from other neurons. These dendrites are in millions for a single neuron. Then, according to the information received from the neighbouring neurons, an electrochemical reaction takes place in the cell body and the neuron goes either to its active state or its inactive state thereby firing neurotransmitters from the axons (Please do forgive me if I have written something wrong in the above explanation).
这就是人类神经元的样子。 好吧,我不是生物学家来解释它的每个部分,但我确实知道它是如何工作的。 该细胞具有细胞体,树突和轴突末端。 树突是帮助该神经元连接并从其他神经元接收信息的小连接。 对于单个神经元,这些树突以百万计。 然后,根据从邻近神经元接收到的信息,细胞体内发生电化学React,神经元进入活跃状态或非活跃状态,从而从轴突发射神经递质(如果我写了一些东西,请原谅我以上说明中有误)。
Computer Scientists have tried hard to mimic this neuron and Frank Rosenblatt came up with structure of Perceptron which resembled similar behaviour.
计算机科学家努力模拟这种神经元,弗兰克·罗森布拉特(Frank Rosenblatt)提出了类似行为的感知器结构。

This perceptron is just a simple mathematical function which takes its inputs x1, x2 and x3 and gives back an output y which is either 0 or 1 representing the fact that the neuron is active or not (Similar to the human ones). But we do see w1, w2 and w3 in the picture. What are these? These are the weights of the perceptron. But wait, Weights? What do we need them for?
该感知器只是一个简单的数学函数,其输入x1,x2和x3并返回输出y,该输出y为0或1,表示神经元是否活跃(与人类类似)。 但是我们确实在图片中看到了w1,w2和w3。 这些是什么? 这些是感知器的重量。 但是等等,权重? 我们需要它们做什么?
Well, human neuron dendrides have changing size, they can either become thick (indicating strong connection with its neighbour) or thin (indicating weak connection with its neighbour). To mimic this behaviour, Rosenblatt came up with the idea of weights.
好吧,人类神经元树突的大小不断变化,它们要么变厚(表明与邻居的牢固连接),要么变薄(表明与其邻居的弱连接)。 为了模仿这种行为,Rosenblatt提出了举重的想法。
Many people get scared and uninterested when they see maths in the story but, trust me, the calculation is very very simple.
许多人在看到故事中的数学时都会感到害怕和不感兴趣,但是,请相信我,计算非常简单。
We discussed that perceptron is just a mathematical function whose Inputs are x1, x2 and x3(for this case) and output is either 0 or 1 and it has some weights.
我们讨论过,感知器只是一个数学函数,其输入为x1,x2和x3(在这种情况下),输出为0或1,并且具有一定的权重。
The inputs are multiplied with their corresponding weights and are added up. Now, if this addition results in a sum greater than a Threshold value, the output is 1 otherwise 0.
输入乘以其相应的权重并相加。 现在,如果此加法运算得出的总和大于阈值,则输出为1,否则为0。
The function is mathematically written as:
该函数在数学上写为:

But, the way a perceptron learned was not a good one. We had to manually tweak the weights and Threshold in order to get the right outputs for the right inputs. Of course we could add more inputs and weights in the perceptron( say there are 100 inputs), but in doing so we are troubling ourselves because we have to tweak the 100 weights manually which becomes very hectic very quickly.
但是,感知器学习的方法不是一个好方法。 我们必须手动调整权重和阈值,以便获得正确输入的正确输出。 当然,我们可以在感知器中添加更多的输入和权重(比如说有100个输入),但是这样做会给自己造成麻烦,因为我们必须手动调整100个权重,这很快就会变得非常忙碌。
感知器中的错误 (The fault in Perceptron)

The major fault in perceptron was picked up by Marvin Minskey in 1969. He said that Perceptron was very good in picking up linear data but it cannot approximate the XOR function which means perceptron cannot capture non-linear relationships.
感知器的主要故障是由Marvin Minskey在1969年发现的。他说,感知器在拾取线性数据方面非常出色,但不能近似XOR函数,这意味着感知器无法捕获非线性关系。

This was a heart-breaking moment for Artificial Intelligence and was called the “First AI winter”. The interest of researchers in the field of AI went down and AI went to sleep for 10 years.
这是人工智能令人心碎的时刻,被称为“第一个AI冬季”。 人工智能领域的研究人员的兴趣下降了,人工智能入睡了10年。

Of course, if multiple perceptrons could be stacked together in a layered architecture, they could capture the non-linearity. In fact, given enough number of layers in the multi-layer perceptron architecture, it could generalize to any function. This is called “The Universal Approximation Theorem”. But multiple layers would mean hundreds of weights and tweaking all of them to get better results was a pain in the a**. This is why the interest of researchers in the field of AI went down.
当然,如果多个感知器可以分层结构堆叠在一起,则它们可以捕获非线性。 实际上,给定多层感知器体系结构中足够的层数,它可以推广到任何功能。 这称为“ 通用近似定理 ”。 但是多层将意味着数百个砝码,并且对所有这些砝码进行调整以获得更好的效果是一个痛苦。 这就是为什么AI领域的研究人员的兴趣下降的原因。
反向传播:驱动NNet体系结构学习的算法 (Backpropagation: Algorithm that drives the learning of a NNet Architecture)
In 1986, Geoffrey Hinton published a paper “Learning internal representations by error propagation” which was a landmark in the field of AI and this marked the end of the “First AI Winter”. His paper included this algorithm called Backpropagation.
1986年,Geoffrey Hinton发表了一篇论文“通过错误传播学习内部表示”,这是AI领域的一个里程碑,标志着“第一个AI冬季”的结束。 他的论文包括称为反向传播的算法。
Through this algorithm, neural networks could be trained in better way instead of tweaking hundreds of weigths randomly and manually. We now had a systematic approach to the training process. This algorithm raised the interest of researchers in the field of AI and people started working on it again.
通过这种算法,可以更好地训练神经网络,而不是随机地和手动地调整数百个体重。 现在,我们对培训过程采取了系统的方法。 该算法引起了AI领域研究人员的兴趣,人们开始重新研究它。
乙状神经元 (Sigmoid Neurons)
Now-a-days, the concept of perceptrons are considered to be obsolete because they are replaced by another advanced type of Neuron called the Sigmoid Neurons.
如今,感知器的概念已经过时,因为它们已被称为Sigmoid Neurons的另一种高级神经元所取代。
Recall that the perceptrons activated only when the weighted sum of inputs passed a certain threshold. The case was different with sigmoid neurons. There was no need of any threshold in the case of sigmoid neurons. Why?
回想一下,只有在输入的加权总和超过某个阈值时,感知器才会激活。 乙状结肠神经元的情况不同。 乙状结肠神经元不需要任何阈值。 为什么?
The weighted sum of inputs was passed to an activation function called the sigmoid squishification function which could squeeze the real number line between 0 and 1. Take a look at the diagram below for better visual representation.
输入的加权总和被传递到称为S形压缩函数的激活函数,该函数可以压缩0到1之间的实数线。请查看下面的图以获得更好的视觉表示。
 Courtesy: 3Blue1Brown 礼貌:3Blue1Brown
Courtesy: 3Blue1Brown 礼貌:3Blue1Brown This means if you passed any real number in the sigmoid function, it would give you an answer between 0 and 1.
这意味着,如果在Sigmoid函数中传递了任何实数,则将给出0到1之间的答案。
 Courtesy: 3Blue1Brown 礼貌:3Blue1Brown
Courtesy: 3Blue1Brown 礼貌:3Blue1Brown This was helpful because each sigmoid neuron could give you a number like 0.7 which could represent a probability instead of saying 1(YES) or Zero(NO) (in the case of perceptrons).
这很有用,因为每个S型神经元都可以给您一个像0.7这样的数字,它可以表示一个概率,而不是说1(是)或零(否)(对于感知器而言)。
Other Activation functions
其他激活功能
Of course, sigmoid was not the only activation function. Other functions like tanh() and relu() also caught the market.
当然, 乙状结肠不是唯一的激活功能。 tanh ()和relu ()等其他函数也吸引了市场。
By the way, Relu() is the mostly used activation in the world now because it does not saturate like sigmoid and tanh neurons(advanced topic when you dive deep into these activation functions.)
顺便说一下, Relu ()是当今世界上使用最广泛的激活方法,因为它不会像乙状结肠和tanh神经元那样饱和(当您深入研究这些激活功能时,这是高级主题。)

So, Multi-Layered Architectures with Sigmoid neurons and their learning guided through Backpropagation helps Neural Networks learn very very sophisticated things which normal Machine Learning algorithms cannot capture.
因此,具有Sigmoid神经元的 多层体系结构及其通过反向传播进行学习的指导可帮助神经网络学习非常复杂的事物,而这是普通机器学习算法无法捕获的。
多层体系结构如何工作? (How Multi-Layered Architectures work?)
In classical Machine Learning, the data scientist has to find the relationship between the target column and each feature by himself. For example, in the “Titanic” dataset, we had to work with all the columns and ultimately found out that “Embarked” column was not helping us at all in predicting whether a passenger would survive or not. But in a Deep Learning model, we do not have to check anything. We just push everything to the Neural Network and the Network, by itself, finds out the relationship between features and target. But how does it do it?
在经典机器学习中,数据科学家必须亲自找到目标列与每个功能之间的关系。 例如,在“泰坦尼克号”数据集中,我们必须处理所有列,最终发现,“停运”列根本无法帮助我们预测乘客是否能够生存。 但是在深度学习模型中,我们无需检查任何内容。 我们只是将所有内容推送到神经网络,而网络本身会发现特征与目标之间的关系。 但是它是如何做到的呢?
Well, Neural Networks are the deepest mysteries of the universe that are ever known. These are Black Boxes which cannot be understood accurately. Nobody ever knows what goes on inside a network. We can identify the input features that are causing a group of neurons to fire but we can never identify what pattern that group of neurons is really capturing.
嗯,神经网络是迄今为止已知的最深奥的奥秘。 这些是无法准确理解的黑匣子。 没人知道网络内部发生了什么。 我们可以确定导致一组神经元触发的输入特征,但我们永远无法确定该组神经元实际上捕获的模式。
But from the intuition that is developed by AI researchers over the years, we can say that the Hidden Layers of the network are responsible for guiding the network to pickup different patterns of the dataset.
但是根据AI研究人员多年来的直觉,我们可以说网络的隐藏层负责引导网络拾取数据集的不同模式。

For example, if the above network was to identify a handwritten digit, we could think that the first hidden layer could identify edges and patterns like these.
例如,如果上述网络是要识别一个手写数字,我们可以认为第一个隐藏层可以识别这些边缘和图案。

The second layer could be thought to combine these lowest level features to some higher level features like identifying loops and curves.
可以认为第二层将这些最低级别的功能与某些较高级别的功能(如识别环路和曲线)组合在一起。

The Third Hidden layer could be thought to piece together the loops and patterns to get the representation of the number itself and the final output layer would give us the number associated with the handwritten digit.
可以认为“第三隐藏”层将循环和模式拼凑在一起,以获得数字本身的表示形式,最后的输出层将为我们提供与手写数字关联的数字。
But these are just intuitions and we really don’t know if these are even true or not. These just help us to grasp onto something which helps us understand these things.
但这只是直觉,我们真的不知道这些说法是否正确。 这些只是帮助我们掌握一些有助于我们理解这些东西的东西。
神经网络架构的类型: (Types of Neural Network Architectures:)
Dense Network
密集网络
Till now we have been seeing multi-layered architectures where every neuron of a layer was connected to every neuron of the previous and the next layer. Therefore, these are called Dense Networks. The drawback of these networks is that they are computationally very expensive to train. That is the reason people had to come up with newer architectures. There is also another network called Sparse Network where only limited number of connections are allowed between layers.
到目前为止,我们已经看到了多层体系结构,其中一层的每个神经元都连接到上一层和下一层的每个神经元。 因此,这些被称为密集网络 。 这些网络的缺点是训练它们在计算上非常昂贵。 这就是人们不得不提出新架构的原因。 还有另一个称为稀疏网络的网络 ,其中各层之间仅允许有限数量的连接。

Convolutional Neural Networks (CNNs)
卷积神经网络(CNN)

If we want to do image recognition, we have to pass every pixel value of that image to our network. In case we were using a Dense network, we would have to have 2,073,600 input neurons for an image of resolution 1920x1080. This is huge and computationally very very expensive to train a Dense network like this. What is the solution then?
如果要进行图像识别,则必须将该图像的每个像素值传递给我们的网络。 如果使用的是密集网络,则必须具有2,073,600个输入神经元才能获得分辨率为1920x1080的图像。 训练像这样的密集网络非常庞大,计算上非常非常昂贵。 那有什么解决办法呢?
People analysed the visual cortex of Cats and came up with this new architecture called the Convolutional Neural Network. These convolutional layers are very helpful in identifying patterns in an image and are widely used in Image Recognition. These convolutional layers are very easy to train and can reduce the size of the image which can then be passed to Dense layers for further identification.
人们分析了猫的视觉皮层,并提出了一种称为卷积神经网络的新架构。 这些卷积层对于识别图像中的图案非常有帮助,并广泛用于图像识别中。 这些卷积层非常容易训练,并且可以减小图像的大小,然后可以将其传递给密集层以进行进一步的识别。
Recurrent Neural Networks (RNNs)
递归神经网络(RNN)
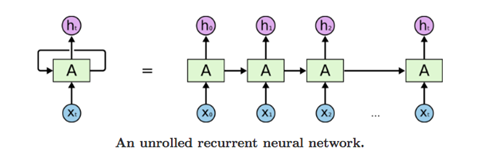
Till now we have been using Feed Forward networks. Feed Forward means information would flow from the input layer to the output layer. But RNNs work a little differently. RNNs are these networks where information can be passed back like a loop.
到目前为止,我们一直在使用前馈网络。 前馈意味着信息将从输入层流向输出层。 但是RNN的工作方式略有不同。 RNN是可以像循环一样传递信息的这些网络。

How is this useful? These can be used to retain a context of a speech. Take this example for help.
这有什么用? 这些可以用于保留语音上下文。 以这个例子为例。
“I live in France. I speak fluent _______”
“我住在法国。 我说流利_______”
If our network was to predict the last word in the sentence, then our neural network could retain the context that the person belongs to France and since the last word should be a language that he speaks, the last word can be French.
如果我们的网络要预测句子中的最后一个单词,那么我们的神经网络可以保留该人属于法国的上下文,并且由于最后一个单词应该是他所说的语言,所以最后一个单词可以是法语。
RNNs are kind of old school these days and newer variants like LSTMs and GRUs are more frequently used in these days.
RNNs是那种老派的这些天,像LSTMs和灰鹤在这些日子里更频繁地使用新的变种。
These context retaining networks are used widely in Speech Recognition, Text Generation and many more. And these networks are responsible for those sarcastic answers that Siri / Google Home gives you.
这些上下文保留网络广泛用于语音识别,文本生成等等。 这些网络负责Siri / Google Home为您提供的那些讽刺答案。
自动编码器和解码器 (Auto-Encoders and Decoders)
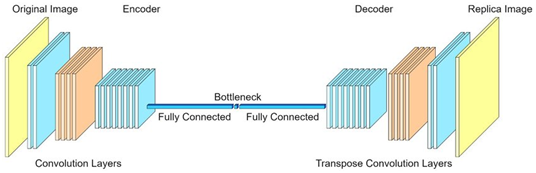
Auto encoders and decoders are another type of neural networks which are not so famous but are useful. These networks are very useful in Noise Reduction, Image compression, Dimensionality Reduction and many more.
自动编码器和解码器是神经网络的另一种类型,虽然不那么出名,但却很有用。 这些网络在降噪,图像压缩,降维等方面非常有用。
For Example, this network can be used for watermark removal:
例如,此网络可用于去除水印:

Noise Reduction:
降噪:

Colouring Black and White Movies and so on:
为黑白电影着色等:

General Adversarial Networks (GANs)
通用对抗网络(GAN)

GANs are these beautiful neural networks which are used to master unsupervised Machine Learning. For example take a look at the pictures below:
GAN是这些美丽的神经网络,用于掌握无监督的机器学习。 例如看下面的图片:

You might be surprised to know that none of these people exist in the real world. These are images all generated by GANs. Such detail, right! How does it work?
您可能会惊讶地发现,在现实世界中没有这些人。 这些都是由GAN生成的图像。 这样的细节,对! 它是如何工作的?
I am not going to go deep into the working of the network but I can give you a little overview.
我不会深入研究网络的工作,但是我可以给您一些概述。
There are two parts to this network:
此网络有两个部分:
1. Generator, and 2. Discriminator
1.生成器和2.鉴别器
The responsibility of the Generator is to generate images and the responsibility of the Discriminator is to identify whether the generated image is a real or a fake one. When the Generator network will be able fool the Discriminator by its fake images, the Generator is then ready to generate images that look completely humane.
生成器的责任是生成图像,鉴别器的责任是识别生成的图像是真实的还是伪造的。 当生成器网络能够通过其伪造图像欺骗鉴别器时,生成器便准备生成看上去完全人性化的图像。
为什么近年来人工神经网络Swift兴起? (Why Artificial Neural Networks have received a boom in the recent years?)
Neural networks are old technology. Old technology in the sense that most of the architectures were researched in the 20th century but what is the reason that these have boomed up so much from the last decade? Well, there are many reasons but I will give you 2 of them.
神经网络是旧技术。 从某种意义上说,大多数技术都是在20世纪进行研究的,但是从过去的10年以来,如此之快的繁荣是什么呢? 好吧,有很多原因,但我会给你两个。
1. Availability of Labelled Datasets: Neural Networks are hungry for data. We need large datasets to train these networks to reach humane level performance. But in the 20th century, it was very hard to find labelled data. So, the researchers themselves had to construct the dataset on their own which was very difficult.
1.标记数据集的可用性 :神经网络渴望获得数据。 我们需要大型数据集来训练这些网络以达到人性化的性能。 但是在20世纪,很难找到带有标签的数据。 因此,研究人员自己必须自己构建数据集,这非常困难。
With the advent of Internet, the availability increased and massive giants like Google, Facebook are producing enough labelled data to work with.
随着Internet的出现,可用性越来越高,Google,Facebook等庞大的巨头正在产生足够的带有标签的数据来使用。
2. Hardware Speeds: We all know that computers were not powerful enough in the 20th century to train complex neural networks. But with the advent of complex and accelerated hardware, the training time is very very less now compared to those of 20th century.
2.硬件速度:我们都知道计算机在20世纪还不够强大,无法训练复杂的神经网络。 但是随着复杂且加速的硬件的出现,与20世纪相比,现在的培训时间已经非常少了。
In fact, the competition which pushed Deep Learning to its current level is the ImageNet competition of 2012. The winner of the competition used 2 GPUs to train their neural network for 12 days to receive 16% error rate which was a landmark in the field of Neural Networks. Guess who this winner was! Geoffrey Hinton. Sounds familiar? This is the guy who brought backpropagation into light in 1986 otherwise Deep Learning would not have been at this height today.
实际上,将深度学习提升到目前水平的竞赛是2012年的ImageNet竞赛。竞赛的获胜者使用2个GPU训练他们的神经网络12天,从而获得16%的错误率,这是该领域的一个里程碑。神经网络。 猜猜谁是赢家! 杰弗里·欣顿(Geoffrey Hinton)。 听起来很熟悉? 这是在1986年使反向传播成为现实的家伙,否则,深度学习今天不会达到这个高度。
最新进展 (Recent advancements)
I have talked enough about the old technologies. Let’s see some recent advancements in this field.
我已经足够谈论旧技术了。 让我们看看该领域的一些最新进展。
Self-Driving Cars
无人驾驶汽车

Google had started working with Self-driving cars from 2015 and other companies like Tesla joined to make their own self driving cars. Today, almost every company is working on this technology.
Google从2015年开始使用自动驾驶汽车,特斯拉(Tesla)等其他公司也开始生产自己的自动驾驶汽车。 今天,几乎每个公司都在研究这项技术。
Realtime Object Detection
实时物体检测

YOLO (You Only Look Once) is another Neural Network which performs realtime object detection in an image. It can identify cars, people, and other 1000 classes of objects.
YOLO(您只看一次)是另一个神经网络,可在图像中执行实时对象检测。 它可以识别汽车,人和其他1000类对象。
Speech Recognition
语音识别

I have mentioned Google Home, Siri, Cortana many times in this blog. The core Speech Recognition algorithm is another benchmark in this field. These recognition systems are getting better and better now-a-days. It can identify your voice despite the noise in the background which is so cool.
我在此博客中多次提到Google Home,Siri,Cortana。 核心语音识别算法是该领域的另一个基准。 这些识别系统现在越来越好。 尽管背景杂音非常酷,它仍可以识别您的声音。
Video to Video Synthesis
视频到视频合成

This technology is being used by NVIDIA to create simulation environments for games which look completely real. Very excited to see this tech. working!
NVIDIA正在使用这项技术来为看起来完全真实的游戏创建模拟环境。 看到这项技术感到非常兴奋。 加工!
Reinforcement Learning
强化学习

Though I have not talked about Reinforcement Learning at all, it is very important to know the amazing advancements in this field too.
尽管我根本没有谈论强化学习,但是了解这一领域的惊人进步也非常重要。
In 2016, Google’s Deepmind created an AI called ALPHAGO which could play the ancient game of GO (popular in China, Korea and Japan). The amazing thing about ALPHAGO is that it defeated the World Champion Lee Sedol from Korea in 2016 which is considered to be a benchmark in the field of AI.
在2016年,Google的Deepmind创建了一个名为ALPHAGO的AI,可以玩古老的GO游戏(在中国,韩国和日本很受欢迎)。 关于ALPHAGO的惊人之处在于,它在2016年击败了韩国的世界冠军Lee Sedol,这被认为是AI领域的基准。
So, what is the future?
那么,未来是什么?
Well, we don’t really know yet. Some people think that “AI will overtake humans”. Seeing the performance of ALPHAGO, one might say that the above sentence seems somewhat true but the reality is Superintelligence is decades away.
好吧,我们还真的不知道。 有人认为“人工智能将超越人类”。 看到ALPHAGO的性能,也许有人会说上面的句子似乎有些正确,但事实是超级智能还需要数十年。
But the way that Deep Learning is evolving, it seems we might see this technology embedded in every corner of the world in a couple of years. You never know. Let’s say after 10 years you are entering your house and your AI companion (like Jarvis) is giving you a little present because of the care that you have given to him.
但是,随着深度学习的发展,似乎我们可能会在几年内看到该技术嵌入世界的每个角落。 你永远不会知道。 假设10年后您进入家中,而AI伙伴(如Jarvis)由于您给予他的照顾而给了您一点礼物。
Thank you for staying along this far. I hope I was able to give you a good adventure of the world of Deep Learning and Neural Networks which will motivate you to join this field with me.
感谢您一直以来的努力。 我希望我能够给您带来深度学习和神经网络世界的美好冒险,这将激发您与我一起加入这一领域。
· Powered by Campus{X} Mentorship Programme( Program Head: Nitish Singh )
·由Campus {X}指导计划提供支持 (计划负责人:Nitish Singh)
· Book by Michael Neilson on “Neural Networks and Deep Learning”
·迈克尔·尼尔森(Michael Neilson)撰写的有关“神经网络和深度学习”的书
· Youtube Playlist of 3Blue1Brown on Neural Networks
· 神经网络上3Blue1Brown的Youtube播放列表
翻译自: https://medium.com/@rajtilakls2510/deep-learning-the-fastest-growing-tech-in-the-world-6cd2636a68bf
深度学习在摄影技术上的发展

- 深度学习在摄影技术中的应用与发展
- 【深度学习大讲堂】首期第一讲:人工智能的ABCDE 第二部分:简谈当前AI技术与发展趋势...
- 【深度学习】中科院计算所:潘汀——深度学习框架设计中的关键技术及发展趋
- 转:深度 | 深度学习与神经网络全局概览:核心技术的发展历程
- 深度学习tracking学习笔记(2):图像/视觉显著性检测技术发展情况梳理(Saliency Detection、Visual Attention)
- 这里是纯干货!2018年深度学习的10个发展预测 | 技术
- 【AI技术生态论】微信Plato高性能计算负责人于东海:图计算框架与深度学习结合、GNN是图计算框架的发展方向
- 深度学习与神经网络全局概览:核心技术的发展历程
- 阿里新突破!自主创新的下一代匹配&推荐技术:任意深度学习+树状全库检索
- 深度学习框架技术解析及caffe实战一些总结
- 从特征描述符到深度学习:计算机视觉发展20年
- 杂文散谈:关于三维视觉与深度学习的发展未来
- C#2.0锐利体验之杂项技术及未来发展学习笔记
- 深度学习之四大经典CNN技术浅析
- 深度学习目标检测历史发展
- 学习笔记(06):深度学习之图像识别 核心技术与案例实战-分割数据
- 【深度学习】深度学习和神经网络这项技术
- 使用深度学习技术的图像语义分割最新综述
- 基于haar+adaboost的人脸检测、深度学习的人脸识别技术应用综述
- 腾讯云机器学习平台技术负责人:揭秘深度学习平台DI-X背后的秘密