电信客户流失数据分析
研究背景
用户流失率的下降能够提高公司利润,了解用户倾向有利于提高用户黏性,延长用户生命周期。面对如今高昂的获客成本,也可以相对地降低营销投入,做到精准营销。
提出问题
1、流失客户有哪些显著性特征?
2、尝试找到合适的模型预测流失用户
3、针对性给出增加用户黏性、预防流失的建议
数据集描述
数据集来自DataFountain,该数据集有21个变量,7043个数据点,每条记录包含了唯一客户的特征。
用户属性
customerID :用户ID。
gender:性别。(Female & Male)
SeniorCitizen :老年人 (1表示是,0表示不是)
Partner :是否有配偶 (Yes or No)
Dependents :是否有家属 (Yes or No)
tenure :客户存留时长(0-72个月)
服务需求
PhoneService :是否开通电话服务业务 (Yes or No)
MultipleLines:是否开通了多线业务(Yes 、No or No phoneservice 三种)
InternetService:是否开通互联网服务 (No, DSL数字网络,fiber optic光纤网络 三种)
OnlineSecurity:是否开通网络安全服务(Yes,No,No internetserive 三种)
OnlineBackup:是否开通在线备份业务(Yes,No,No internetserive 三种)
DeviceProtection:是否开通了设备保护业务(Yes,No,No internetserive 三种)
TechSupport:是否开通了技术支持服务(Yes,No,No internetserive 三种)
StreamingTV:是否开通网络电视(Yes,No,No internetserive 三种)
StreamingMovies:是否开通网络电影(Yes,No,No internetserive 三种)
交易倾向
Contract:签订合同方式 (按月,一年,两年)
PaperlessBilling:是否开通电子账单(Yes or No)
PaymentMethod:付款方式(bank transfer,credit card,electronic check,mailed check)
MonthlyCharges:月费用
TotalCharges:总费用
研究对象
Churn:该用户是否流失(Yes or No)
#导入数据集
options(scipen = 200)
df <- read.csv("F:/telco-customer-churn/WA_Fn-UseC_-Telco-Customer-Churn.csv")`
特征工程
1、数据预处理
1.1、特征类型处理
#SeniorCitizen转换为因子变量
df <- within(df,{
SeniorCitizen <- factor(SeniorCitizen,levels = c(0,1),labels = c("No","Yes"))
})
1.2、缺失值处理
colSums(is.na(df)) mean(is.na(df$TotalCharges)) library(VIM) opar <- par(no.readonly = T) par(cex=0.72,font.axis=3) aggr(df,prop=T,numbers=T) par(opar) #只有TotalCharges列有11个缺失值,占比大约0.156%

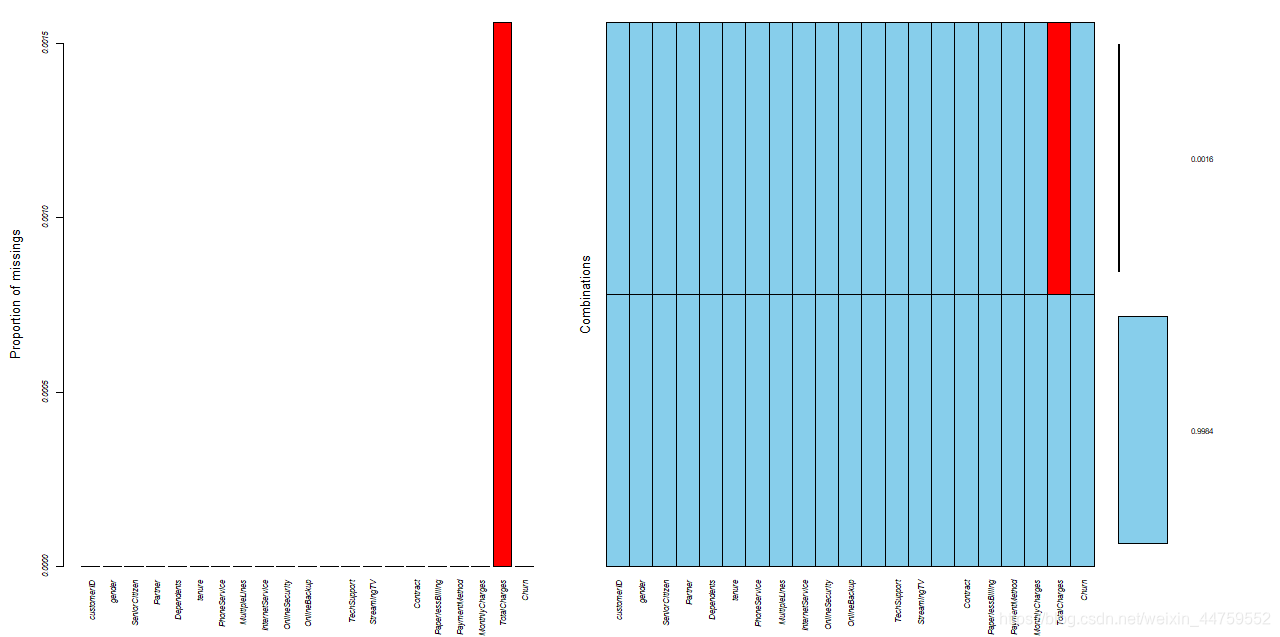
hist(df$TotalCharges,breaks = 50,prob=T,main = "histogram of TotalCharges") df$TotalCharges[is.na(df$TotalCharges)] <- median(df$TotalCharges,na.rm = T)
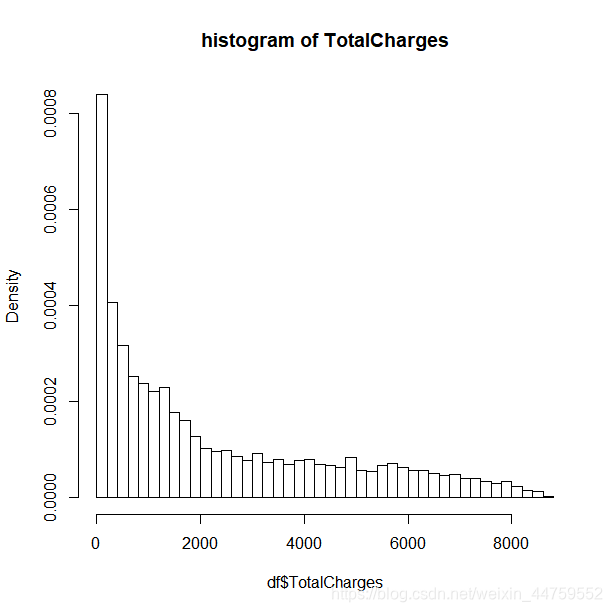
TotalCharges是数值型数据,从直方图可以看到该列数据是偏态分布。根据正态分布选均值、中位数填充,偏态分布选中位数填充的原则,我选择用TotalCharges列的中位数去填充这11个缺失值。
1.3、异常值处理
layout(matrix(c(1,2),1,2,byrow = T)) boxplot(df$MonthlyCharges,xlab="MonthlyCharges") boxplot(df$TotalCharges,xlab="TotalCharges")
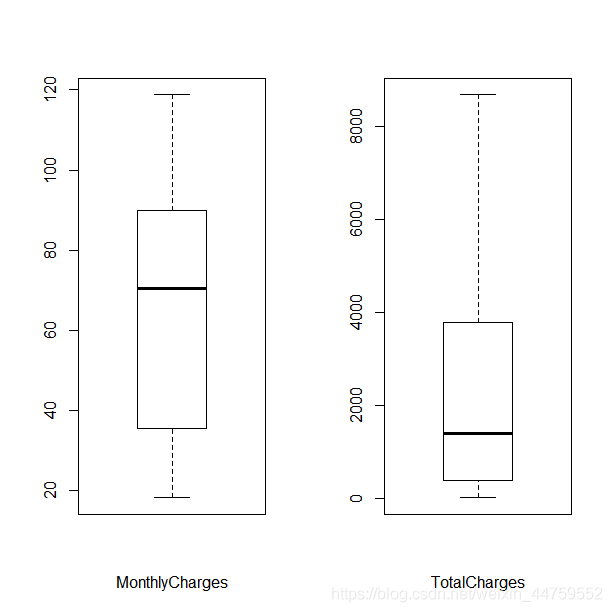
通过箱线图可以看到MonthlyCharges、TotalCharges两个特征无极端异常值,但总费用量纲差异大,对特征进行分箱离散化处理
library(Hmisc)
describe(df[c("MonthlyCharges","TotalCharges")])
#根据描述性统计量将变量按0.25,0.5,0.75分位数分成4份
c_u_t <- function(x,n=1) {
result <- quantile(x,probs = seq(0,1,1/n))
result[1] <- result[1]-0.001
return(result)
}
df <- transform(df,
MonthlyCharges_c = cut(df$MonthlyCharges,
breaks = c_u_t(df$MonthlyCharges,n=4),labels = c(1,2,3,4)),
TotalCharges_c = cut(df$TotalCharges,
breaks = c_u_t(df$TotalCharges,n=4),labels = c(1,2,3,4)))
df <- within(df, {
MonthlyCharges_c <- relevel(MonthlyCharges_c, ref = 1)
TotalCharges_c <- relevel(TotalCharges_c, ref = 1)
})
1.4、分类变量标签整理
for (i in 10:15) {
print(prop.table(xtabs(~Churn+get(names(df)[i]),data = df)))
}
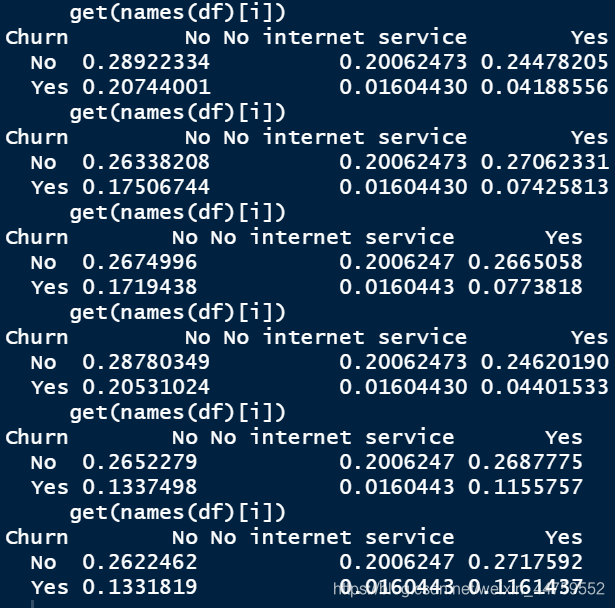
通过OnlineSecurity、OnlineBackup、DeviceProtection、TechSupport、StreamingTV、StreamingMovies这6个变量分别和Churn生成二维列连表可以看到,"No internet service"这个标签的总数占比都是一致的,可以认为这个标签不影响流失率,所以把这个标签并入“No"标签
df <- within(df,{
levels(OnlineSecurity)[2] <- "No"
levels(OnlineBackup)[2] <- "No"
levels(DeviceProtection)[2] <- "No"
levels(TechSupport)[2] <- "No"
levels(StreamingTV)[2] <- "No"
levels(StreamingMovies)[2] <- "No"
})
2、特征选择
2.1、方差过滤
df <- df[c(1,6,2:5,7,10:15,17,22,23,8,9,16,18,21,19,20)] #变量位置重排 library(caret) nearZeroVar(df[c(3:14)],freqCut = 90/10,saveMetrics = T) df$PhoneService <- NULL
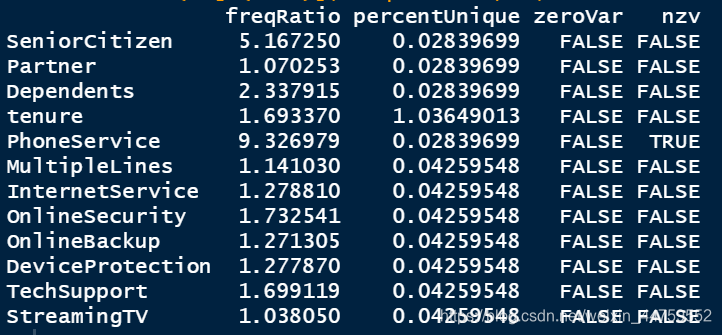
对二分类变量进行方差过滤,变量PhoneService的nzv为TRUE即方差接近于零,代表这个变量中其中一类非常少,占比少于10%,则它变异程度小,提供的信息少,应该被筛选掉。
2.2、卡方检验过滤
sapply(df[c(3:19)], function(x){
ch <- chisq.test(x,df$Churn,simulate.p.value = T)
list(chi_v=ch$statistic,p=ch$p.value)
})
df$gender <- NULL

分类变量和目标变量Churn的卡方检验中,除了gender的P值为0.494,其他特征的P值都远小于0.01,所以不能拒绝gender和Churn相互独立的原假设,应被筛选掉。
2.3、模型整体效果过滤
(mydata <- df[c(2:19)]) lg <- glm(Churn~.,family = binomial(),data = mydata) lg_back <- step(lg,direction = "backward") summary(lg_back) anova(lg_back,lg,test = "Chisq")
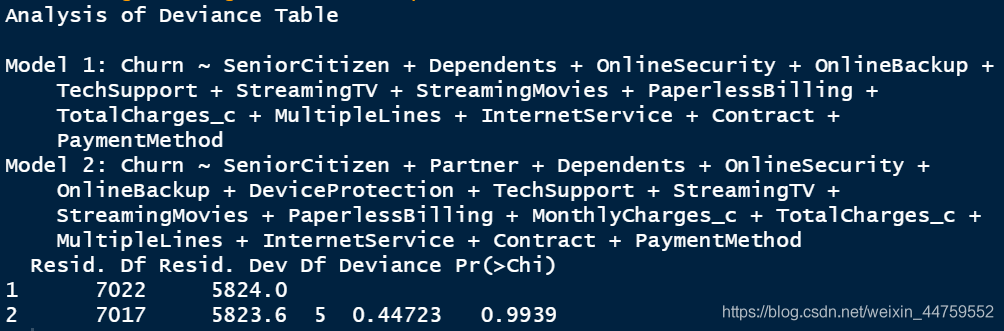
通过AIC向后法筛选出的特征筛除掉了Partner、DeviceProtection、MonthlyCharges_c三个变量。用anova函数对两个模型进行卡方检验P=0.99,表明两个模型拟合度一样好,有理相信这三个变量不会显著提高方程的预测精度。暂时先不删除这些变量,稍后再详细分析Logistic回归。
2.4、利用随机森林进行特征重要性筛选
library(randomForest) set.seed(123) (rf <- randomForest(Churn~.,data=mydata,importance=T,ntree=100)) (imp <- importance(rf,type=2)) imp[order(-imp),]

随机森林模型显示出tenure、Contract、PaymentMethod这三个特征重要性最高,Dependents、StreamingTV、StreamingMovies这三个特征重要性最低。这些低重要性特征暂时还是保留。
相关回归分析
1、二联列联表的相关性度量
attach(df)
library(vcd)
for (i in 3:18) {
print(assocstats(table(get(names(df)[i]),Churn)))
}
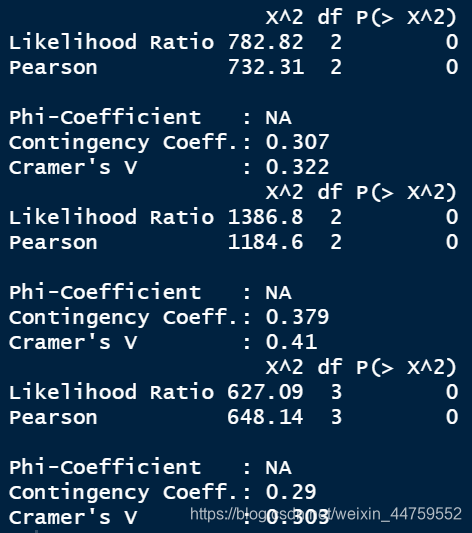
分别度量了每个分类特征与目标变量Churn的相关性强弱,Contract、InternetService、PaymentMethod与目标变量Churn的相关性较强。由于其他变量也通过了卡方检验,所以和Churn也有相关性,只是弱于这三个变量。
2、连续型变量的差异检验
#由于三个连续型变量都是偏态分布,所以用非参数检验 by(tenure,Churn,median) wilcox.test(tenure~Churn,data=df) by(MonthlyCharges,Churn,median) wilcox.test(MonthlyCharges~Churn,data=df) by(TotalCharges,Churn,median) wilcox.test(TotalCharges~Churn,data=df) library(ggplot2) ggplot(df,aes(x=tenure,fill=Churn))+ geom_bar(position = "dodge")+ labs(title = "Churn BY tenure")

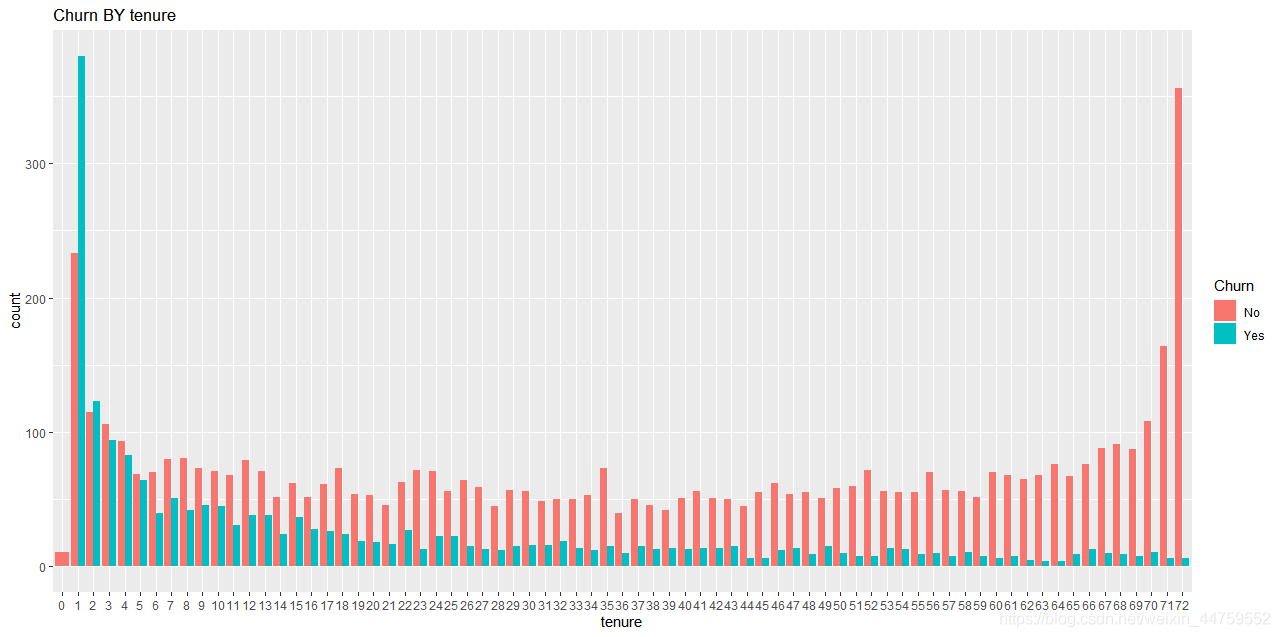
这三个连续变量wilcox非参数检验P值都远小于0.01,所以认为流失和非流失的用户在这三个变量间都有差异。tenure这个变量,非流失用户存留时长的中位数为38个月,流失用户的存留时长为10个月,通过图形也可以看出前几个月尤其前6个月的流失率较高。
3、多重对应分析
library(plyr) df1 <- rename(df,c(SeniorCitizen="SC",Partner="P",Dependents="D", OnlineSecurity="OS",OnlineBackup="OB",DeviceProtection="DP", TechSupport="TS",StreamingTV="ST",StreamingMovies="SMo", PaperlessBilling="PB",MonthlyCharges_c="MC",TotalCharges_c="TC", MultipleLines="ML",InternetService="IS",Contract="Ctr", PaymentMethod="PM")) #对变量进行重命名,使类别图更清晰 library(ade4) mca <- dudi.acm(df1[3:19],scann = FALSE, nf = 2) co <- mca$co library(ggplot2) library(ggrepel) windows() ggplot(data=co,aes(x=Comp1,y=Comp2))+geom_point(shape=21,size=2.2,color="red")+ theme(panel.background = element_rect(fill ="white",colour = "black"))+ geom_vline(xintercept = 0, color = "gray", size = 0.5)+ geom_hline(yintercept = 0, color = "gray", size = 0.5)+ geom_text_repel(aes(Comp1,Comp2, label=rownames(co)),box.padding = unit(0.5,'lines'))+ labs(x = "MCA1: 63.7%", y = "MCA2: 16.4%")

用多重对应分析对各变量进行降维,降维信息浓缩后,相同方位距离近的特征可能有关联:
①、先看距离原点较远的聚集点:月费用最低等级(MC.1)和没有开通互联网服务(IS.No)相近有关联,确实符合实际情况逻辑;开通在线备份业务(OB.Yes)、开通设备保护业务(DP.Yes)、开通技术支持服务(TS.Yes)、开通网络安全服务(OS.Yes)相近,说明有一类客户很重视通信安全和通信数据保存,这类用户可能是商务用途,可以做一个商务组合套餐。
②、再看距离特别近的团簇:没有开通网络电视(ST.No)、没有开通网络电影(SMo.No)、第二等级总费用(TC.2)、没有开通多线业务(ML.No)相近,此类客户可能只开通了基础的功能。
③、接着看离Churn较近的点:银行自动转账付款方式(PM.Bank.transfer…automatic)、信用卡自动转账付款方式(PM.Credit.card…automatic)、有配偶(P.Yes)、按一年签订合同(Crt.One.year)、开通数字网络(IS.DSL)、有家属(D.Yes)和用户没有流失(Churn.No)相近,说明有这类特征的客户黏性高,较稳定,需要继续做好这类客户的维护和开发。
④、最后流失用户(Churn.Yes)周围没有很相近的点,而相对较近的特征有按月签订合同(Crt.Month.to.monthr)、电子支票付款方式(PM.Electronic.check)、老年人(SC.Yes),这类客户有流失的风险,可以出针对性的活动方案,提高这类客户的黏性。
4、Logistic回归分析
fit.full <- glm(Churn~.,data = mydata,family = binomial()) summary(fit.full) fit.both <- step(fit.full,direction = "both") summary(fit.both) anova(fit.both,fit.full,test = "Chisq")
数据集的自变量数目较多,为了使建立的Logistic回归模型比较稳定和便于解释,应尽可能地将回归效果不显著的自变量排除在外。用逐步法筛选变量后的模型和前面模型整体过滤时用的向后法结果是一样的
coefficients(fit.both) exp(coef(fit.both))
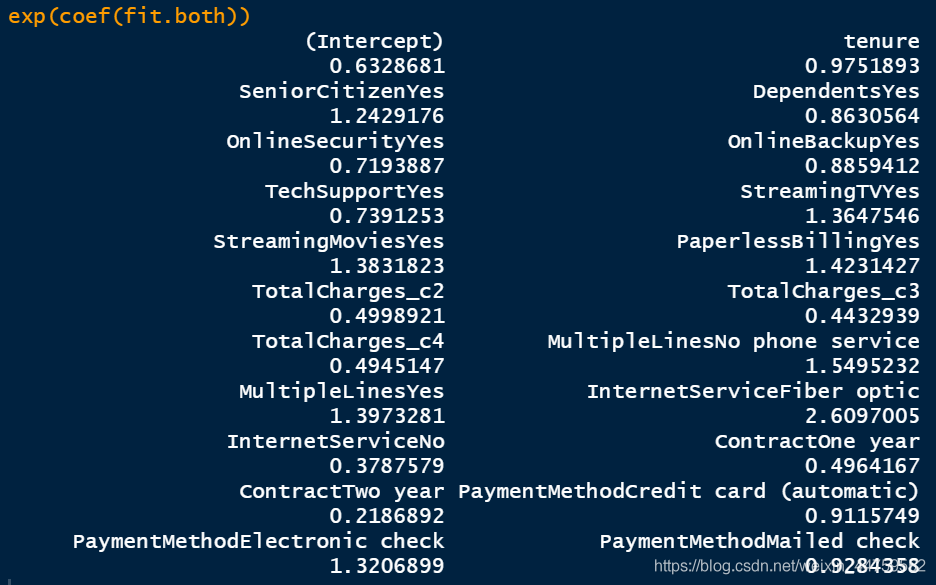
用筛选后的变量建立逻辑回归模型。系统输出的是Churn=Yes时的概率模型,结果中Exp在0.5~1.5之间的弱影响因素暂时忽略。可以看到保持其他变量不变:
①、开通光纤互联网服务的客户流失风险是数字网络互联网服务的2.6倍,没有开通互联网服务的流失风险是数字网络互联网服务的0.3倍,所以没有开通互联网服务的客户流失风险最低。
②、按一年签订合同的客户流失风险是按月签订合同的0.4倍,按两年签订合同的客户流失风险是按月签订合同的0.2倍,所以签订合同的期限越长,客户流失的概率越小。
③、总费用第2等级的客户流失风险是第一等级(18.8,402] 的0.49倍,第三等级是第一等级的0.44倍,第四等级是第一等级的0.49倍,说明总费用第一等级,流失风险最大。
小结:
- tenure前6个月是高流失区域,后面月份的用户流失逐渐减少。
- Contract签订合同方式对用户留存影响较大,流失风险按月签订>按一年签订>按两年签订,签订合同的期限越长,客户流失的概率越小。
- TotalCharges_c总费用等级高的用户是稳定的,花费较低的用户容易流失。
- PaymentMethod付款方式方面,电子支票付款方式流失率较高,自动化付款方式流失率低。
- InternetService网络服务对用户留存也影响较大,流失风险光纤互联网服务>数字网络服务>没有开通互联网。
- 一类客户倾向于开通在线备份业务、设备保护业务、技术支持服务、网络安全服务这些相关的安全服务
分类与模型预测有效性
set.seed(123)
#建立训练集和测试集,用来建立模型和评估模型的有效性
train <- sample(nrow(mydata),0.7*nrow(mydata))
mydata.train <- mydata[train,]
mydata.test <- mydata[-train,]
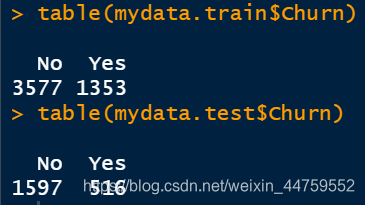
table(mydata.train$Churn)
table(mydata.test$Churn)
#逻辑回归混淆矩阵
prob <- predict(fit.both,mydata.test,type="response")
logit.pred <- factor(prob>0.5,levels = c(FALSE,TRUE),labels = c("No","Yes"))
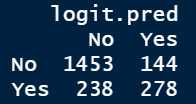
logit.perf <- table(mydata.test$Churn,logit.pred)
这分别是训练集和测试集的Churn分类,还有逻辑回归模型的混淆矩阵
1、决策树和随机森林
library(rpart) set.seed(123) dtree <- rpart(Churn~.,data = mydata.train,method = "class", parms = list(split="information")) dtree$cptable plotcp(dtree) #按3次分割对应的复杂度参数0.01剪枝 dtree.pruned <- prune(dtree,cp=0.01) library(partykit) plot(as.party(dtree.pruned),main="Decision Tree") dtree.pred <- predict(dtree.pruned,mydata.test,type="class") dtree.perf <- table(mydata.test$Churn,dtree.pred)
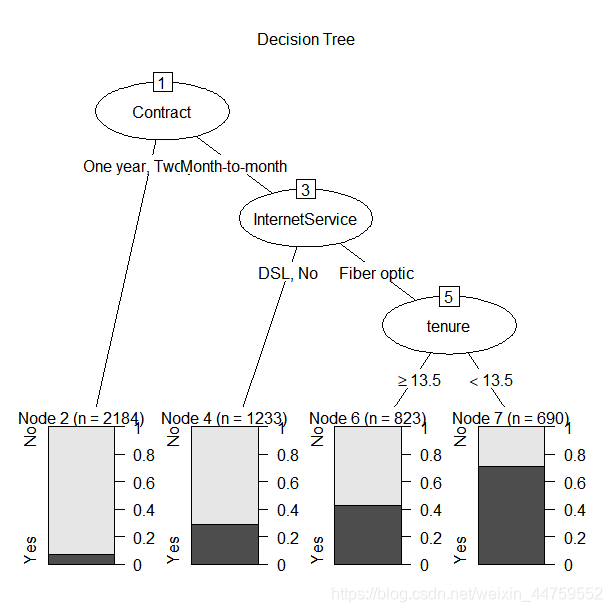
决策树的用纯度最大化法进行的变量重要性排序依次是:Contract、InternetService、tenure,按一年两年签订合同的客户稳定性更强;开通数字网络和没有开通网络服务的客户稳定性更强,存留时长大于13.5个月的客户稳定性更强。综合起来就是按月签订合同、开通光纤网络服务,存留时长小于13.5个月的客户容易流失
#生成100棵决策树的随机森林 fit.forest <- randomForest::randomForest(Churn~.,data = mydata.train,ntree=100) forest.pred <- predict(rf,mydata.test) (forest.perf <- table(mydata.test$Churn,forest.pred))
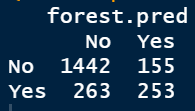
随机森林属于黑箱操作,无法做到和单一决策树一样的可解释性。
2、支持向量机
library(e1071) set.seed(123) fit.svm <- svm(Churn~.,data=mydata.train) fit.svm svm.pred <- predict(fit.svm,mydata.test) (svm.perf <- table(mydata.test$Churn,svm.pred))
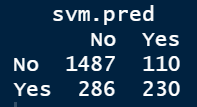
同样缺乏可解释性,而且准确率较低
3、模型预测有效性
#定义分类器性能标准
performance <- function(table,n=2) {
if(!all(dim(table)==c(2,2)))
stop("Must be a 2 x 2 table")
tn = table[1,1]
fp = table[1,2]
fn = table[2,1]
tp = table[2,2]
sensitivity = tp/(tp+fn)
specificity = tn/(tn+fp)
ppp = tp/(tp+fp)
npp = tn/(tn+fn)
hitrate = (tn+tp)/(tn+fp+fn+tp)
result <- cat(" Sensitivity =",round(sensitivity,n),
"\n","Specificity =",round(specificity,n),
"\n","Positive Predictive Value =",round(ppp,n),
"\n","Negative Predictive Value =",round(npp,n),
"\n","Accuracy=",round(hitrate,n),"\n")
}
performance(logit.perf)
performance(dtree.perf)
performance(forest.perf)
performance(svm.perf)
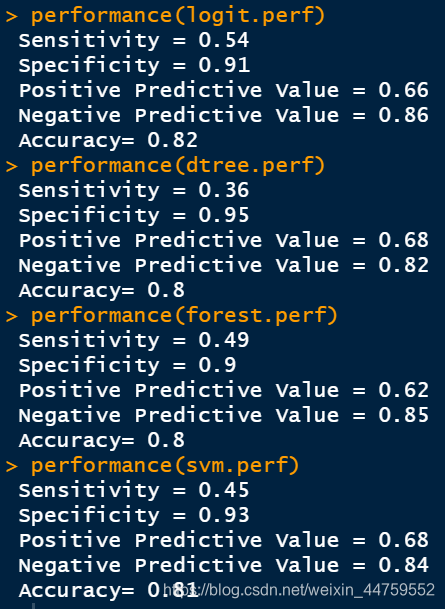
这几个分类器的准确率都达到80%以上,但由于测试样本中流失率只有24%,所以是就算只有截距的机械模型,准确率也高达76%。从流失判断这个角度来说Sensitivity敏感度(即成功鉴别流失样本的概率)这一指标格外重要,逻辑回归这一指标数值稍高,达到54%,说明有54%的流失客户被判别出来了。
总结与建议

- 用户方面:针对老年用户、无亲属、无伴侣用户的特征推出定制服务如老年朋友套餐、温暖套餐等。鼓励用户加强关联,推出各种亲子套餐、情侣套餐等,满足客户的多样化需求。针对新注册用户,推送半年优惠如赠送消费券,以度过用户流失高峰期。
- 服务方面:针对光纤用户可以推出光纤和通讯组合套餐,对于连续开通半年以上的用户给与优惠减免。开通网络电视、电影的用户容易流失,需要研究这些用户的流失原因,是服务体验如观影流畅度清晰度等不好还是资源如片源等过少,再针对性的解决问题。针对在线安全、在线备份、设备保护、技术支持等增值服务,应重点对用户进行推广介绍,如首月/半年免费体验,使客户习惯并受益于这些服务
- 交易倾向方面:针对单月合同用户,建议推出年合同付费折扣活动,将月合同用户转化为年合同用户,提高用户存留时长,以减少用户流失。 针对采用电子支票支付用户,建议定向推送其它支付方式的优惠券,引导用户改变支付方式。对于开通电子账单的客户,可以在电子账单上增加等级积分等显示,等级升高可以免费享受增值服务,积分可以兑换某些日用商品。

- Kaggle数据集之电信客户流失数据分析(三)之决策树分类
- Kaggle数据集之电信客户流失数据分析(一)
- 电信客户流失数据分析(二)
- 利用数据挖掘实现电信行业客户流失分析
- 电信客户流失数据分析(一)
- 哈希表在电信公用电话客户流失分析中的应用
- 哈希表在电信公用电话客户流失分析中的应用
- 数据挖掘模型的深入-客户流失分析(2)
- 数据挖掘中的预处理——以电信客户流失问题为例
- 数据挖掘模型的深入-客户流失分析(1)
- 哈希表在电信公用电话客户流失分析中的应用
- 基于数据挖掘的客户流失分析案例
- 电信客户流失分析与预警
- 电信客户流失分析
- Kaggle-电信客户流失分析及应对措施
- 商业银行客户流失的影响因素分析——基于sas数据挖掘
- 数据分析如何避免客户流失
- 【大数据部落】电信公司churn数据客户流失knn预测分析(一)
- KNIMI数据挖掘建模与分析系列_004_利用KNIMI做客户流失预测
- 金融风控-->客户流失预警模型-->金融数据分析