Elasticsearch-通过Analyzer进行分词
2020-08-11 10:31
686 查看
1、Analysis 与 Analyzer
- Analysis—文本分析是把全文本转换一系列单词(term / token)的过程,也叫分词
- Analysis是通过Analyzer来实现的
° 可使用Elasticsearch内置的分析器/或者按需定制化分析器
• 除了在数据写入时转换词条,匹配Query语句时候也需要用相同的分析器对查询语句进行分析
2、Analyzer的组成
• 分词器是专门处理分词的组件,Analyzer由三部分组成
o Character Filters (针对原始文本处理,例如去除html)/ Tokenizer (按照规则 切分为单词)/ Token Filter (将切分的的单词进行加工,小写,删除stopwords,增加同义词)

3、Elasticsearch的内置分词器
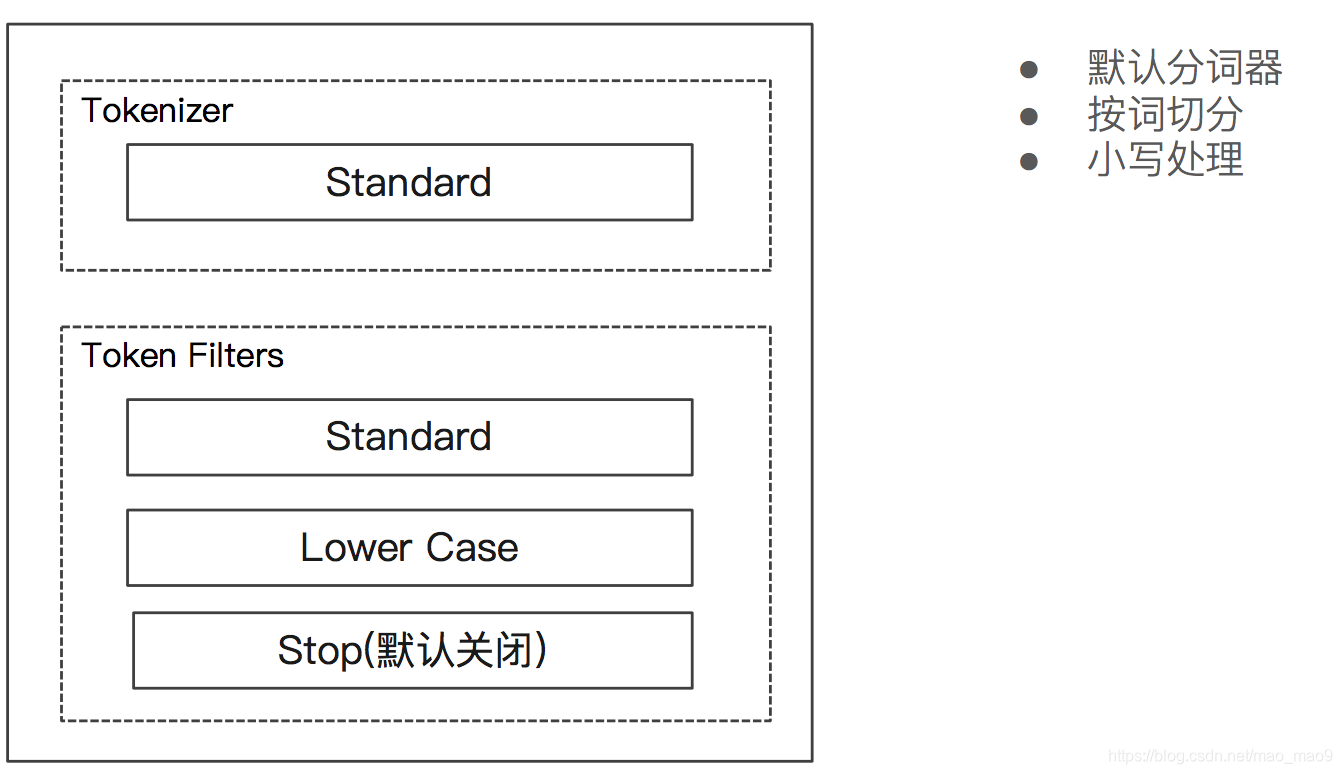
- Standard Analyzer 一默认分词器,按词切分,小写处理
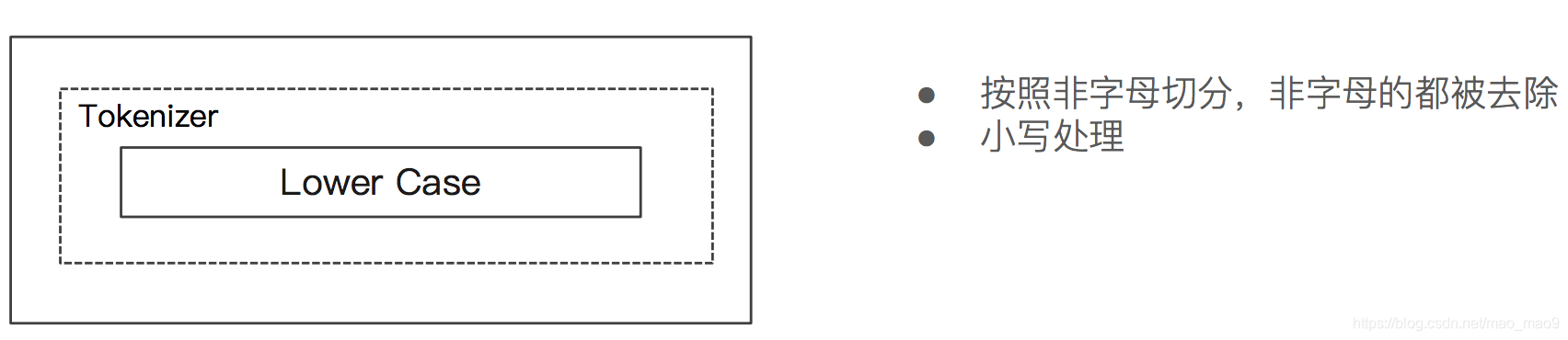
- Simple Analyzer 一按照非字母切分(符号被过滤),小写处理
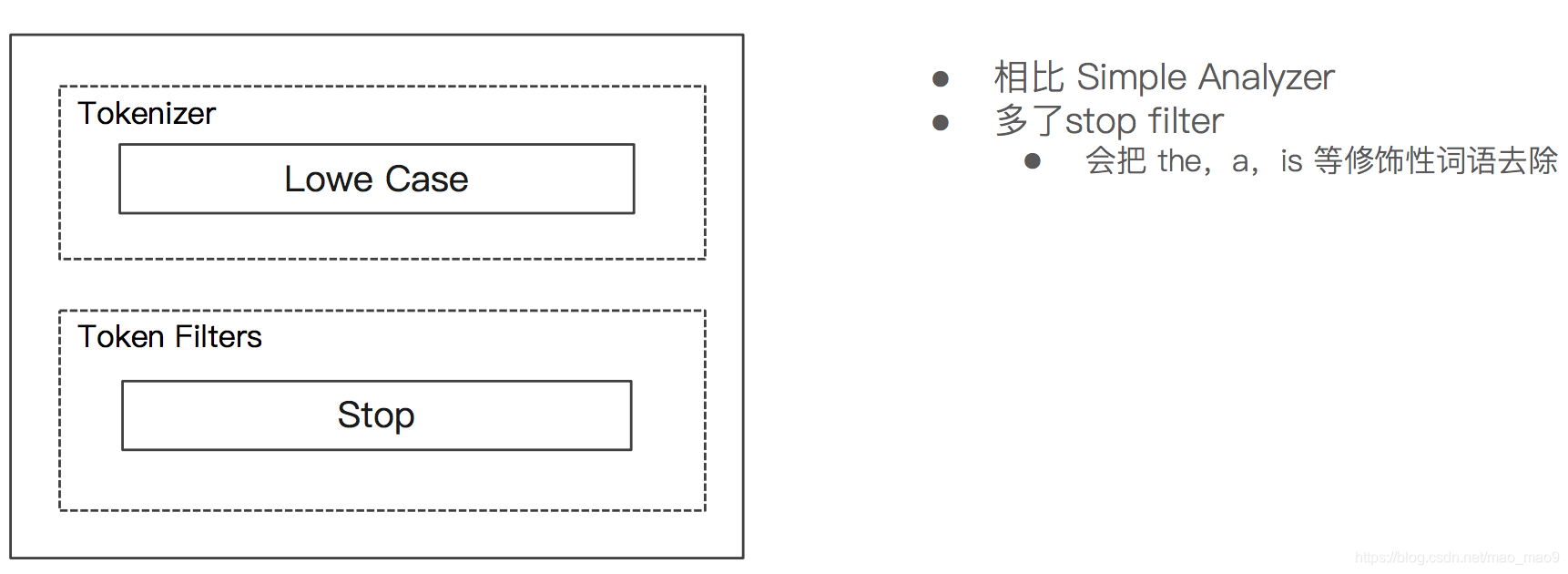
- Stop Analyzer 一小写处理,停用词过滤(the, a, is)
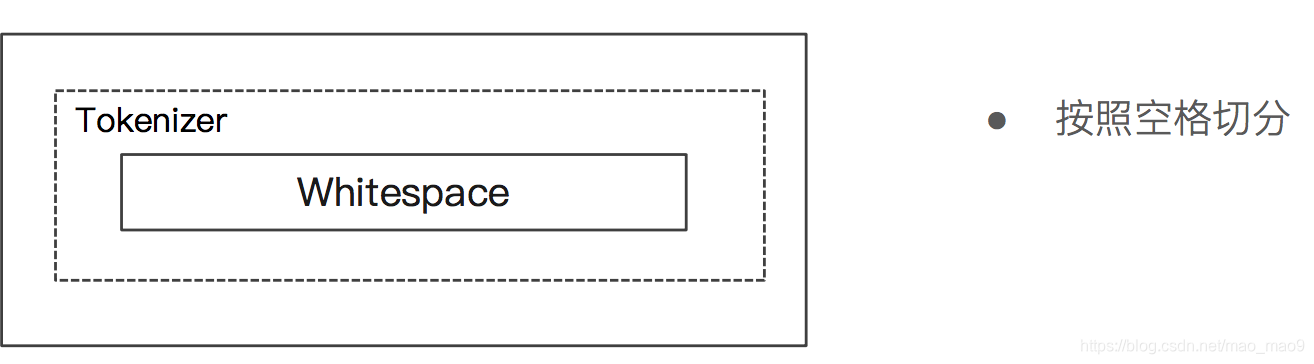
- Whitespace Analyzer —按照空格切分,不转小写
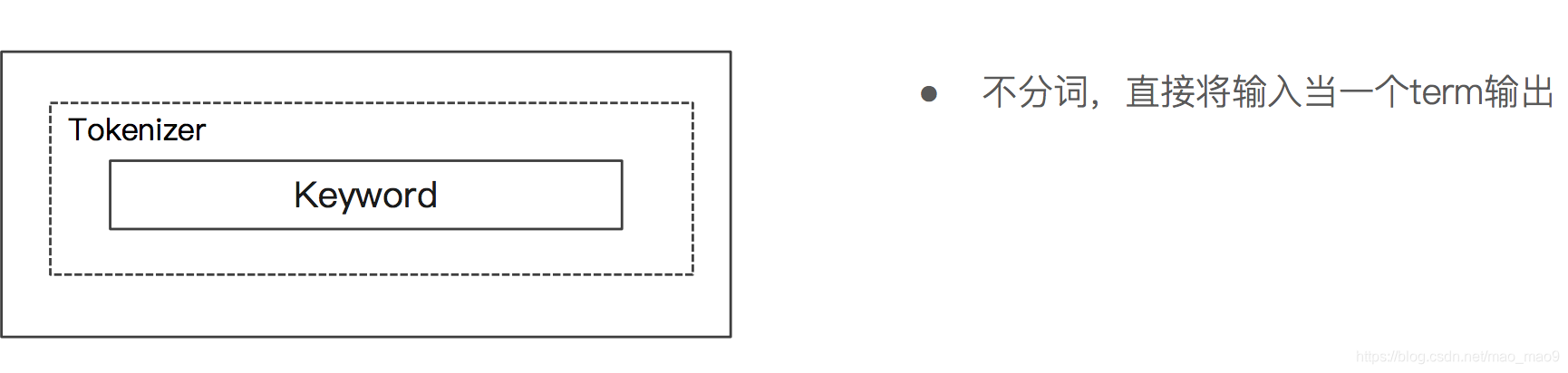
- Keyword Analyzer —不分词,直接将输入当作输出
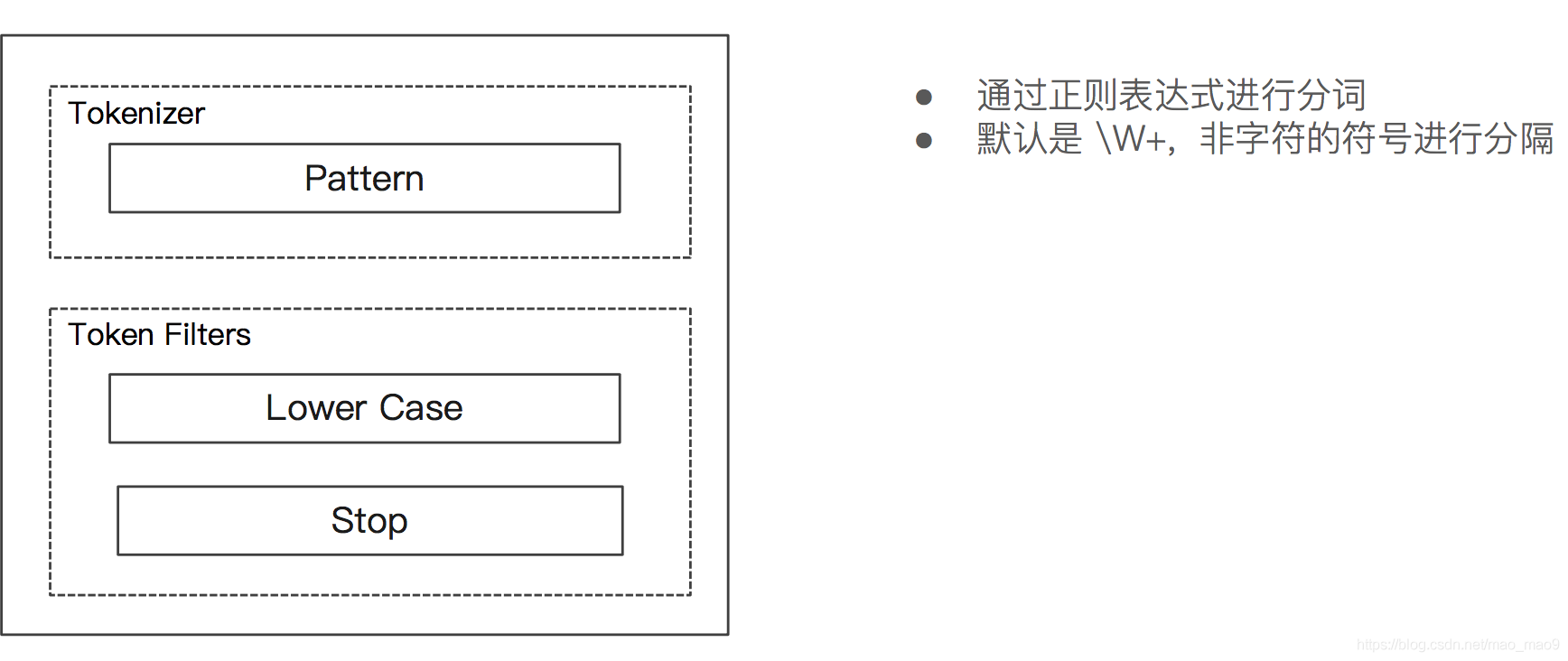
- Patter Analyzer —正则表达式,默认\W+ (非字符分隔)
- Language-提供了30多种常见语言的分词器
- Customer Analyzer自定义分词器
4、使用 _analyzer API
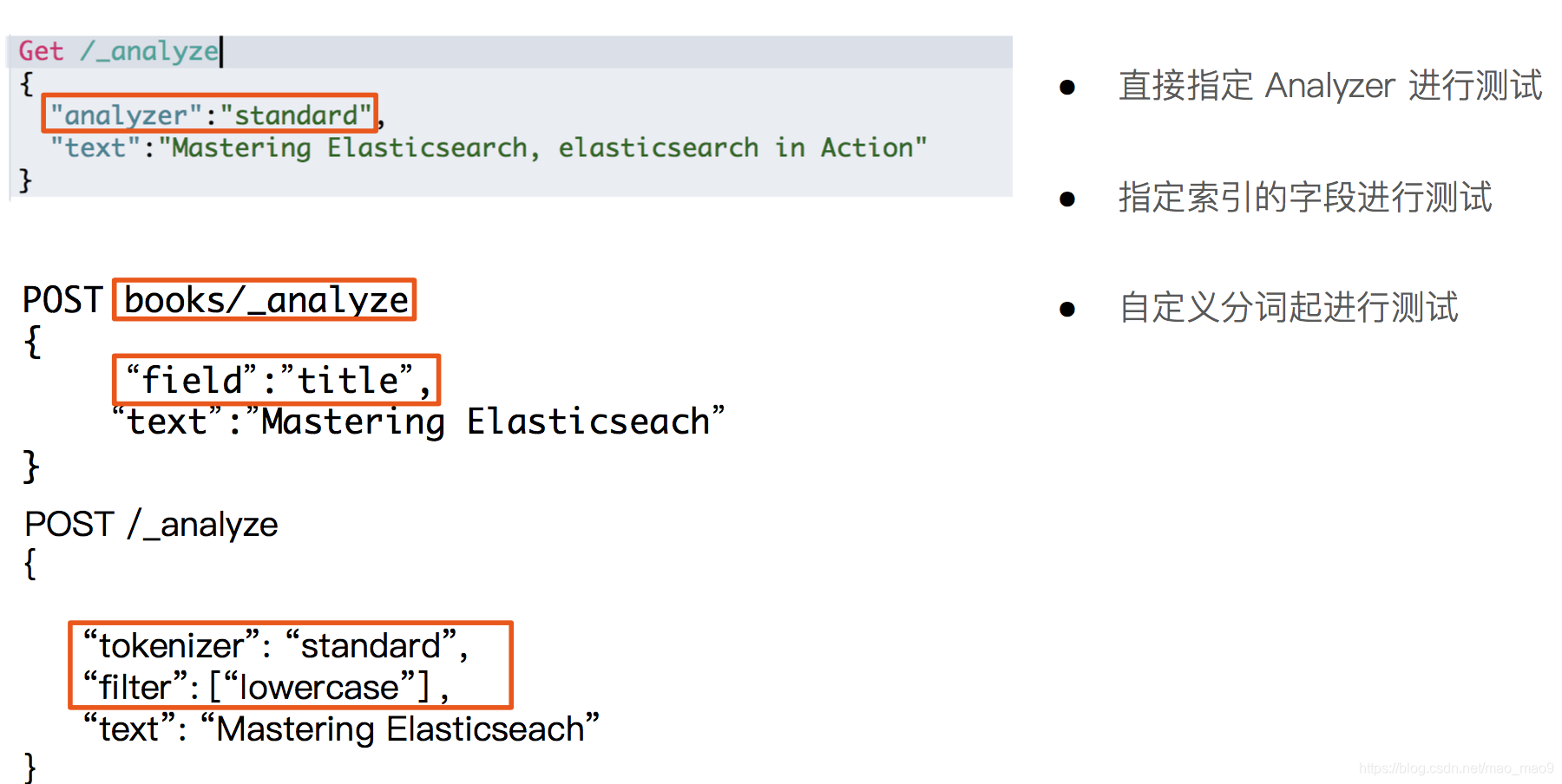
5、Elasticsearch的内置分析器
- Standard Analyzer 一默认分词器,按词切分,小写处理
- Simple Analyzer 一按照非字母切分(符号被过滤),小写处理
- Stop Analyzer 一小写处理,停用词过滤(the, a, is)
- Whitespace Analyzer —按照空格切分,不转小写
- Keyword Analyzer —不分词,直接将输入当作输出
- Patter Analyzer —正则表达式,默认\W+ (非字符分隔)
- Language-提供了30多种常见语言的分词器
5.1 Standard Analyzer
5.2 Simple Analyzer
5.3 Stop Analyzer
5.4 Whitespace Analyzer
5.5 Keyword Analyzer
5.6 Patter Analyzer
5.8 Language


相关文章推荐
- 通过Analyzer进行分词
- elasticsearch6.3.2中建立父子文档,并通过java api和rest api进行数据导入
- 用python通过结巴分词对语料库进行分词初步实现word2vec
- ES 24 - 如何通过Elasticsearch进行聚合检索 (分组统计)
- Elasticsearch Analyzer原理分析并实现中文分词
- Elasticsearch 全字段搜索_all,query_string查询,不进行分词
- Elasticsearch搜索引擎学习记录3-分词器(analyzer)应用
- Python:通过gensim和jieba分词进行文本相似度分析
- IK 分词器 2012 FF 版本取消了 org.wltea.analyzer.solr.IKTokenizerFactory 类【导致只能使用ik分词器来进行分词,无法使用solr自带的其它过滤方式
- ElasticSearch5.5.0 通过IK分词 全文索引
- 【elasticsearch】(3)centos7 安装中文分词插件elasticsearch-analyzer-ik
- elasticsearch安装与使用(3)-- 安装中文分词插件elasticsearch-analyzer-ik
- 通过AS工具来对它所连接的设备进行截图
- android通过HttpClient与web服务端进行数据交互
- 通过互联网进行产品比较选购的方法
- Linux通过Shell对文件自动进行远程拷贝备份
- 代码片段:通过反射对类进行实例化
- 在S60第三版手机上通过USB线进行串行通信
- 使用Java调用ElasticSearch提供的相关API进行数据搜索完整实例演示
- 如何在eclipse中通过Juit进行单元测试