大数据-第10章 spark 概况
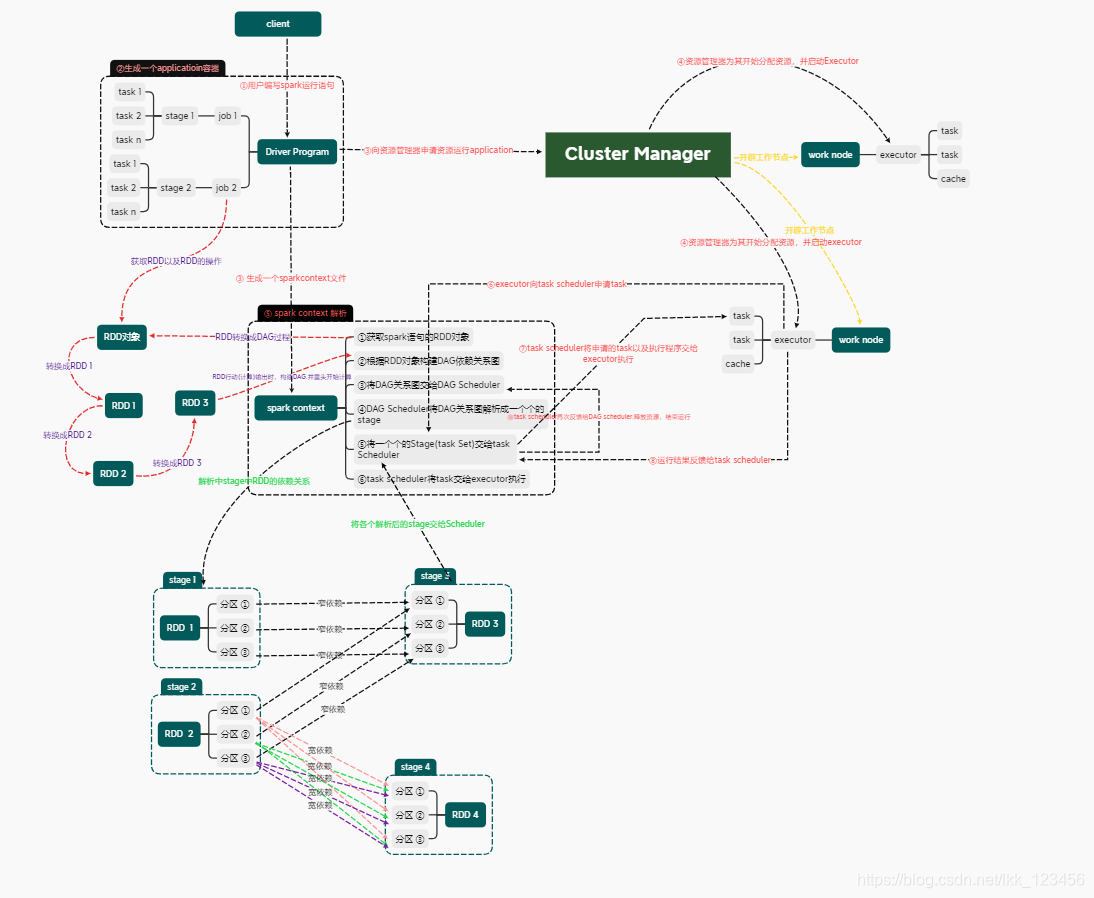
执行流程
①用户编写spark语句运行程序
②生成一个application以及运行环境driver
③生成一个sparkcontext以及向资源管理器申请运行application的资源
④资源管理器向exceutor分配资源,并且启动exceutor
⑤sparkcontext解析spark程序
(1).生成spark的RDD对象
(2).根据RDD对象生成DAG关系依赖图
(3).将DAG关系依赖图交给DAGScheduler
(4). DAGScheduler解析成一个个的stage
(5).将stage交给TaskScheduler
⑥exceutor向TaskScheduler申请task
⑦TaskScheduler将申请的task发送给exceutor,exceutor并执行task
⑧exceutor将执行结果返回给TaskScheduler
⑨TaskScheduler将结果返回DAGScheduler,并释放资源,程序结束
1.spark简介
答:
spark是基于内存计算的大数据并行运算框架,可用于构建大型的、低延迟的数据分析应用。
2.spark特点
答:
①运行速度快:使用DAG执行引擎支持循环数据流与内存计算;
②容易使用:支持使用Scala、java、Python和R语句进行编程,可以通过spark shell进行交互式编程;
③通用性:spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件;
④运行模式多样:可以运行独立的集群模式、也可以运行与hadoop等,同时可以访问多种数据来源。
3.hadoop面临的一些缺点
答:
①表达能力有限;
②磁盘IO开销大;
③延迟高,任务之间的衔接涉及IO开销,在前一个任务执行完成之前,其他任务就无法开始,难以胜任复杂、多阶段的计算任务。
4.spark优点
答:
①spark计算模式也是属于MapReduce,但不局限与map和reduce操作,还提供了多种数据集操作类型,编程模型比hadoop MapReduce更灵活;②spark提供了内存计算,可以将中间结果放到内存中,对于迭代运算效率更高;
③spark基于DAG任务调度执行机制,有优于hadoop MapReduce的迭代执行机制。
5.spark生态系统
答:
①spark的设计遵循“一个软件栈满足不同应用场景”的理念,逐渐形成了一套完整的生态系统;
②即能够提供内存计算框架,也可以支持SQL查询、实现流式计算、机器学习和图计算等;
③spark可以部署在资源管理器yarn之上,提供一站式的大数据解决方案;④spark支持批量处理、交互式查询、流数据处理;⑤spark生态系统包括:spark core、spark SQL、spark streaming、MLLib、GraphX。
6.RDD
答:
弹性分布式数据集的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
7.DAG
答:
有向无环图的简称,反应各个RDD之间的依赖关系。
8.Executor
答:
是运行工作节点的一个进程,负责运行Task。
9.Application
答:
用户编写的spark应用程序。
10.Task
答:
运行在Executor上的工作单元。
11.Job
答:
一个job包含多个RDD及作用于相应RDD上的工作操作。
12.Stage
答:
是job的基本调度单位,一个job会分为多组Task,每组Task被称为Stage,或者也被称为TaskSet,代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集。
13.RDD解析
答:
①弹性 当计算过程中内存不足时可以刷写到磁盘等外存上,可以与外内存灵活的数据交换;RDD使用了一种“血统”的容错机制,在机构更新和丢失后可随时根据血统进行数据模型的重建;
②数据集 一组只读、有属性的、可分区的分布式数据集合,包含多个分区。分区依照特定规则将具有相同属性的数据记录放在一起,每个分区就相当于一个数据集片段。
14.RDD属性
答:
①与其他RDD之间:父子关系或者依赖关系;
②数据:分区、检查点、迭代器;
③RDD本身:sparkconf sparkcontext。
15.spark核心
答:
spark处理数据时,会将计算转换为一个有向无环图的任务集,RDD能够有效的恢复DAG中故障和慢节点执行的任务,并且RDD提供一种基于粗粒度变换的接口,记录创建数据集的血统,能够实现高效的容错性。
Spark的作用和任务的调度系统是其核心,它能够有效的进行调度的根本原因是因为对任务划分DAG和血统的容错。
16.DAG解析
答:
有向无环图,常用于建模。Spark中使用DAG对RDD的关系进行建模,描述RDD的依赖关系,RDD的依赖关系使用Dependency维护,DAG在spark中的对应的实现为DAGScheduler。
17.RDD产生
答:
目前的MapReduce框架都是把中间结果希尔HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。这是RDD就产生了,RDD是一个抽象的数据架构,不需要担心底层数据分布式的特性,只需要将具体的应用逻辑表达为一系列的转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,避免中间数据存储。
18.RDD概念
答:
①一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可被保存到集群中的不同节点,从而可以在集群中的不同节点上进行并行计算;
②RDD是一个高度受限的共享内存模型,既是只读的记录分区集合,不能直接修改,基于物理内存存储中数据创建RDD,或者通过其他RDD上执行确定的转换操作来创建新的RDD;
③RDD提供的接口都非常简单,类似于map、filter、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。
19.RDD执行
答:
RDD采用惰性调用,即RDD的执行过程,真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,但不会触发真正的计算。
20.spark采用RDD高效计算的原因
答:
①高效的容错机制 血统机制以及容错机制(数据复制或者记录日志);
②中间结果持久化到内存中,RDD之间在内存中传递,避免了不必要的读写磁盘开销;
③存放的数据可以是java对象,避免了不必要的对象序列化和反序列化。
21.RDD之间的依赖关系
答:
①窄依赖:一个父RDD分区对应一个子RDD分区或者多个父RDD对应一个子RDD分区;
②宽依赖:一个父RDD的一个分区对应一个子RDD的多个分区。
22.stage划分
答:
spark通过分析个RDD之间依赖关系生存DAG,在通过DAG解析各个RDD分区之间的依赖关系,来划分stage。
①在DAG中进行反向解析,遇到宽依赖就断开;
②遇到窄依赖就把当前的RDD加入stage中;
③将窄依赖尽量划分在同一个stage中,可以实现流水线计算。
23.stage的类型
答:
①shufflemapstage:不是最终的stage,在它之后还有其他stage,所有输出之间一定需要进过一个shuffle过程,并作为后续stage输入,在一个job可以没有改类型的stage;
②resultstage:最终的stage,没有输出,而是直接产生结果或存储,这种stage是直接输出的结果。Job里面必定(至少含有一个)有该类型的stage。
24.RDD分区作用
答:
①一个HDFS文件的RDD将文件的每一个文件表示一个分区,分区的多少涉及对这个RDD计算的粒度;
②分区越多导致处理分区的任务计算就越多,导致spark任务运行效率减少。一般Spark只能为RDD的每个分区运行1个并发任务,直到达到Spark集群的CPU数量。

- 大数据-第11章 spark-SQL 概况
- 大数据、Hadoop、spark、机器学习、深度学习等书籍表单
- Spark大数据处理环境搭建之hadoop2.7.6
- 2018年最新Python3实战Spark大数据分析及调度
- 大数据系列:Spark的工作原理及架构
- 大数据Spark和Hadoop以及区别(干货)
- RDD基本的转化操作(spark快速大数据分析)
- 流式大数据处理的三种框架:Storm,Spark和Flink
- Spark视频第11期:Spark亚太研究院决胜大数据时代公益大讲坛:Spark Docker
- 用Apache Spark进行大数据处理三
- 大数据Hadoop、Spark、ZooKeeper、Flume、Azkaban、HBase、Storm、Flink、Spark组件常用端口笔记
- 大数据Spark “蘑菇云”行动第94课:Hive性能调优之Mapper和Reducer设置、队列设置和并行执行、JVM重用和动态分区、Join调优
- 决胜大数据时代:Hadoop&Yarn&Spark企业级最佳实践(8天完整版脱产式培训版本)
- 《Spark大数据分析:核心概念、技术及实践》大数据技术一览
- 大数据技术之_19_Spark学习_01_Spark 基础解析小结(无图片)
- 大数据概况及Hadoop生态系统
- Spark快速大数据分析 第2章
- Spark快速大数据分析 第4章
- 决胜Hadoop&Spark大数据时代:Hadoop&Yarn&Spark企业级最佳实践
- 大数据-基于Spark的机器学习-智能客户系统项目