多台计算机共享内存_共享内存多处理器和指令执行| 计算机架构
多台计算机共享内存
共享内存多处理器 (Shared Memory Multiprocessor)
There are three types of shared memory multiprocessor:
共有三种类型的共享内存多处理器:
UMA (Uniform Memory Access)
UMA(统一内存访问)
NUMA (Non- uniform Memory Access)
NUMA(非统一内存访问)
COMA (Cache Only Memory)
COMA(仅缓存内存)
1)UMA(统一内存访问) (1) UMA (Uniform Memory Access))
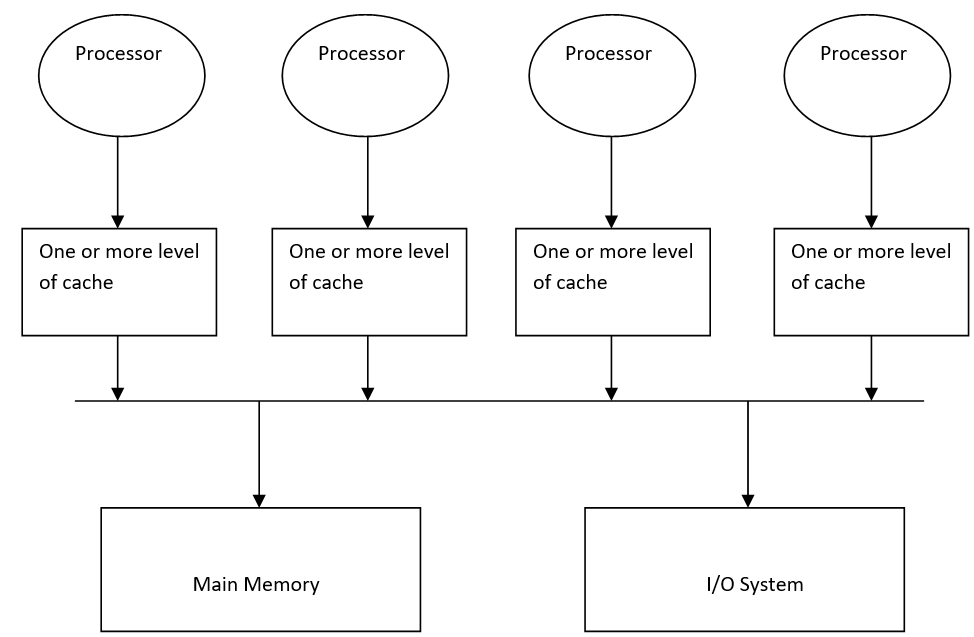
In this type of multiprocessor, all the processors share a unique centralized memory so, that each CPU has the same memory access time.
在这种类型的多处理器中,所有处理器共享唯一的集中式内存,以便每个CPU具有相同的内存访问时间。
2)NUMA(非统一内存访问) (2) NUMA (Non- uniform Memory Access))
In the NUMA multiprocessor model, the access time varies with the location of the memory word. Here the shared memory is physically distributed among all the processors called local memories.
在NUMA多处理器模型中 ,访问时间随存储字的位置而变化。 在这里,共享内存在物理上分布在所有称为本地内存的处理器之间。
So, we can call this as a distributed shared memory processor.
因此,我们可以称其为分布式共享内存处理器。
3)COMA(仅缓存内存) (3) COMA (Cache Only Memory))
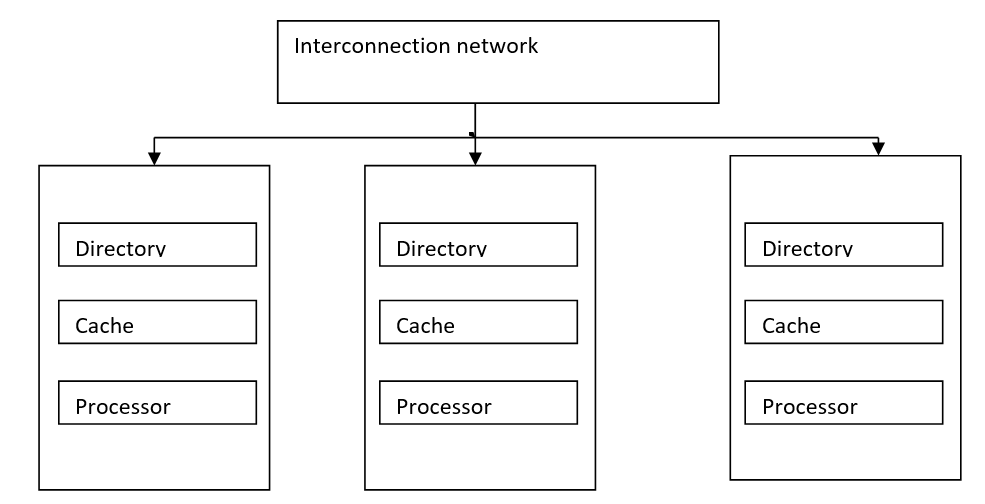
The COMA model is a special case of a non-uniform memory access model; here all the distributed local memories are converted into cache memories. Data can migrate and can be replicated in various memories but cannot be permanently or temporarily stored.
COMA模型是非均匀内存访问模型的特例; 在这里,所有分布式本地内存都转换为高速缓存。 数据可以迁移并可以在各种内存中复制,但是不能永久或临时存储。
We have discussed different types of shared-memory multiprocessors. Now we are moving forward to take a short overview of instruction execution.
我们讨论了不同类型的共享内存多处理器 。 现在,我们将对指令执行进行简要概述。
指令执行 (Instruction Execution)
Now, first of all, what is an instruction, any command that we pass to a computer or system to perform is known as an instruction. A typical instruction consists of a sequence of operations that are fetched, decode, operand fetches, execute and write back. These phases are ideal for overlap execution on a pipeline.
现在,首先,什么是指令,我们传递给计算机或系统要执行的任何命令都称为指令。 典型的指令由一系列的操作组成,这些操作被提取,解码,取操作数,执行和回写。 这些阶段非常适合在管道上执行重叠。
There are two ways of executing an instruction in a pipeline system and a non-pipeline system.
在管道系统和非管道系统中有两种执行指令的方式。
In a non-pipeline system single hardware component which can take only one task at a time from its input and produce the result at the output.
在非管道系统中,单个硬件组件一次只能从其输入执行一项任务,并在输出端产生结果。
On the other hand in case of a pipeline system single hardware component we can split the hardware resources into small components or segments.
另一方面,在流水线系统中,只有一个硬件组件,我们可以将硬件资源拆分为较小的组件或段。
Disadvantages of non-pipeline
非管道的缺点
We process only one input at a single time.
我们一次只能处理一个输入。
Production of partial or segmented output is not possible in the case of the non-pipeline system.
在非管道系统中,无法产生部分或分段输出。
When you will read in deep about pipeline system you will discover pipeline are linear and non-linear also and further linear pipelines are also classified into synchronous and asynchronous.
当您深入了解管道系统时,您会发现管道也是线性和非线性的,进一步的线性管道也分为同步和异步。
As this article was only about the introduction of instruction execution so, we will get further inside the pipeline system.
由于本文仅是关于指令执行的介绍,因此,我们将深入了解流水线系统。
Conclusion:
结论:
In the above article we have discussed the shared memory multiprocessor and introduction instruction execution, I hope you all have gathered the concepts strongly. For further queries, you shoot your questions in the comment section below.
在以上文章中,我们讨论了共享内存多处理器和入门指令的执行 ,希望大家都认真收集了这些概念。 如有其他疑问,请在下面的评论部分中提出问题。
多台计算机共享内存

- 深入理解计算机系统 1.4 处理器读取和解释存储在内存中的指令
- 自己动手写第一阶段的处理器(1)——计算机的简单模型、架构、指令系统
- [20170219]计算机的组成-CPU,内存,硬盘,指令
- ARM指令集——条件执行、内存操作指令、跳转指令
- ARM中状态转移指令+条件执行+内存操作
- 8086汇编语言自学经验分享 T命令执行CS:IP所指内存的指令
- 自己动手写处理器之第一阶段(1)——计算机的简单模型、架构、指令集
- 菜鸟浅谈计算机中CPU、内存、硬盘和指令之间的关系
- 《大话处理器》连载——微架构(3) 从子弹射击到指令执行
- 共享内存—shmget参数shmflg详解—IPC_CREAT、IPC_EXCL、0666(对内存的读写执行权限)
- 计算机程序就是计算机执行指令的一个串行
- 工具接口标准(TIS)可执行链接格式(ELF)规范-卷II-处理器特性(Intel架构) (Processor Specific (Intel Architecture))
- 计算机的指令执行以及性能指标
- 计算机如何执行取数指令
- 计算机底层执行一条指令的过程
- CSAPP(3):处理器如何执行指令
- 计算机是如何区分读到的内存是指令还是数据
- 为什么 __start 是处理器执行的第一条指令?
- 计算机加电后执行的第一条指令
- 函数指针类的虚函数表是一块连续的内存,每个内存单元中记录一个JMP指令的地址。 注意的是,编译器会为每个有虚函数的类创建一个虚函数表,该虚函数表将被该类的所有对象共享。类的每个虚成员占据虚函数表中的一