轻量级网络:NetAdapt算法
《NetAdapt:Platform-Aware Neural Network Adaptation for Mobile Applications》这篇文章提出了一种新的网络压缩算法NetAdapt,它使用一个预训练好的模型在固定计算资源的手机平台上进行压缩试验,直接采集压缩之后的性能表现(计算耗时与功耗,文章称其为direct metrics)作为feedback,得到一系列满足资源限制、同时最大化精度的简化网络。
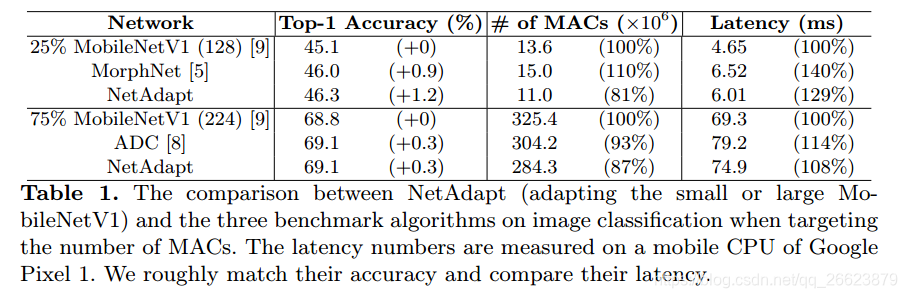
实验结果表明,与目前最先进的自动网络简化算法相比,NetAdapt在移动CPU和移动GPU上都能获得更好的精度和时延权衡。对于ImageNet数据集上的图像分类,NetAdapt在MobileNets(V1&V2)上以相同或更高的精度实现了1.7倍的测量推断加速。
动机
基于MAC或权重的数量等间接的网络压缩测量指标并不能很好反应实际上的性能表现,它们之间是存在高度的非线性关系并且依赖于使用的平台,下表展示了间接度量指标于实际性能表现的关系(间接指标好的不一定实际性能就好):

在设计高效的网络结构的时候一般有2种常用的方法:
- 不管所在的平台,统一设计单一的网络模型,但是这样会使得所设计的网络模型在不同的平台上表现就并不相同
- 在给定的平台硬件设备上手工设计对应的网络结构,这就需要了解详细的底层硬件知识,换了平台之后又得重新设计;
对于上面的两种网络设计的优缺点,文章提出了一种网络压缩的方法NetAdapt,它将优化之后的网络部署到设备上直接获取实际性能指标,之后再根据这个实际得到的性能指标指导新的网络压缩策略,从而以这样迭代的方式进行网络压缩,得到最后的结果,其算法流程见下图1所示:

NetAdapt在优化循环中包含了直接度量,因此它不受间接度量和直接度量之间的差异的影响。直接指标由目标平台的经验测量值进行评估。这使得算法能够在不了解平台本身的详细知识的情况下支持任何平台,而且相关知识仍然可以融入到算法中以进一步改进结果。
主要贡献
NetAdapt的网络优化以自动的方式进行,逐渐降低预训练网络的资源消耗,同时最大化精度。NetAdapt不仅可以生成一个满足预算的网络,而且可以生成一系列具有不同折衷程度的简化网络,从而实现动态的网络选择和进一步的研究。
- 在优化预先训练的网络以满足给定资源预算时使用直接度量的框架。经验测量用于评估直接度量,这样就不需要特定于平台的知识。
- 一种自动约束网络优化算法,在满足约束(即预定义的资源预算)的同时最大化精度。该算法在保证相同或更高精度的前提下,比目前最先进的自动网络简化算法减少了1.7倍的推理延迟。此外,还将生成一系列具有不同折衷的简化网络,以便进行动态的网络选择和进一步的研究。
- NetAdapt在不同平台和实时类网络(如小型MobileNetV1)上的有效性的实验,因为小型MobileNetV1比大型网络更难简化。
算法流程
在之前的研究中,优化策略给定一个目标函数(一般为分类网络的精度),在给定各个资源的限制条件,组成一个最优化表达式。这篇文章中对其进行了修改,使用迭代的方式进行优化,每次对应资源优化的步长为ΔRi,而文章对于网络的优化问题可以描述为下面迭代优化的形式:

具体的文章使用一个迭代的优化策略去优化这个目标函数,其算法流程如下:

另外一种更加直观的流程图方式见下图2所示:
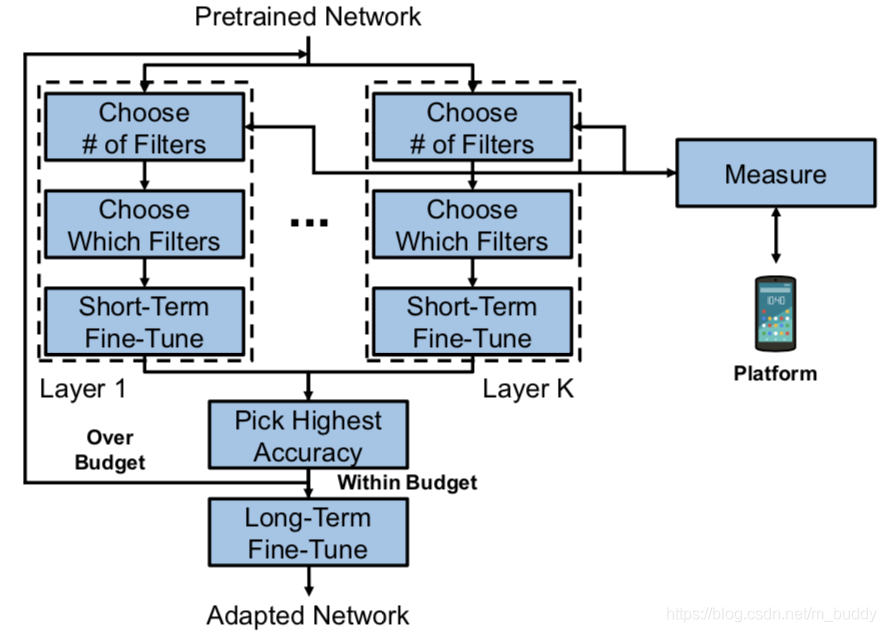
算法步骤
文章算法的核心在于如下步骤:
假设网络只需要满足一个资源的预算(延迟)。一种减少延迟的方法是从卷积(CONV)层或完全连接(FC)层移除滤波器。(虽然有其他方法可以减少延迟,但文章使用此方法测试NetAdapt。)
- step1:按照给定的资源约束选择当前层需要剪掉的filter数量,文章中是基于在实验平台上实验得到的结果进行选择剪裁的数量,在对应的filter被剪裁掉之后与之对应后续层的channel数也应做相应的修改;
注意:NetAdapt删除了整个filter,而不是单个权重,因为大多数平台都可以利用删除整个过滤器的优势,而且此策略允许同时减少filter和特征映射,这在资源消耗中起着重要作用。
- step2:在确定好需要剪裁掉的filter数量之后就需要确定哪些不重要的filter需要被剪裁掉。对此,文章使用的重要性选择方式是使用上一轮迭代产生的梯度信息,将其L2-norm,之后按照其值选择最不重要的几个将这些filter裁掉。除了这种基于梯度的方法还可以使用基于特征图间相互作用的方法,例如使用Lasso回归。
- step3:对当前裁剪的层进行short-term的finetune使其恢复精度。在所有的层完成裁剪之后选择其满足资源需求且finetune之后网络性能最好的一个;
- step4:判断当前迭代论述的模型是否满足算法预先设计的资源需求限制,若满足则对模型进行long-term的finetune得到最后的结果;
在每个迭代中,前三个步骤分别应用于每个CONV或FC层。NetAdapt在一次迭代中生成K个(即CONV层和FC层的数量)网络prosals,每个提案都有一个从上一次迭代修改的单层。具有最高精度的网络方案将被转移到下一个迭代(Pick-highest-accurious块)。最后,一旦达到目标预算,所选网络将再次微调,直到收敛(长期微调块)。
思考:文章的方法是在每个层上进行剪裁,也就是说每个层基本上是相互独立的,那么这样的方式结果是最优的吗?
快速资源消耗估计方法
对于修改之后网络直接在设备上运行,得到测量结果的资源消耗估计方法是相当耗时且代价高昂的,为此文章提出了一种资源消耗估计的方法用以解决这个问题。
- 预先统计每个层中资源消耗的数据得到一个查询表,
- 在进行裁剪的时候直接查表就可以得到是否满足对应的资源需求,如下图所示:

对于网络中具有相同filter shape和特征图尺寸的层来说,资源统计数据是可以共享的,这样可以减少部分建表时间。将通过表查询得到的结果于实际设备测量得到的实验结果进行比较其结果见下图所示:

3. 实验结果
Adapting Small MobileNetV1 on a Mobile CPU

Adapting Large MobileNetV1 on a Mobile CPU

Adapting Large MobileNetV1 on a Mobile GPU

Ablation Studies
Impact of Direct Metrics In
Impact of Short-Term Fine-Tuning

Impact of Long-Term Fine-Tuning

Impact of Resource Reduction Schedules

Analysis of Adapted Network Architecture

两个有趣的现象:
- 首先,NetAdapt在第7到10层中删除了更多的过滤器,但是在第6层中删除的更少。这是由于由于feature map的分辨率在layer 6中降低了,而在layer 7 - 10中没有降低,我们假设当feature map的分辨率降低时,需要更多的过滤器来避免造成信息瓶颈。
- 第二个观察结果是NetAdapt在第13层(即最后一个CONV层)保留了更多的过滤器。一种可能的解释是ImageNet数据集包含1000个类,因此最后的FC层需要更多的特征图来进行正确的分类
Adapting Large MobileNetV2 on a Mobile CPU


- 三款轻量级Linux 网络监视工具
- StyleMan_NetEngine 轻量级网络引擎 v1.0发表
- 轻量级网络:MobileNet系列V1、V2、V3
- 一个易用的轻量级的网络爬虫(Easy to use lightweight web crawler)
- 轻量级网络:ESPNet系列
- 优秀的轻量级网络开发框架spserver源码分析(一)
- 优秀的轻量级网络开发框架spserver源码分析(二)
- 轻量级网络--ShuffleNet论文解读
- 5个替代Apache和IIS的轻量级网络服务器
- 【论文】轻量级网络Mobilenet
- 一个轻量级网络通信开发库源码
- 轻量级网络:SqueezeNet、Xception
- 轻量级CNN网络之MobileNetv2
- android轻量级缓存框架ASimpleCache的使用 (网络请求数据并缓存)
- 自己动手写一个轻量级的Android网络请求框架
- Volley—轻量级HTTP客户端网络请求框架
- 继文章‘’ 自己动手写一个轻量级的Android网络请求框架‘’后续------增加缓存功能
- 轻量级网络
- 5个替代Apache和IIS的轻量级网络服务器
- iOS重构——轻量级的网络请求封装实践