高性能集群系统使用简易记录
集群系统通常使用SLURM作业调度脚本来提交、查看、修改作业。以下记录它的脚本与命令的编写与使用。
常用命令
以下是各种常用命令:
squeue #查看当前执行中的任务情况 sinfo #查看所有分区的情况 sacct #查看24小时内的历史任务 scancel job 56200 #取消id为56200的任务 scontrol show node #显示所有节点信息 scontrol show node node5 #显示节点5的信息
大型作业
对于大型作业,要把任务提交到服务器排队才能计算。所以要写任务脚本,提交任务的命令如下:
sbatch test.job
脚本实例如下:
#!/bin/bash #SBATCH --job-name=Helloworld ##作业的名称 #SBATCH --ntasks=1 ##总进程数,就是同样的作业要一起跑几个,一般炼丹一个就行了 #SBATCH --nodes=1 ##指定节点数量,一个进程只能分配给一个节点,不能分配给多节点多CPU运行 #SBATCH --ntasks-per-node=1 ##每个结点的进程数,一个进程那么每个结点进程数一定是1,不填也没事 #SBATCH --cpus-per-task=2 ##每个进程使用的CPU核心数,炼丹当然是越多越好,但是要的多分配的也慢 #SBATCH --partition=low ##使用哪个分区,可以sinfo看看有哪些分区 ##SBATCH --gres=gpu:1 ##指定GPU,不写就不分配 ##SBATCH --nodelist=node56 ##使用指定的节点,自己指定的话通常优先度会高一些,缺点就是即使别的节点空闲了也不会分配给你。当然节点要在上面指定的分区内部才行 #SBATCH --output=test.out ##标准输出的存放的文件,可以用%j表示任务ID #SBATCH --error=test.err ##错误提示的存放的文件 #SBATCH --qos=debug ##服务质量,debug就是交互式模式,分配资源少些,但是优先度高,另外还有normal普通模式,资源多但优先度低 source /public/home/chenqz/.bashrc ##要用的软件的环境变量,直接把用户的.bashrc给source了就好了 python3 test.py ##要执行的任务,看你终端所在的位置,如果已经在任务的文件夹中就不需要完整路径了,上面的123.out和.err也一样,都是输出到这一位置。
如果作业提交了想更改作业属性,当作业还没开始时,可以这样修改:
scontrol update jobid=56407 cpus-per-task=8 gres=gpu:1
交互式计算
直接进入计算节点
可以通过ssh从登陆节点访问计算节点(可能运维没有设置好,普通用户也能进。当然这样是不太好的,会影响别的用户作业)。首先要访问节点1,在节点1内才能访问其它计算节点:
ssh comput1 #进入节点1 ssh comput55 #进入节点1后,再进入其它节点,节点55
计算节点后可以直接在命令行执行代码,从而在计算节点运行。但是通常计算节点都是有人占用的,所以以这种未申请的方式使用计算节点计算效率不高。
但是,可以用sview看看有哪些空闲的节点,进去执行代码的话,速度就拉满了。为什么会空闲呢?我想可能因为有的人要申请很多资源,而集群只能一部分一部分分配,所以在他的资源完全准备好之前,这些空闲的节点我们就可以蹭蹭。然而,尽管一个节点CPU有28核,但没有GPU对于炼丹来说还是太慢了,而要用GPU资源还是得申请过才行。
集群只使用28核CPU跑VAE,18秒一次迭代,已经把CPU占满了:

Kaggle上GPU跑VAE,只要3秒一次迭代:

看来CPU和GPU差的还是太多了。
申请资源后再进入
申请资源后再以以上方式进入节点,就可以在比较好的资源下运行交互式代码。使用salloc命令,以下是实例:
salloc -J GoodJob -N 1 --cpus-per-task=8 -p low --qos=normal
各种参数格式如下(和上面的任务提交脚本类似,就是少了#SBATCH):
-J <任务名> #--job-name=<任务名> 的简写,下面一条-的都是简写,而且不用= -N <节点数量> #炼丹一般也就一个节点 --ntasks=<进程数> #炼丹就不需要了定义了,默认一个进程就够了 --ntasks-per-node=<单节点进程数> #一个进程的话也不需要定义这个了 --cpus-per-task=<单进程CPU核心数> --gres=gpu:<单节点 GPU 卡数> -p <使用的分区> --qos=<使用的 QoS>
申请后的资源也是以作业的形式占用,可以squeue查看:

看到申请的节点是58,然后进入这个节点,运行代码:
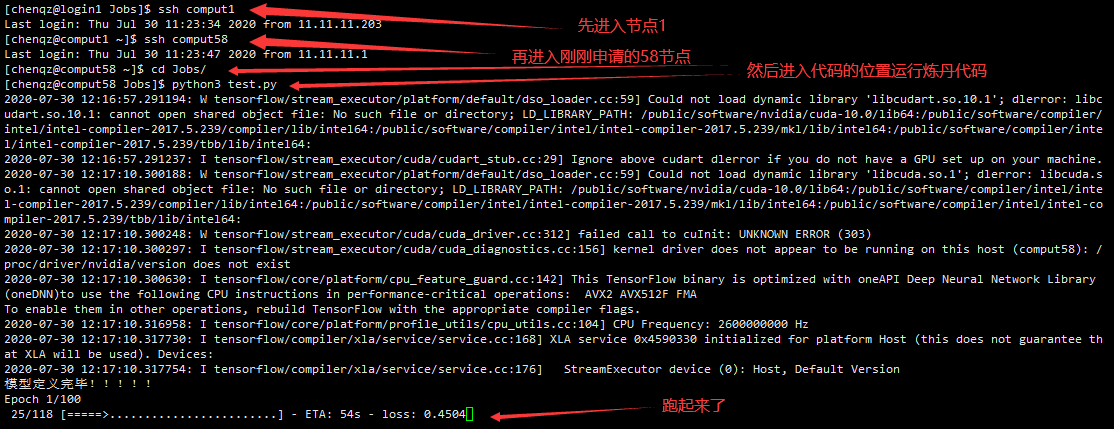
可以再开一个shell看看跑代码时的CPU占用:

占用率很高666.6%,而如果不申请的话,占用率不会超过10%。

- 【嵌入式系统学习记录】基于简易通讯录对指针、结构体、函数的使用体会
- 教你删除系统中U盘的使用记录
- 使用Jmail及Winwebmail发信时系统记录中的错误:502 Error: command ...
- Hi!欢迎使用一个Dynamo风格的分布式Redis集群分发管理系统WheatRedis - V2EX
- linux系统使用记录(1)
- 使用windows文件系统和字符I/O记录
- Django 中使用 logging 模块记录系统日志
- C# 系统应用之获取Windows最近使用记录
- 基于IA架构高性能集群系统技术
- Linux高性能集群 - 资源管理和系统管理
- 使用windows文件系统和字符I/O记录
- Python:通过自定义系统级快捷键来控制程序开始或停止记录日志(使用小技巧解决一个貌似无解的问题)
- 使用MPICH构建一个四节点的集群系统
- 在windows上使用symfony创建简易的CMS系统(三)
- 深入探讨在集群环境中使用 EhCache 缓存系统
- SQL Server使用系统表统计用户表的记录数
- 使用Cahce实现高性能系统
- 在J2ME中使用记录存储系统(RMS)存储信息
- 使用动态内存分配来消除使用变体记录造成的内存空间浪费(存货系统)
- 使用WSH和WMI实现定时记录系统CPU和内存使用率