径向基函数网络初认识
一种结构简单,收敛速度快,能够逼近任意非线性函数的网络——径向基网络(RBF).
径向基网络可以分为正则化网络和广义网络,其中广义网络在工程实践中被广泛应用,它可以由正则化网络稍加变化得到。
径向基函数
径向基函数记为:
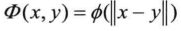
其中||x||指欧几里得范数。这里的欧几里得范数是作为自变量,也可以将其看成是复合函数。径向基函数必须满足:如果||x1||=||x2||,则
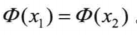
范数的概念:范数是对函数,向量和矩阵定义的一种度量形式,任何对象的范数都是一个非负的实数,若满足一下三条范数公理,即可成为一种范数: 非负性,即||x||>0 绝对齐性,即||ax||=|a|||x||,其中a为标量
常见的向量范数有p-范数,正无穷范数和负无穷范数

我们理解好这个便明白:
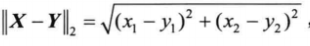
前辈们已经证明,在一定条件下,径向基
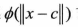
可以逼近几乎所有函数,这里c是一个固定的值,这样就把多元函数变成了一元函数。
有几种常见的径向基函数:
Gauss分布函数; Multi——quadric逆函数 薄板样条函数
正则化网络
对于一个正则化问题,它的解一般可由下式给出:
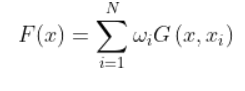
其中G是Green函数,Wi是权值。正则化网络是由三层组成的,第一层是由输入节点组成,输入节点的个数等于输入向量x的维数m。第二层为隐含层,隐含节点数等于输入训练样本的个数,第i个隐含节点的输出为:
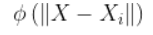
作为基函数。下面的式子
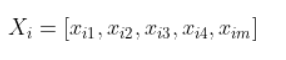
则为基函数的中心。输出层包括若干个线性单元,每个线性单元与所有隐含节点相连,这里的“线性”是网络最终的输出是各隐含点输出的线性加权和。
设实际输出为:
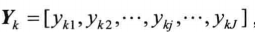
首先k表示的是网络的训练样本的序号,比如k=1,表示是一号样本。J则表示输出层神经元的个数。那么在训练k号样本时,网络输出神经元得到的结果是:
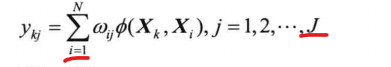
其中基函数可以选用Green函数,也可以选择高斯函数。
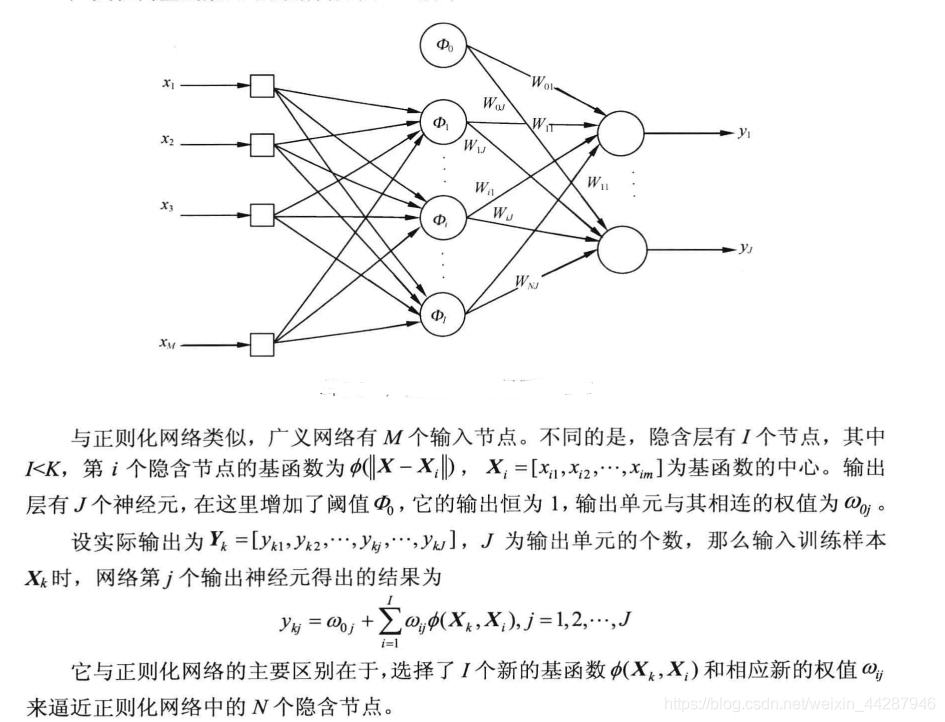
广义网络
正则化网络的弱点:
①因为隐含节点的个数等于输入训练样本的个数,因此如果训练样本的个数过大,网络的计算量将是惊人的,从而导致国底的效率;
②如果训练样本过大,那么计算权值时,需要计算的矩阵就会越大,那么它是病态矩阵的可能性会越高。矩阵病态是指,矩阵中的数据若有微小扰动会对结果产生很大的影响。
那么解决方案就是减少隐含层神经元的个数,此时求得的是较低维数空间的次优解。
学习算法
学习策略:
随机选取固定中心 自组织选取中心 有监督选取中心 正交最小二乘法
①随机选取固定中心
首先在径向基网络,需要训练的参数是:
隐含层中基函数的中心 隐含中基函数的标准差 隐含层与输出层间的权值 在随机选取固定中心的方法中,基函数的中心和标准差都是固定的,唯一需要训练的参数是隐含层与输出层之间的权值。
学习步骤:


总的来说就是d=GW 期望输出=理想权值乘以隐含层的输出
②自组织选取中心
自组织选取中心包括下面两个阶段:
①自组织学习阶段,估计初径向基函数的中心和标准差;
②有监督学习阶段,学习隐含层到输出层的权值
中心

标准差
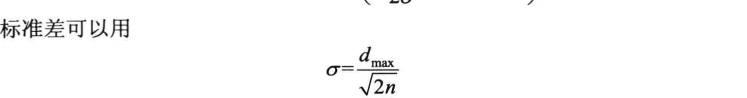
n为隐含节点的个数,dmax为所选取的聚类中心之间的最大距离。
同样地,这里的基函数一样选择使用高斯函数
学习权值

③有监督选取中心

④正交最小二乘法


广义回归神经网络
GRNN是径向基网络的另一种变形形式,GRNN建立在非参数回归的基础上,以样本数据为后延条件。执行Paezen非参数估计,依据最大概率原则计算网络输出。广义回归神经网络尤其适合解决曲线拟合的问题。广义回归网络不需要训练,但是从广义回归神经网络的理论基础中得知的是,光滑因子的值对网络性能影响很大,需要优化取值。对隐含层中所有的神经元采用相同的光滑因子,因子网络的训练过程只需要完成对光滑因子的一维寻优。
广义回归神经网络的结构
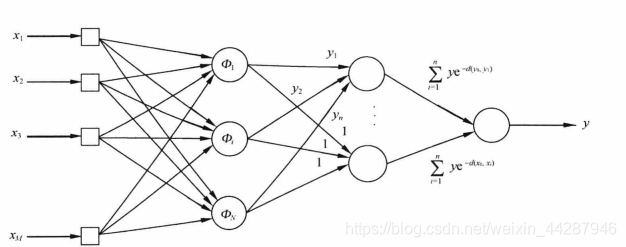
由四层网络构成,输入层,隐含层,加和层和输出层。
输入层接受样本的输入,神经元个数等于输入向量的维数,其传输函数是简单的线性函数。
隐含层是径向基层,神经元个数等于训练样本个数,基函数一般采用高斯函数,第i个神经元的中心向量为Xi,
加和层的神经元分为两种,一种是隐含层所有神经元输出的代数和,称为分母单元,另一种是隐含层的所有神经元输出的加权和,权值为个训练样本的期望输出值,称为分子单元。
输出层将分子单元与分母单元的输出相除,得到y的估算值。下式为理论式子
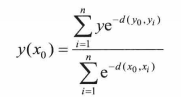
广义神经网络的建立过程比较简单:假设输入的第k个样本为Xk,样本数量为K,则隐含层含有K个神经元,且第k个隐含层神经元的中心就是Xk。隐含层每个神经元对应一个期望输出Yk,加和层第一个神经元的输出值y1等于隐含层的输出乘以YK后的和。加和层第二个神经元的输出值y2等于隐含层输出直接求和。输出层最终为y1/y2;
从广义神经网络中得到,隐含层中采用高斯函数,所以会具有一个平滑因子,采用缺一交叉验证方式来寻优。步骤如下:
①:设定一个平滑因子;
②:从样本中取出一个测试样本,其余样本作为训练样本,用于构建网络;
③:用构建的网络对该样本进行测试,求得绝对误差值;
④:重复第二步和第三步,直到所有的样本都曾被设置为测试样本,定义目标函数以求出平均误差:
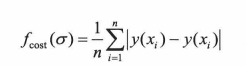
这样就可以求得给定平滑因子下的误差值,可以用此目标函数作为衡量平缓因子性能大的标准,寻优时可以采用简单的黄金分割法。
Matlab相关函数
我们也是先从matlab出发,然后再慢慢学习其原理。
net=newrb(P,T,goal,spread,MN,DF); P:输入矩阵; T:输出矩阵; goal:指定的均方误差; spread:径向基函数的扩散速度; MN:隐含节点的最大个数
spread的值需要针对具体问题灵活选择,对于变化较快的函数,如果spread取值过大,可能逼近的结果过于粗糙,对于变化缓慢的函数,spread如果取值过小,可能使逼近的函数不够光滑,造成过学习,从而降低了推广能力。
net=newrbe(P,T,spread) newrbe是创建一个严格的径向基网络,而newrb则是创建近似的径向基网络。使用newreb可以迅速创建一个误差为0的RBF网络。
A=radbas(N,FP); 径向基函数

Z=dist(W,p,FP); 欧几里得距离权函数 Z=dist(pos);


N=netprod({Z1,Z2,Z3,ZN}); 乘积网络输入函数
dist函数的作用是计算加权的输入,netprod函数则是计算网络的输入
Z=dotprod(W,P,FP); 内积权函数

N=netsum({Z1,Z2....Zn}) 求和网络输入函数

net=newgrnn(P,T,spread); 设计广义神经网络

Z=normprod(W,P,FP) 归一化点积权函数

总的来说,径向基网络包括广义神经网络的思路都是一致,
设置隐含层的中心点 使用径向基网络函数进行训练 再使用隐含层的输出乘上一个矩阵(权值或者直接是实际值) 最后使用相应的方法解出y
实例
异或问题
clear all close all clc x=[0 0; %输入向量为2维,样本个数为4 0 1; 1 1; 1 0;] t=[0 1; %隐含节点的中心 隐含节点有两个 随机选取中心 1 0;] z=dist(x,t); %计算输入向量到中心的距离 G=radbas(z); %将算的的距离输入径向基函数中 G=[G,ones(4,1)]; %加上偏置 d=[0 1 0 1]'; %期望输出 w=inv(G'*G)*G'*d; %求权值偏置 y=G*w %计算实际输出
曲线拟合问题——径向基网络和广义神经网络
x=-9:8; %输入向量为一维,有十八个样本数,所以隐含层节点个数为18; y=[129 -32 -118 -138 -125 -97 -55 -23 -4 2 1 -31 -72 -121 -142 -174 -155 -77]; %期望输入 t=x; %设置为隐含节点的中心 z=dist(x',t); % 计算每一个输入到每一个中心的距离,作为隐含层的输入 G=radbas(z); %计算隐含层的输出 d=y'; %期望输出 w=((inv(G'*G))*G')*d; %求权值偏置 Y=G*w %到此完成对径向基网络的建立,Y为训练后的值 %%%%%%%%%%%%%%%%%%%%%%%%然后我们测试一下这个径向基网络 x1=1:7; t=x; %径向基网络的各个隐含节点的中心不变。 zz=dist(x1',t);%计算测试样本的每一个输入到每一个中心的距离,作为测试时,隐含层的输入 7*18 GG=radbas(zz); %计算测试样本的隐含层的输出 Y1=GG*w %沿用网络权值矩阵得到实际输出值
%%function S =grnn_net(p,t,x,spread) %P是训练样本,x是测试样本
%%if ~exist('spread','var')
spread=0.1;
%%end
p=-9:8; %输入向量为一维,有十八个样本数,所以隐含层节点个数为18; size(p) 1 18
t=[129 -32 -118 -138 -125 -97 -55 -23 -4 2 1 -31 -72 -121 -142 -174 -155 -77]; %期望输入
x=1:5; %size(x) 1 7
[R,Q]=size(p); %R是指样本的维数
[R,S]=size(x); %S是指测试样本的个数
%%径向基层的输出
yr=zeros(Q,S); %Q是指样本个数
for i=1:S %s为实际的样本个数
for j=1:Q
v(j,i)=dist(x(:,i),p(:,j)); %p设为隐含层的中心节点 7*18
yr(j,i)=exp((-v(j,i)^2)/(2*spread^2)); %高斯函数 7*18
end
end
%%%%%%%%%%%
ya=zeros(2,S);
for i=1:S
ya(1,i)=t*yr(:,i); %隐含层的输出为列向量,一列对应一个测试样本,像左边这样乘,便能完成向结构图那样加法
ya(2,i)=sum(yr(:,i)); %将隐含层的输出为列向量,一列对应一个测试样本, 对每一列的输出进行求和。
end
Y=ya(1,:)./ya(2,:)
上面都是根据定义和公式写的函数,加深对这个网络的理解。
