浏览器网页爬虫如何使用HTTP
2020-07-24 16:12
441 查看
在进行网页爬虫的时候使用HTTP代理,可以进行匿名抓取网页信息,爬取大数据等使用方向。HTTP代理我们很了解,但是你有了解过HTTP协议是什么吗?HTTP协议即超文本传输协议,是Internet上信息传输时使用最为广泛的一种简单通信协议。部分局域网对协议进行了限制,当网站采取限制的时候可以使用代理ip进行反爬虫。
以使用IPIDEA为例进行http代理方式操作。
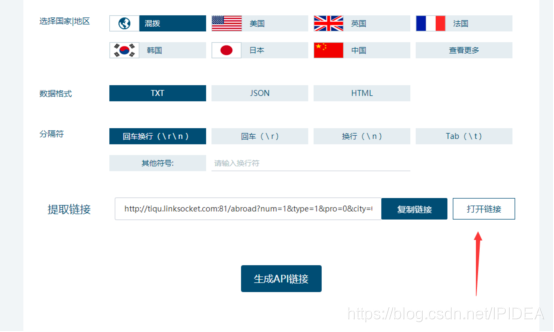
1.进入HTTP,生成api打开链接并复制
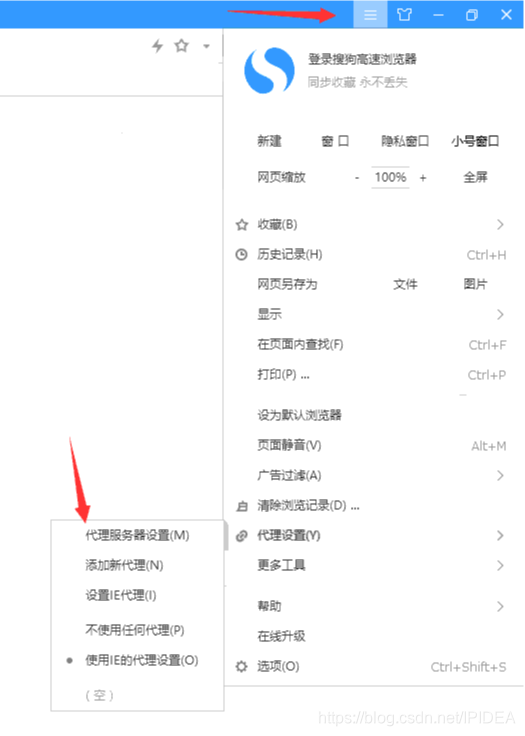
2.在搜狗浏览器右上角菜单列表内 - 代理设置 - 代理服务器设置
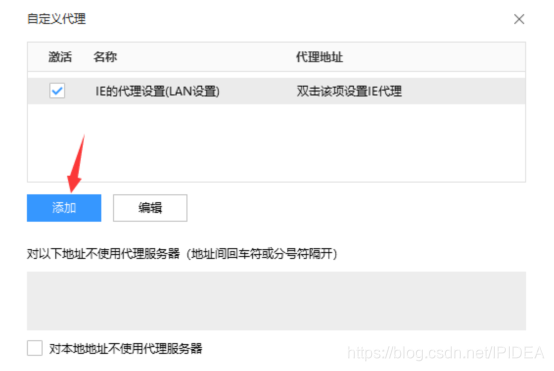
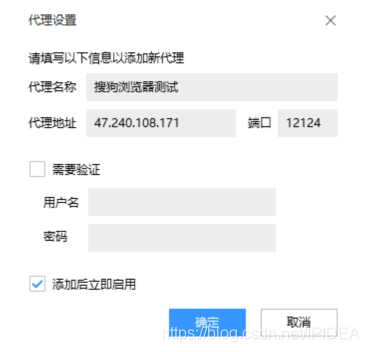
3.点击添加按钮,并填写在IPIDEA内提取复制的IP和端口号
4.打开百度查下IP,查看当前代理后的IP地址

相关文章推荐
- 使用 Apache HttpClient 工具模拟百度蜘蛛或浏览器抓取和解压gzip网页
- python爬虫(20)使用真实浏览器打开网页的两种方法
- C#如何使用HttpWebRequest、HttpWebResponse模拟浏览器抓取网页内容
- 05nodeJS常见API_http模块的小爬虫,如何做小爬虫,如何爬取别的网页的内容
- http如何使用POST,$ajax向provider传递数据并获取数据(以在浏览器上画圆为例)
- 爬虫如何使用HTTP?
- 如何使用xmlhttprequester对象,读取一个比较长的网页
- 如何使用Java语言实现一个网页爬虫
- 如何使用浏览器的网页全文翻译工具
- 如何使用API爬取数据,它和网页爬虫有什么区别?
- 如何使用指定浏览器打开网页
- IE10打开网页后,自动设置浏览器模式为“IE10兼容性视图”,我添加了 <meta http-equiv="X-UA-Compatible" content="IE=8">只修改了文档模式,请问如何
- 如何使用指定浏览器打开网页
- [引]ASP.NET 移动网页 与 如何:使用仿真程序和浏览器在部署移动 Web 应用程序之前对其进行测试
- [引]ASP.NET 移动网页 与 如何:使用仿真程序和浏览器在部署移动 Web 应用程序之前对其进行测试
- 如何使用指定浏览器打开网页
- 如何在使用 RemoteWebDriver 打开网页的同时获取 Http 状态码
- onerror 事件 如何使用 onerror 事件捕获网页中的错误。(chrome、opera、safari 浏览器不支持)
- HTTP基础(一):如何使用浏览器network查看请求和响应的信息
- python爬虫 使用真实浏览器打开网页的两种方法总结