论文导读|Representing Schema Structure with Graph Neural Networks for Text-to-SQL Parsing
论文导读|Representing Schema Structure with Graph Neural Networks for Text-to-SQL Parsing
作者:北京大学 常辰
编者按
在Text to SQL这一问题中,由于数据库模式(Database Schema)在训练以及测试时都是可见的,因此鲜有对其内含的信息进行进一步处理,该论文介绍了一种将数据库模式构筑成图的形式,并利用图神经网络(GNN)编码,以提升在更复杂的DB schema下的表现。
该论文的代码已开源:https://github.com/benbogin/spider-schema-gnn
1、背景知识
Text to SQL的目标是将一句自然语言转换为可执行的SQL查询语句,利用这个技术,即使不了解SQL的语法,仍然能够得到自己想要的查询结果。与其他语义解析(semantic parsing)任务一样,转换的目标语言具有较为严格的语法和逻辑结构,因此在语义解析的模型中,经常会使用GNN来捕捉结构信息,或者对输出加上一些语法的限制。但Text to SQL有所不同的一点是,数据库模式也会作为输入的一部分,或者说数据库模式也是生成SQL语句中不可或缺的信息。

数据库模式能够反映数据的结构及其联系,比如表的列名、列之间主外键的关系等等,因此数据库模式也会对SQL语句产生影响。在下图的两个例子中,问题的句式相似,但是由于数据库模式不同,作为结果的SQL语句也有很大的差距。
鉴于这一点,作者认为除了生成SQL时的语法限制之外,对数据库模式结构信息的编码也是十分必要的。
2、SQL生成语法
SQL语句有自己的一套编译规则,但是利用这些规则进行生成有两大弊端。第一是这些规则非常复杂,会使得生成的序列过长,同时也会包含不少冗余的生成步骤。第二则是这些规则并非上下文无关(context-free),同样会使生成过程变得十分复杂。

基于以上两点,作者首先构建了一套针对特定数据集(data-specific)的上下文无关语法(context-free grammar, CFG)。作者将设计的语法分为两类:全局规则(global rules)和链接规则(linked rules)。
全局规则是所有实例的生成过程中都可以使用的规则,如上图中这些生成规则都是全局规则,这些规则与数据库模式无关,类似于模板。

链接规则会根据问题和数据库模式生成,这些规则所生成的是表名、列名等数据库模式中的某一项,或者是问题中的某个词,因此这种规则对不同的问题也是不同的,类似于复制机制。

最后,只需要将利用这些规则得到的语法树深度优先遍历,就能得到生成的序列了。
3、利用GNN对数据库模式进行编码

首先需要将模式转换为图,以上图这个输入为例,涉及到的表有student, semester, student_semester, program这4个,很自然的一个想法是将表名和列名各自作为一个节点,并且将每个表的节点分别与其所有的列用双向边连接起来,作为第一类边;接下来再将主外键对和相应的表连接起来,以主键为起始点的边作为第二类边,以外键作为起始点的边作为第三类边,例如student.student_id-> student_semester. student_id和student-> student_semester是第二类边,反向则是第三类边,如下所示
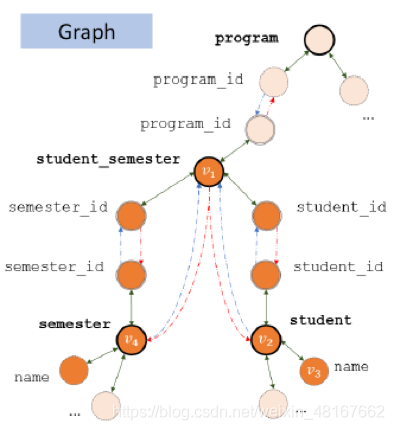
除此之外,根据实际的问题,并非图中所有的节点都需要用到,上图中只有深色的节点是实际需要的,为了能够反映每个节点与问题的相关度,需要学习模式项(schema item)v,即图中节点与问题中每个词xi的相关度Slink,并且通过softmax归一化得到一个概率分布

取其中最大的一个概率作为与问题的相关度

用这个相关度和初始embedding得到基于问题的embedding
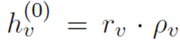
经过L层GNN得到每个节点最终的embedding
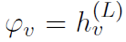
4、模型
与seq2seq模型类似,该模型由一个编码器和解码器组成,编码器为双向LSTM,解码器为LSTM。
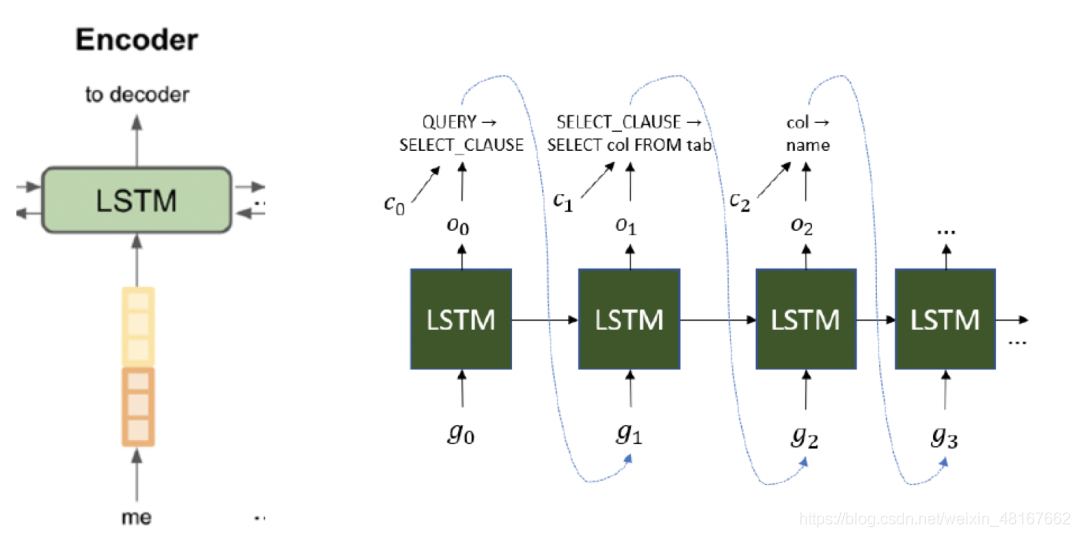
有所不同的是,在编码器的输入中加入了与数据库模式相关的embedding

在解码时临时将链接规则加入可用规则中,并且对之前几步解码中应用了链接规则的项使用self-attention,再计算得出可用规则集上的概率分布
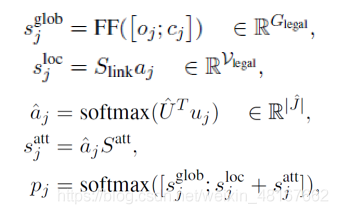
5、实验
本文中使用的数据集是近年Text to SQL任务中常用的SPIDER数据集,共有一万多条数据,并且有相对复杂的数据库模式。

实验结果如上图所示,即使不使用GNN对数据库模式进行编码,仍然有很大的提升,使用GNN后在跨表查询(即MULTI一列)中有很大提升。作者对两者输出的结果中,使用到”join”的部分进行了分析,不使用GNN时,有83.4%将同一张表join到了一起,或者是对非主外键对的两列错误地使用了join;而使用了GNN后这种错误仅有15.6%,从而一定程度上证明了利用了数据库模式的结构信息的模型在多表查询的情况下能有更好的表现。
最后,作者对这一模型所能达到的最佳状态作了一个估计,在计算图中节点与问题相关度时,把所有需要用到的节点相关度置为1,不相关的置为0,最终能达到54.3%的正确率,说明这一模型仍有提升的空间。
References
- Bogin, B., Gardner, M., & Berant, J. (2019). Representing Schema Structure with Graph Neural Networks for Text-to-SQL Parsing. ACL 2019.
- Lin, K., Bogin, B., Neumann, M., Berant, J., & Gardner, M. (2019). Grammar-based Neural Text-to-SQL Generation. ArXiv, abs/1905.13326.
- Yu, T., Zhang, R., Yang, K., Yasunaga, M., Wang, D., Li, Z., Ma, J., Li, I., Yao, Q., Roman, S., Zhang, Z., & Radev, D.R. (2018). Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. EMNLP 2018.

- 论文阅读:Reading Text in the Wild with Convolutional Neural Networks
- 论文阅读:Reading Text in the Wild with Convolutional Neural Networks
- 论文笔记 Ensemble of Deep Convolutional Neural Networks for Learning to Detect Retinal Vessels in Fundus
- 论文《Recurrent Convolutional Neural Networks for Text Classification》总结
- An End-to-End System for Unconstrained Face Verification with Deep Convolutional Neural Networks
- Effective Use ofWord Order for Text Categorization with Convolutional Neural Networks(阅读理解)
- 论文阅读:End-to-End Learning of Deformable Mixture of Parts and Deep Convolutional Neural Networks for H
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
- StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 论文笔记
- Deep Neural Networks for Learning Graph Representations论文笔记
- Data-Driven Sparse Structure Selection for Deep Neural Networks 论文翻译
- 【论文笔记】Sequence to sequence Learning with Neural Networks
- Knowledge-aware Graph Neural Networks with Label Smoothness Regularization for Recommender Systems
- Sequence to Sequence Learning with Neural Networks论文阅读
- Training Neural Networks with Weights and Activations Constrained to +1 or -1论文阅读
- Learning Convolutional Neural Networks for Graphs 论文笔记
- Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes
- Image-to-Image Translation with Conditional Adversarial Networks 论文翻译
- 斯坦福大学 CS231n 视觉识别卷积神经网络 - Introduction to Convolutional Neural Networks for Visual Recogntion-2
- 论文笔记——MobileNets(Efficient Convolutional Neural Networks for Mobile Vision Applications)