python基础教程
Python基础教程
一、简介
1.1 python语言介绍
python的创始人:Guido Van Rossum
Python下载地址:https://www.python.org/
Python文档下载地址:https://www.python.org/doc/
Pycharm下载地址:https://www.runoob.com/w3cnote/pycharm-windows-install.html
Linux安装包下载地址:https://www.python.org/downloads/source/
1.2 Python2 vs python 3
(1) python3.X默认支持中文
(2) python3.X不兼容python2.X
(3) python3.X核心语法调整、更易学
(4) 新特性默认只在python3.X 上面有
1.3 编程语言介绍
编程语言主要从以下几个角度进行分类:编译型,静态型,动态性,强类型定义语言和弱类型定义语言
1.3.1 编译型:
有一个负责翻译的程序来对我们的源代码进行转换,生成对应的可执行代码,这个过程就是编译,而负责编译的程序就被称为Compiler
1.3.2 动态型:
是指在运行期间采取做数据类型检查的语言。即在用动态类型的语言编程时,永远也不用给任何变量指定数据类型,该语言会在你第一次赋值给变量时,在内部将数据类型记录下来。典型的是python和Ruby
1.3.3静态型:
数据类型是在编译期间检查的,也就是说在写程序的时候要声明所有变量的数据类型。C/C++是静态类型语言的典型代表,其他的静态类型语言还有C#,JAVA
1.4 python是一门什么样的语言
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。
1.4.1 解释型语言
这意味着开发过程中没有了编译这个环节。类似于PHP和Perl语言
1.4.2 交互式语言
这意味着,您可以在一个 Python 提示符 >>> 后直接执行代码。
1.4.3 面向对象语言
这意味着Python支持面向对象的风格或代码封装在对象的编程技术。
1.4.4 初学者的语言
Python 对初级程序员而言,是一种伟大的语言,它支持广泛的应用程序开发,从简单的文字处理到 WWW 浏览器再到游戏。
1.5 python能在做什么
网络应用、科学运算、GUI程序、系统管理工具、其他等等
1.6 python特点
1.6.1 特点
(1)易于学习:Python有相对较少的关键字,结果简单,和一个明确定义的语法,学习起来更加简单
(2)易于阅读:Python代码定义的更清晰
(3)易于维护:Python的成功在于它的源代码是相当同意维护的
(4)一个广泛的标准库:Python的最大的优势之一是丰富的库,跨平台的,在Unix、Windows和macintosh兼容很好
(5)互动模式:互动模式的支持,您可以从终端输入执行代码并获得结果的语言,互动的测试和调试代码片段
(6)可移植:基于其开放源代码的特性,Python已经被移植(也就是使其工作)到许多平台
(7)可扩展:如果你需要一段很快的关键代码,或者是想要编写一些不愿开放的算法,你可以使用C或C++完成那部分程序,然后你的Python程序中调用
(8)数据库:Python提供所有主要的商业数据库的接口
(9)GUI编程:Python支持GUI可以创建和移植到许多系统调用
(10)可嵌入:你可以将Python嵌入到C/C++程序,让你程序的用户获得“脚本化”的能力
1.6.2 优点
简单、开发效率高、高级语言、可移植性、可扩展性、可嵌入型
1.6.3 缺点
速度慢、但是相对的、代码不能加密、线程不能利用多CPU问题
1.7 python解释器
Cpython、IPython、PyPy、Jython、IronPython
二、安装
Linux、 windows、 pycharm安装
三、入门
3.1 字符编码
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)。
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode。
**
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。
**Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多。
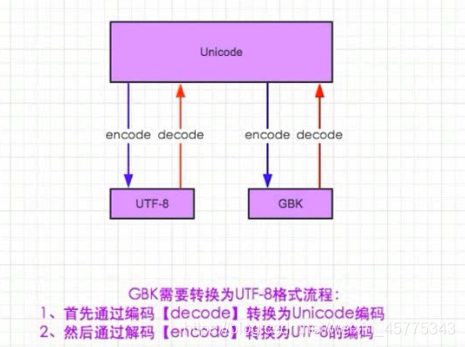
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存…
python2.x版本,默认支持的字符编码为ASCll,python3.x版本,默认支持的是Unicode,不用声明字符编码可以直接显示中文
3.2 注释
单行注释:# 单行注释
多行注释:(1)""" 多行注释 “”" or ‘’’ 多行注释 ‘’’
3.3 关键字
python一些具有特殊功能的标示符,这就是所谓的关键字
关键字,是python已经使用的了,所以不允许开发者自己定义和关键字相同的名字的标示符
and as assert break class continue def del elif else except exec finally for from global if in import is lambda not or pass print raise return try while with yield
可以通过下面的方式查看关键字
import keyword print(keyword.kwlist)
3.4 格式化输出
age = 22
print('我今年%d岁'%age)
Result:我今年22岁
3.4.2 常用的格式化输出
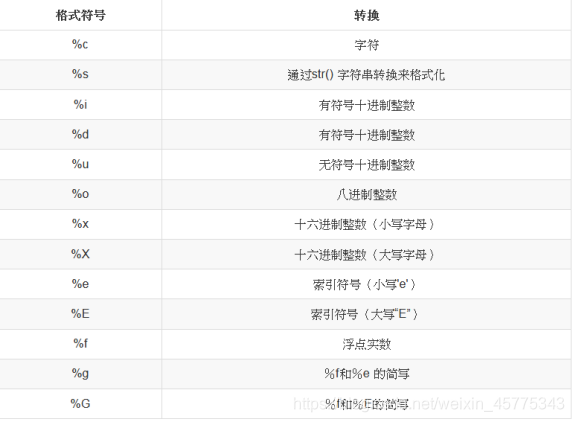
3.5 变量
Python只有变量,没有常量;
全部大写是常量,但是value依然可以修改,只不过是大写来代表常量。
3.5.1 变量的命名的规则
(1)要具有描述性
(2)变量名只能是字母、数字或下划线的任意组合,不能以空格或特殊字符(#?<.,$¥*!~)
(3)不能以中文为变量名
(4)不能以数字,空格开头
(5)不能以大写字母开头(全部大写字母在python里面代表常量)
(6)保留字符(关键字)不能被声明为变量名
3.5.2 变量定义
(1)每个变量在内存中创建,都包括变量的标识,名称和数据这些信息;
(2)每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建;
(3)等号(=)用来给变量赋值;
(4)等号(=)运算符左边是一个变量名,等号(=)运算符右边是存储在变量中的值
3.5.3 变量内存释放
Python中有垃圾回收机制机制,会过一段时间,将不再使用的变量自动清空掉,不需要人为的去清空,当然也可以人为的清空,人为清空是这个变量就真的被清空了,而python垃圾回收机制,是将不用的变量指向了另外一个变量。
3.5.4 变量类型
变量类型种类分为:变量赋值、多个变量赋值、标准数据类型、python数字、python字符串、python列表、python元组、python字典、python数据类型转换。
3.5.4.1 变量赋值
Python 中的变量赋值不需要类型声明。
每个变量在内存中创建,都包括变量的标识,名称和数据这些信息。
每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
等号(=)用来给变量赋值。
等号(=)运算符左边是一个变量名,等号(=)运算符右边是存储在变量中的值。
例如:
| 实例 | 结果 |
|---|---|
| counter = 100 # 赋值整型变量 | |
| miles = 1000.0 # 浮点型 | |
| name = “John” # 字符串 | |
| Print(counter) | 100 |
| Print(miles) | 1000.0 |
| Print(name) | John |
3.5.4.2 多个变量赋值
Python允许你同时为多个变量赋值。例如:
a = b = c = 1
以上实例,创建一个整型对象,值为1,三个变量被分配到相同的内存空间上。
您也可以为多个对象指定多个变量。例如:
a, b, c = 1, 2, "john"
以上实例,两个整型对象 1 和 2 分别分配给变量 a 和 b,字符串对象 “john” 分配给变量 c。
3.5.4.3 标准数据类型
在内存中存储的数据可以有多种类型。
例如,一个人的年龄可以用数字来存储,他的名字可以用字符来存储。
Python 定义了一些标准类型,用于存储各种类型的数据。
Python有五个标准的数据类型:
- Numbers(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dictionary(字典)
3.5.4.4 python数字
Python支持四种不同的数字类型:
- int(有符号整型)
- long(长整型[也可以代表八进制和十六进制])
- float(浮点型)
- complex(复数)
| int | long | float | complex |
|---|---|---|---|
| 10 | 51924361L | 0.0 | 3.14j |
| 100 | -0x19323L | 15.20 | 45.j |
| -786 | 0122L | -21.9 | 9.322e-36j |
| 080 | 0xDEFABCECBDAECBFBAEl | 32.3e+18 | .876j |
| -0490 | 535633629843L | -90. | -.6545+0J |
| -0x260 | -052318172735L | -32.54e100 | 3e+26J |
| 0x69 | -4721885298529L | 70.2E-12 | 4.53e-7j |
- 长整型也可以使用小写 l,但是还是建议您使用大写 L,避免与数字 1 混淆。Python使用 L 来显示长整型。
- Python 还支持复数,复数由实数部分和虚数部分构成,可以用 a + bj,或者 complex(a,b) 表示, 复数的实部 a 和虚部 b 都是浮点型。
注意
long 类型只存在于 Python2.X 版本中, 在 2.2 以后的版本中,int 类型数据溢出后会自动转为long类型; 在 Python3.X 版本中 long 类型被移除,使用 int 替代。
3.5.4.5 python字符串
python的字串列表有2种取值顺序:
- 从左到右索引默认0开始的,最大范围是字符串长度少1
- 从右到左索引默认-1开始的,最大范围是字符串开头
如果你要实现从字符串中获取一段子字符串的话,可以使用 [头下标:尾下标] 来截取相应的字符串,其中下标是从 0 开始算起,可以是正数或负数,下标可以为空表示取到头或尾。
[头下标:尾下标] 获取的子字符串包含头下标的字符,但不包含尾下标的字符。
当使用以冒号分隔的字符串,python 返回一个新的对象,结果包含了以这对偏移标识的连续的内容,左边的开始是包含了下边界。
上面的结果包含了 s[1] 的值 b,而取到的最大范围不包括尾下标,就是 s[5] 的值 f。
加号(+)是字符串连接运算符,星号(*)是重复操作。如下实例:

Python 列表截取可以接收第三个参数,参数作用是截取的步长,以下实例在索引 1 到索引 4 的位置并设置为步长为 2(间隔一个位置)来截取字符串:
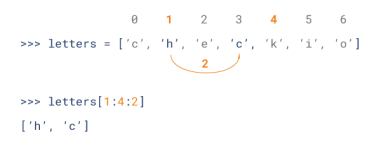
常用方式
str = 'abcdef'
print(str[1:5]) # 根据下标获取到值
print(Str[1:-5]) # 根据下标获取到值
print(str) # 输出完整字符串
print(str[0]) # 输出字符串中的第一个字符
print(str[2:5]) # 输出字符串中第三个至第六个之间的字符串
print(str[2:]) # 输出从第三个字符开始的字符串
print(str + "TEST") # 输出拼接的字符串
print(Str[1:4:2]) # 输出第一个到第四个,步长为2的字符
print('hello' * 2) # 打印字符串两次
print('helloWorld'[2:]) # 根据下标获取到值
print('lll' in 'helloWorld') # 判断某个值是否存在某个字符串中
print('lll' in ['helloWorld', 12, 'lll']) # 判断某个值是否存在某个列表中
print('%s is a good teacher!!!'%'allure') # 格式化输出 %s
# 字符串拼接
a = '111'
b = '222'
d = 'abc'
c = a + b # 方法一
print(c)
c = ''.join([a, b, d]) # 方法二
print(c)
String内置方法
str = "hello kitty {name} age is {age} years"
# print(str.copy()) # capy一份数据
# print(str.count('l')) # 查看str中某个元素的个数
# print(str.capitalize()) # 将字符串的首字母大写
# print(str.center(50, '-')) # 将字符串居中
# print(str.endswith('y')) # 判断以某个字符串内容结尾,返回True or False print(str.endswith('y', 10, 11))
# print(str.startswith('h', 0, 1)) # 判断以某个字符串内容开始,返回True or False print(str.startswith('h'))
# print(str.expandtabs(tabsize=10)) # str = "he\tllo kitty" 设置空格,平日是 '\t' 使用
# print(str.find('t')) # 查找到第一个元素,并将其索引值返回
# print(str.format(name = 'allure', age = '24')) # 常用语格式化输出,配置str = "hello kitty {name} age is {age} years"使用
# print(str.format_map({'name': 'allure', 'age': '24'})) # 常用语格式化输出,配置str = "hello kitty {name} age is {age} years"使用
# print(str.index('t')) # 等同于str.find('t'),找不到会报错,find不会返回 -1
# print(str.isdigit()) # 判断str是否是整数
# print(str.isalnum()) # 判断str是否是包含数字和字母的字符串
# print('B13445579880011001'.isdecimal()) # 判断str是不是十进制的数
# print(str.isnumeric()) # 等同于isdigit,没有区别
# print('12adf'.isidentifier()) # 判断str是不是非法变量
# print(str.islower()) # 判断str是否都是小写
# print(str.isupper()) # 判断str是否都是大写
# print(str.isspace()) # 判断str是否是一个空格
# print('Hello Kitty'.istitle()) # 判断str是否是一个标题,字符每个单词的首字母必须是大写
# print(''.join(['12', '34', '56'])) # 字符串拼接
# print(str.lower()) # 将字符的所有大写变成小写
# print(str.upper()) # 将字符的所有小写变成大写
# print(str.swapcase()) # 将字母的大小写反转
# print(str.ljust(50, '*')) # 将占位符放在右边
# print(str.rjust(50, '*')) # 将占位符放在左边
# print(' dfa afd adsf \n'.strip()) # 将字符串两边的空格(' '、\t、\n)换掉
# print(' dfa afd adsf \n'.ltrip()) # 将字符串左边的空格(' '、\t、\n)换掉
# print(' dfa afd adsf \n'.rtrip()) # 将字符串右边的空格(' '、\t、\n)换掉
# print('afsda'.replace('a', '123', 1)) # 将某个字符串替换为想要替换的,参数1:要替换的内容,参数2:替换后的内容,参数3:替换几个值
# print('a b c d e f'.split(' ')) # 分隔
# print(str.rsplit('i')) # 从右往左,开始分隔,只分割一次
# print(str.title()) # 将字符串转换为标题格式
# 将列表整合为字符串
a = ['a', 'b', 'c', 'd', 'e', 'f']
print(''.join(a))
常用的String内置函数
# print(str.copy()) # capy一份数据
# print(str.count('l')) # 查看str中某个元素的个数
# print(str.capitalize()) # 将字符串的首字母大写
# print(str.center(50, '-')) # 将字符串居中
# print(str.endswith('y')) # 判断以某个字符串内容结尾,返回True or False print(str.endswith('y', 10, 11))
# print(str.startswith('h', 0, 1)) # 判断以某个字符串内容开始,返回True or False print(str.startswith('h'))
# print(str.find('t')) # 查找到第一个元素,并将其索引值返回
# print(str.format(name = 'allure', age = '24')) # 常用语格式化输出,配置str = "hello kitty {name} age is {age} years"使用
# print(str.index('t')) # 等同于str.find('t'),找不到会报错,find不会返回 -1
# print(str.isdigit()) # 判断str是否是整数
# print(str.isalnum()) # 判断str是否是包含数字和字母的字符串
# print(str.lower()) # 将字符的所有大写变成小写
# print(str.upper()) # 将字符的所有小写变成大写
# print('a b c d e f'.split(' ')) # 分隔
# print('afsda'.replace('a', '123', 1)) # 将某个字符串替换为想要替换的,参数1:要替换的内容,参数2:替换后的内容,参数3:替换几个值
# print(' dfa afd adsf \n'.strip()) # 将字符串两边的空格(' '、\t、\n)换掉
3.5.4.6 python列表
code详见:
D:\code\PycharmProjects\pythonProject\pythonBase\列表.py
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串甚至可以包含列表(即嵌套)。
列表用 [ ] 标识,是 python 最通用的复合数据类型。
列表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表,从左到右索引默认 0 开始,从右到左索引默认 -1 开始,下标可以为空表示取到头或尾。

3.5.4.7 集合set
code详见:
D:\code\PycharmProjects\pythonProject\pythonBase\集合.py3.5.4.7.1 定义:
把不同的元素组成一起形成集合,是python基本的数据类型。
集合是一个无序的,不重复的数据组合,它的主要作用如下:
(1)去重,把一个列表变成集合,就自动去重了
(2)关系测试,测试两组数据之前的交集、差集、并集等关系
集合元素(set elements):组成集合的成员(不可重复)
li=[1,2,'a','b']
s =set(li)
print(s) # {1, 2, 'a', 'b'}
li2=[1,2,1,'a','a']
s=set(li2)
print(s) #{1, 2, 'a'}
集合对象是一组无序排列的可哈希的值:集合成员可以做字典的键
li=[[1,2],'a','b'] s =set(li) #TypeError: unhashable type: 'list' print(s)3.5.4.7.2 集合分类:可变集合、不可变集合
可变集合(set)
可添加和删除元素,非可哈希的,不能用作字典的键,也不能做其他集合的元素
不可变集合(frozenset)
与上面恰恰相反
li=[1,'a','b']
s =set(li)
dic={s:'123'} #TypeError: unhashable type: 'set'
3.5.4.7.3 集合的相关操作
(1)创建集合
由于集合没有自己的语法格式,只能通过集合的工厂方法set()和frozenset()创建
s1 = set('alvin')
s2= frozenset('yuan')
print(s1,type(s1)) #{'l', 'v', 'i', 'a', 'n'} <class 'set'>
print(s2,type(s2)) #frozenset({'n', 'y', 'a', 'u'}) <class 'frozenset'>
(2)访问集合
由于集合本身是无序的,所以不能为集合创建索引或切片操作,只能循环遍历或使用in、not in来访问或判断集合元素。
s1 = set('alvin')
print('a' in s1) # True
print('b' in s1) # False
#s1[1] #TypeError: 'set' object does not support indexing
for i in s1:
print(i)
result:a n i L v
(3)更新集合
s.add(’’):添加数据,完整的String
s.update(’’):添加数据,拆分成char
s.remove(’’):删除一个char数据
s.pop():随机删除一个String数据
s.clear():清空集合
del(s):删除集合本身
s1 = set('alvin')
# print('a' in s1)
# print('b' in s1)
# for i in s1:
# print(i)
s1.add('abc') # 添加数据,完整的String
s1.update('abc') # 添加数据,拆分成char
s1.remove('l') # 删除一个char数据
s1.pop() # 随机删除一个String数据
s1.clear() # 清空集合
del(s1) # 删除集合本身
print(s1)
(4)集合类型操作符
1)in ,not in
2)集合等价与不等价(==, !=)
3)子集、超集
a = set([1, 2, 3, 4, 5]) b = set([4, 5, 6, 7, 8]) print(a.issuperset(b)) # False print(a.issubset(b)) # False print(a > b) # False
4)并集(|)
并集(union)操作与集合的or操作其实等价的,联合符号有个等价的方法,union()
a = set([1, 2, 3, 4, 5])
b = set([4, 5, 6, 7, 8])
print(a | b) # {1, 2, 3, 4, 5, 6, 7, 8}
print(a.union(b)) # {1, 2, 3, 4, 5, 6, 7, 8}
5)交集(&)
与集合and等价,交集符号的等价方法是intersection()
a = set([1, 2, 3, 4, 5])
b = set([4, 5, 6, 7, 8])
print(a.intersection(b)) # {4, 5}
print(a & b) # {4, 5}
6)差集(-)
等价方法是difference()
a = set([1, 2, 3, 4, 5])
b = set([4, 5, 6, 7, 8])
print(a.difference(b)) # {1, 2, 3} in a but not in b
print(a - b) # {1, 2, 3} in a but not in b
7)对称差集(^)
对称差集是集合的XOR(‘异或’),取得的元素属于s1,s2但不同时属于s1和s2.其等价方法symmetric_difference()
a = set([1, 2, 3, 4, 5])
b = set([4, 5, 6, 7, 8])
print(a.symmetric_difference(b)) # {1, 2, 3, 6, 7, 8}
print(a ^ b) # {1, 2, 3, 6, 7, 8}
8)应用
'''最简单的去重方式''' lis = [1,2,3,4,1,2,3,4] print list(set(lis)) #[1, 2, 3, 4]
3.5.4.7 python元组
元组是另一个数据类型,类似于 List(列表)。
元组用 () 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表。
tuple = ( 'runoob', 786 , 2.23, 'john', 70.2 ) tinytuple = (123, 'john') print(tuple) # 输出完整元组 print(tuple[0]) # 输出元组的第一个元素 print(tuple[1:3]) # 输出第二个至第四个(不包含)的元素 print(tuple[2:]) # 输出从第三个开始至列表末尾的所有元素 print(tuple[0:4:2])# 输出从第一个至第四个,步长为2的元素 print(tinytuple * 2) # 输出元组两次 print(tuple + tinytuple) # 打印组合的元组
3.5.4.8 python字典
字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据。python对key进行哈希函数运算,根据计算的结果决定value的存储地址,所以字典是无序存储的,且key必须是可哈希的。可哈希表示key必须是不可变类型,如:数字、字符串、元组。
字典(dictionary)是除列表意外python之中最灵活的内置数据结构类型。列表是有序的对象结合,字典是无序的对象集合。
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典用"{ }"标识。字典由索引(key)和它对应的值value组成。
code详见:
D:\code\PycharmProjects\pythonProject\pythonBase\字典.py
创建字典
# 创建方式一
dic = {'name': 'allure', 'age': 23, 'hobby': 'girl', 'sex': 'man'}
print(dic)
dic = {'name': 'allure', 'age': 23, 'hobby': {'girl_name': 'Alice', 'girl_age': 24}, 'sex': 'man'}
print(dic['hobby'])
# 创建方式二
dic2 = dict((('name', 'allure'), ('age', 23)))
print(dic2)
# 创建方式三
dic3 = dict((['name', 'allure'], ['age', 23]))
print(dic3)
# 创建方式三
dic4 = dict([['name', 'allure'], ['age', 23]])
print(dic4)
对应操作
增加
dic1 = {'name': 'allure'}
print(dic1)
# dic1['name'] = 18 # 如果键存在,直接修改,否则追加
dic1['age'] = 18
# setdefault:键存在,返回字典中相应的建对应的值
res1 = dic1.setdefault('age',34)
print(res1)
# setdefault:键不存在,在字典里增加新的键值对,并返回相应的值
res2 = dic1.setdefault('hobby','girl')
print(res2)
print(dic1)
查询
dic = {'name': 'allure', 'age': 23, 'hobby': 'girl', 'sex': 'man'}
# 查询全部
print(dic)
# 通过键去查找
print(dic['name'])
# 查询字典中所有的键
print(dic.keys()) # 返回的是一个keys类型 type(dic.keys)
print(type(dic.keys)) # 返回的是一个 dict_keys
print(list(dic.keys())) # 将 dict_keys 类型转换为 list 类型
# 查询字典中所有的值
print(dic.values()) # dict_values
print(type(dic.values())) # 返回的是一个 dict_values
print(list(dic.values())) # 将 dict_values 类型转换为 list 类型
# 查询字典中所有的键值对
print(dic.items()) # 返回的是一个 dict_items 类型的键值对
修改
dic = {'name': 'allure', 'age': 23, 'hobby': 'girl', 'sex': 'man'}
print(dic)
dic['name'] = 'Alice'
print(dic)
dic2 = {'name': 'jack', 'age': 55, 'hobby': 'boy', 'sex': 'failman', 'classId': '20200110'}
dic.update(dic2)
print(dic)
删除
dic = {'name': 'allure', 'age': 23, 'hobby': 'girl', 'sex': 'man'}
print(dic)
del dic['name'] # 删除字典中指定的键值对
print(dic)
dic.clear() # 清空字典
print(dic)
dic.pop('age') # 删除字典中指定的键值对,并返回该键值对中的值
print(dic)
dic.popitem() # 随机删除某组键值对,并以元组方式返回值,没有用
print(dic)
del dic # 删除整个字典
一些常用的其他操作以及涉及到的方法
dict.fromkeys
dic = dict.fromkeys(['host1', 'host2', 'host3'], 'test')
print(dic) # {'host1': 'test', 'host2': 'test', 'host3': 'test'}
dic['host2'] = 'hello'
print(dic) # {'host1': 'test', 'host2': 'hello', 'host3': 'test'}
dic = dict.fromkeys(['host1', 'host2', 'host3'], ['test1', 'test2'])
print(dic) # {'host1': ['test1', 'test2'], 'host2': ['test1', 'test2'], 'host3': ['test1', 'test2']}
dic['host2'] = ['test1', 'test3'] # {'host1': ['test1', 'test2'], 'host2': ['test1', 'test2'], 'host3': ['test1', 'test2']}
dic['host2'][1] = 'test3' # {'host1': ['test1', 'test3'], 'host2': ['test1', 'test3'], 'host3': ['test1', 'test3']}
print(dic)
字典嵌套
av_catalog = {
"欧美":{
"www.youporn.com": ["很多免费的,世界最大的","质量一般"],
"www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"],
"letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"],
"x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"]
},
"日韩":{
"tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"]
},
"大陆":{
"1024":["全部免费,真好,好人一生平安","服务器在国外,慢"]
}
}
av_catalog['欧美']['www.youporn.com'][1] = ['质量高清']
print(av_catalog)
d.copy():对字典 d 进行浅复制,返回一个和d有相同键值对的新字典
# copy():对字典 d 进行浅复制,返回一个和d有相同键值对的新字典 av_catalog_copy = av_catalog.copy() print(av_catalog_copy)
sorted(dict) : 返回一个有序的包含字典所有key的列表
dic = {5: '555', 2: '222', 4: '444'}
sort_res1 = sorted(dic.items()) # 根据key排序,返回键值对
sort_res2 = sorted(dic.keys()) # 根据key排序,返回key
sort_res3 = sorted(dic.values()) # 根据value排序,返回value
print(sort_res1)
print(sort_res2)
print(sort_res3)
字典遍历(通过 for 循环打印字典,3种方式)
# 通过 for 循环打印字典,3种方式
dic = {'name': 'allure', 'age': 23, 'hobby': 'girl', 'sex': 'man'}
# 效率最高
for i in dic:
print(i, dic[i])
# 效率低,有一部转换操作
for i in dic.items():
print(i)
# 效率低,有一部转换操作
for i, v in dic.items():
print(i, v)
3.9 编码
详情见:https://www.geek-share.com/detail/2792681722.html
四、文件流
4.1 文件操作
文件准备
昨夜寒蛩不住鸣。 惊回千里梦,已三更。 起来独自绕阶行。 人悄悄,帘外月胧明。 白首为功名,旧山松竹老,阻归程。 欲将心事付瑶琴。 知音少,弦断有谁听。
4.1.1 读取文件
"""
# 读取文件
1、打开文件
2、读取文件
3、关闭文件
open:
参数1:文件名称
参数2:操作名称
参数3:编码格式
read:参数是几,就读几个字符
"""
''''''
file = open('file', 'r', encoding='utf-8')
data = file.read()
print(data)
file.close()
4.1.2 写入数据
"""
# 写入数据文件
1、打开文件
2、写入文件
3、关闭文件
open:
参数1:文件名称
参数2:操作名称
参数3:编码格式
write:将参数写入进去,将文件清空,在将数据写入进去
"""
file = open('file', 'w', encoding='utf-8')
file.write('helloWorld')
file.close()
4.1.3 追加数据
"""
# 追加数据
1、打开文件
2、追加数据
3、关闭文件
open:
参数1:文件名称
参数2:操作名称
参数3:编码格式
write:将参数写入进去,将文件清空,在将数据写入进去
"""
file = open('file', 'a', encoding='utf-8')
data = file.write("""
昨夜寒蛩不住鸣。
惊回千里梦,已三更。
起来独自绕阶行。
人悄悄,帘外月胧明。
白首为功名,旧山松竹老,阻归程。
欲将心事付瑶琴。
知音少,弦断有谁听。""")
print(data)
file.close()
4.1.4 指定的地方加入字符串
"""
# 在指定的地方加入一个字符串
"""
file = open('file', 'r', encoding='utf-8')
data = file.readlines() # 将数据读取出来,后面做操作,提高执行效率
file.close()
number = 0
for i in data:
number += 1
if number == 6:
i = ''.join([i.strip() + 'String']) # 取代万恶的 ‘+’
print(i.strip())
4.1.5 读取文件数据,企业版 **
"""
使用readline读取,这样内存中永远只有 <= 1 行数据,执行效率会很高
enumerate:返回的有映射关系,序号可以更改
"""
file = open('file', 'r', encoding='utf-8')
# for i in file: # 这是 for 内部将 file 对象做成了一个迭代器,用一行取一行
# print(i.strip())
for i, v in enumerate(file.readlines()):
print(i+1, v.strip())
4.1.6 查看光标位置
"""
tell:查看光标位置
中文占3个字符
英文占1个字符
"""
file = open('file', 'r', encoding='utf-8')
print(file.tell())
print(file.read(10))
print(file.tell())
4.1.7 调节光标
""" seek:调节光标 中文占3个字符 英文占1个字符 """ '''''' file.seek(0) print(file.tell()) print(file.read(10)) print(file.tell())
4.1.8 flush():将内存的数据flush到磁盘,以及进度条2种方式
"""
flush():将内存的数据flush到磁盘
常用于进度条
"""
file = open('file1', 'w', encoding='utf-8')
file.write('helloWorld')
file.flush()
"""
进度条,两种方式
"""
# 方式一
import sys,time
for i in range(30):
sys.stdout.write('*')
sys.stdout.flush()
time.sleep(0.5)
# 方式二
import sys,time
for i in range(30):
print('*', flush = 'True', end = '')
time.sleep(0.5)
4.1.9 truncate():截断文件数据
"""
truncate():截断文件数据
"""
''''''
file = open('file1', 'a', encoding='utf-8')
file.truncate(7)
file.close()
4.1.10 r+,w+,a+模式
"""
r+:读写模式
w+:写读模式
a+:追加读模式
"""
# r+:读写模式,先读取,在追加到文件末尾
file = open('file1', 'r+', encoding='utf-8')
data = file.readline()
file.write('\nhelloWorld')
print(data)
file.close()
# w+:写读模式,先全部删除,后写入
file = open('file1', 'w+', encoding='utf-8')
file.write('helloWorld\n')
print(file.tell())
file.seek(0)
print(file.readline())
file.close()
# a+:追加读模式,直接追击到文件末尾
file = open('file1', 'a+', encoding='utf-8')
file.write('helloWorld\n')
print(file.tell())
file.seek(0)
print(file.readline())
file.close()
4.1.11 终极问题,在文件中追加一个字符串
'''
终极问题,在文件中间加入一个字符串
'''
f_read = open('file1', 'r', encoding='utf-8')
f_write = open('file2', 'w', encoding='utf-8')
num = 0
for line in f_read.readlines():
num += 1
if num == 6:
line = ''.join([line.strip(), 'allure\n'])
f_write.write(line)
f_write.close()
f_read.close()
4.1.12 with使用,同时管理多个文件对象
'''
with 使用,同时管理多个文件对象
方式一等同于方式二
'''
# 方式一
with open('file1', 'r', encoding='utf-8') as file:
data = file.readlines()
print(data)
# 方式二
file = open('file1', 'r', encoding='utf-8')
data = file.readlines()
print(data)

- Python基础学习教程-前言
- python基础教程之lambda表达式使用方法
- Python基础教程代码与注释P89 6.1 懒惰即美德 P90 6.3 创建函数
- Python基础教程学习笔记 第一章 基础知识
- python基础教程学习笔记三
- 菜鸟教程Python基础语法学习笔记
- Python基础教程——9魔法方法、属性及迭代器【总结】
- Python基础教程之import和from...import
- python基础教程(十八)
- python基础教程共60课-第20课命令行常用命令
- 【书山有路】Python基础教程 第6章
- python常见排序算法基础教程
- Python常用算法学习基础教程
- python基础教程学习笔记 — 字符编码问题
- 简明Python3教程 6.基础
- 学习笔记(06):Python从入门到实战 基础入门视频教程(讲解超细致)-print函数详细讲解...
- python基础教程共60课-第29课连接list
- Python学习入门基础教程(learning Python)--1.2.4 Python格式化输出科学计数 .
- Python基础教程,第九讲,异常处理
- Python基础教程之字符串