山东大学创新实训项目简介
2020-07-14 06:30
65 查看
项目背景
我们计划使用NLP相关知识对数据集进行分词,关键词提取,模型训练、情感分析、热度分析对论坛内容进行关键词的提取和不同关键词热度分析并得到合理的预测模型,利用得到的预测模型模型预测不同时间段内热度较高的关键词来进行数据的关键词热度趋向的分析,并给出对应的建议。(再使用机器学习的算法对不同时间段内需要预测的主题的数据的发展情况和数据的关键词热度趋向分析结果进行联合分析,给出各个时间段的联合分析结果(和建议))。
项目技术路线
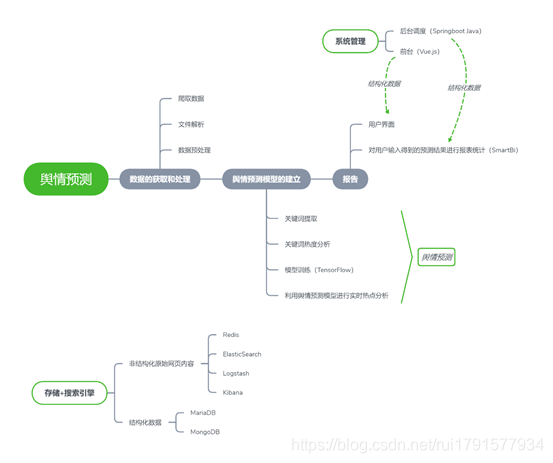
- 信息采集:使用爬虫从热门的web2.0网站爬取内容和ID,获取数据集。
- 数据预处理:对爬取的数据进行标注分类等数据的预处理,然后把数据集分为训练集、验证集、测试集。
- 预测模型的建立:在已有数据集的基础上,使用NLP相关知识对数据集进行分词,关键词提取,模型训练、情感分析、热度分析对数据集内容进行关键词的提取和不同关键词热度分析并得到合理的预测模型,利用得到的预测模型模型预测不同时间段内热度较高的关键词来进行趋向的分析。(再使用机器学习的算法对不同时间段内热度较高的关键词数据的发展情况和数据结果趋向分析结果进行联合分析,给出各个时间段的联合分析结果(和建议))。
- 结果呈现:设计软件或网站UI交互界面并实现后台调度,根据用户的输入,我们的预测模型给出结果,通过后台调度将我们的模型和用户的呈现进行交互,并将结果合理的呈现出来
- 系统管理:对网站以及训练模型的状态比如任务的调度、系统的状态、网址/关键字的维护等进行通过管理员界面等方式进行观测
- ELK构建搜索模块:
a. Redis高速缓存数据库 负责系统的搜索模块的效率 加快数据分析速度
b. Elasticsearch 创建索引提供搜索服务的分布式搜索引擎,由于我们分析爬取的数据量比较大,用ES搜索引擎创建索引,底层构建搜索服务。由于其是分布式的,能够保证我们系统的健壮性和高效性。
c. Logstash 负责数据传输,确保多个数据源导入ES中,同时对数据进行过滤操作,实现数据的增量更新和全量更新。
d. Kibana 可视化界面,进行ES索引的管理,进行搜索复杂语句处理,包括评分排序负责我们数据mapping的创建,包含数据分析和搜索界面。
项目的大体流程图:
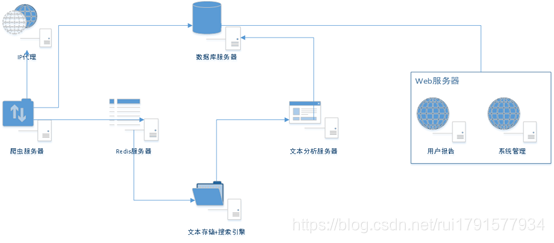
服务器大体架构
项目GitHub地址及成员博客地址**
项目GitHub地址
黄增瑞_blog
杨秀辉_log
汪逢生_blog
李哲荀_blog
尹成林_blog
杨涛_blog

相关文章推荐
- (项目)AR电子书系统创新实训第二周(2)
- 山东大学项目实训——5月12日
- (项目)AR电子书系统创新实训第一周(2)
- (项目)AR电子书系统创新实训第六周(1)
- 创新实训博客(31)——Vue.js前端项目的生产环境部署
- 山东大学项目实训——5月4日
- (项目)AR电子书系统创新实训中期汇报
- 自然语言交流系统 phxnet团队 创新实训 项目博客 (三)
- 山东大学学期中项目实训记录 (第一周)
- 山东大学项目实训——5月28日
- 自然语言交流系统 phxnet团队 创新实训 项目博客 (一)
- (项目)AR电子书系统创新实训第四周(1)
- 山东大学项目实训——6月4日
- (项目)AR电子书系统创新实训第五周(1)
- 自然语言交流系统 phxnet团队 创新实训 项目博客 (十二)
- 山东大学项目实训——5月25日
- 山东大学项目实训——5月18日
- “photo wake-up”创新项目实训第一周开题总结
- “photo wake-up”创新项目实训第一周总结
- 创新实训——Intellij Idea项目部署到远程Tomcat上