HDFS的高可用(HA)--------通俗易懂的分析
前言:
(NN:NameNode ; DN:DataNode)
HDFS的高可用(HA)也称为联邦HDFS,因为单个namenode在HDFS集群中可能发生单节点故障,一旦节点不可用,那么整个HDFS集群就会处于不可用状态.
现在,在Hadoop2.x之后,出现了HDFS的高可用(HA)来解决上述问题,在HDFS集群中运行两个namenode节点,一个作为活动的NN(Active Namenode) 一个作为备份NN(Standby Namenode),二者之间是实时同步的,所以当活动NN发生错误后,备份NN会马上进行状态转换变成Active Namenode,避免对HDFS集群造成影响
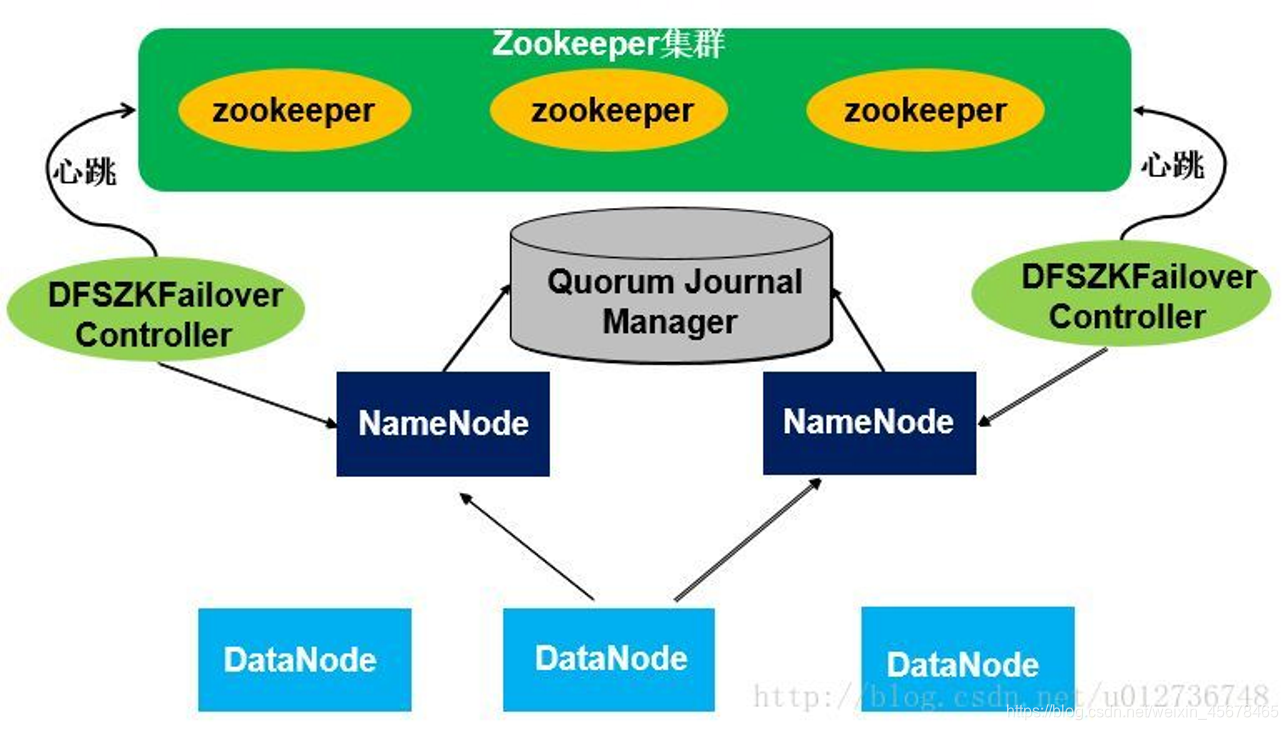
那么我们详细讲解下他们之间是怎么完成实时同步,怎么完成切换工作?
- 在一个HDFS高可用集群中,配置两个独立的NN在运行,在任意时刻,都能保持由一个NN作为活动节点,一个作为备用节点,为了使两个节点之间保持数据实时同步,因此他们需要同一组独立运行的节点(journalNode , JNS)进行通信,活动的NN在进行数据命名空间或DN操作数据等情况下,操作流程会写入JNS中,同步到EditLog中,备用节点会实时监听JN中EditLog中的数据变化,一旦检测到有新操作更新,Standby NN(备份节点)就会将EditLog合并,更新自己的命名空间,完成数据同步.但是发生错误时, 他们的状态就会发生转变,切换流程是备份NN先将监听JNS中EditLog的变化合并到本地数据中,并对自身状态进行变更,变更为Active NN,通过这种机制,才保证了Active NN 和 Standby NN之间的数据保持统一,也就是第一关系的一致性.
- 其中对于状态立即转变起到关键作用的就是热备准备. DN对于数据统一起着重要作用,他们将自身的数据变化同时传输到两个NN中,这样他们的元数据就实时保持一致,后续的读取EditLog操作就节省了一大部分时间,更快速的完成两个状态之间的转变.
这里需要注意一个问题,在一个高可用的HDFS集群中,要始终保持只有一个活动的NN,否则就会出现"脑裂"问题(fancing) , "脑裂"会导致数据不一致,部分数据丢失,为了预防fancing的发生,需要注意一下两个机制:HDFS的三个隔离级别:
a. 共享存储隔离:同一时间只允许一个NN向JNS中的EditLog进行数据写入
b.客户端隔离:同一时间只允许一个NN响应客户端的请求
c.DataNode隔离:同一时间,只允许一个NN给DN发送修改命名空间,修改数据等操作 -
Active NN 和 Standby NN的实时同步:
需要注意的是Active NN会将自身的日志文件写入到共享存储上,这时Standby NN会读取共享存储上的EditLog与自身的命名空间进行合并,这样才能在Active NN 发生错误时迅速进行状态转变.
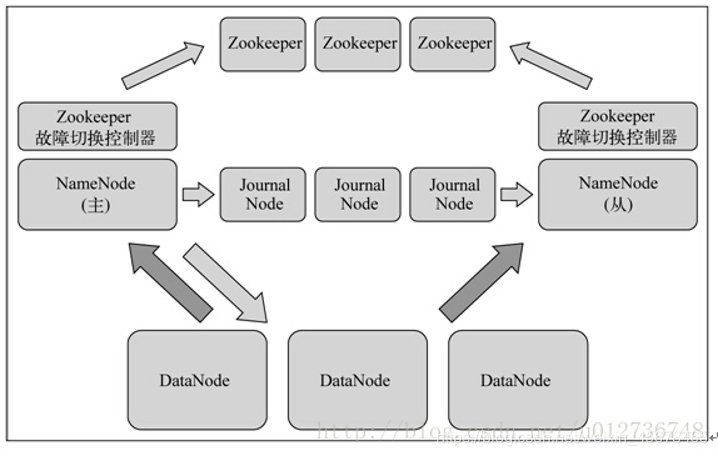
在这个高可用集群中,Quorum Journal方案中有两个重要的组件:
1 Journal Nodes(JN):他将EditLog文件保存到Journal node的本地磁盘上,同时还对外开放了QJournalProtocol接口以方便执行远程读写EditLog的功能.
2 QuorumJournalManager(QJM):运行在namenode上,为其提供了RPC的调用接口,QJournalProtocol方法向JournalNode发送同步EditLog的操作

- HDFS namenode 高可用(HA)搭建指南 QJM方式 ——本质是多个namenode选举master,用paxos实现一致性
- 基于QJM/Qurom Journal Manager/Paxos的HDFS HA原理及代码分析
- HDFS高可用(HA)设计
- HDFS中namenode的HA高可用机制
- 搭建高可用的分布式hadoop2.5.2集群 HDFS HA
- HDFS-HA:Hadoop-Cloudera-cdh4版本的HDFS自动Failover(zk-based-failover)分析
- Hadoop之HDFS的配置------HA(高可用版本)
- hadoop hdfs HA 高可用简易集群搭建
- Hadoop-HDFS学习理解到安装操作,以及HA高可用部署。
- Hadoop基础教程-第9章 HA高可用(9.3 HDFS 高可用运行)(草稿)
- HDFS原理分析(二)—— HA机制 avatarnode原理
- Hadoop分布式文件存储系统HDFS高可用HA搭建(何志雄)
- Hadoop基础教程-第9章 HA高可用(9.2 HDFS 高可用配置)(草稿)
- HDFS高可用(HA)配置
- Hadoop 2.2.0 HDFS HA高可用安装与配置
- HDFS NameNode HA架构分析
- HDFS原理分析之HA机制:avatarnode原理
- Ambari—HDFS配置NameNode HA高可用原理和操作步骤(一)
- Ambari—HDFS配置NameNode HA高可用原理和操作步骤(一)
- Hadoop HDFS通过QJM实现高可用HA环境搭建