HBase的架构和原理(三)--HFile文件的描述
2020-07-14 06:13
260 查看
HFile文件描述
从HBase开始到现在,HFile经历了三个版本
HFile在V1的格式

- V1的HFile由多个Data Block、可选的多个Meta Block、FileInfo、Data Index、Meta Index、Trailer组成
- DataBlock由一个魔数(Magic)和一系列的KeyValue(Cell)组成,魔数是一个随机的数字,用于表示这是一个Data Block类型。每个KeyValue对是一个简单的byte数组,且这个byte数组有固定结构。默认值是64KB

KeyLength:Key占用长度
ValueLength:Value占用长度
Key-ROWLength:表示RowKey长度
Key-Row:RowKey的值
Key-ColumnFamilyLength:列族占用长度
Key-ColumnQualifier:
Key-TImeStamp:
Key-KeyType:Key的操作类型Put/Delete
Value:Cell中存储的二进制数据 - Meta块是可选的,FileInfo是固定长度的块,它纪录了文件的一些Meta信息,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等。
- Data Index和Meta Index纪录了每个Data块和Meta块的起始点、未压缩时大小、起始RowKey
- Trailer纪录了FileInfo、Data Index、Meta Index块的起始位置,Data Index和Meta Index索引的数量等。
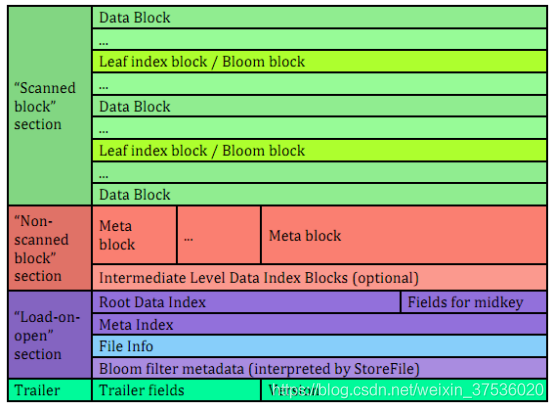
HFile的V2格式
在0.92版本中引入,目的是提升启动速度、减少启动时间,同时增加了延迟读的功能。这个版本增加了布隆过滤器Bloom Block
布隆过滤器:
- 布隆过滤器可以用于检索一个元素是否在一个集合中(只能确定元素的不存在,不能确定元素的存在)。一个Bloom Filter基于一个m位的位向量(b1,…bm),这些位向量的初始值为0。另外,还有一系列的hash函数(h1,…hk)(默认是3个哈希函数),这些hash函数的值域属于1~m。下图是一个bloom filter插入x,y,z并判断某个值w是否在该数据集的示意图:
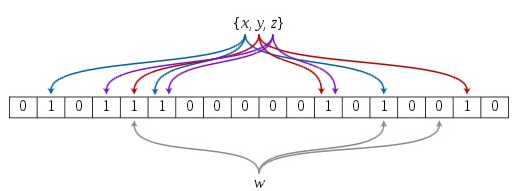
- RowKey的值为x经过三次HASH计算后,得到三个不同的HASH值,位向量中对应三个HASH值的位置标记为1.同理再计算y和z。
- 对于RowKey的值为w的检索,经过三次计算后,发现有一个位向量位置不为1,说明rowkey-w不在这个HFile集合中。若三个位向量位置都为1,说明rowkey存在这个HFile文件中。然后根据DataIndex 和 Trailer中块的起始为位置和数量,定位出RowKey的位置
- 由于HFile不止一个文件的情况,所以一个rowkey可能存在多个HFile文件中。这涉及到HFile的合并问题
HFile的V3格式
- HFile的V3版本在0.98之后提出,在V2格式后增加了标签部分。其他保持不变.所以对V2保持了兼容性。
- HFile V3主要的提高是压缩比和,通过对于key和value应用不同的压缩算法,可以获得更好对应key和value的位置信息,减少磁盘的读写,提高I/O速度

相关文章推荐
- HBase的架构和原理(四)--MemStore的Flush动作和HFile的Compaction机制
- hbase架构原理之region、memstore、hfile、hlog、columm-family、colum、cell
- Hbase原理、基本概念、基本架构
- 关于可扩展的web架构设计的探索-框架结构的描述文件
- Hbase原理、基本概念、基本架构
- 描述一下JVM 加载class文件的原理机制?
- (Hdoop Distributed File System )分布式文件系统原理;HDFS文件系统基本架构和运行机制
- Hbase原理、基本概念、基本架构
- 请简单描述一下JVM加载class文件的原理
- Hbase架构与原理
- Hbase原理、基本概念、基本架构
- Hbase原理、基本概念、基本架构
- 深入学习HBase架构原理
- Hbase架构与原理
- 描述一下JVM加载class文件的原理机制
- Hbase的架构和实现原理
- 深入学习HBase架构原理
- 【Java面试题】描述一下JVM加载class文件的原理机制?
- Hbase原理、基本概念、基本架构
- Hbase原理、基本概念、基本架构