深度学习(四)~循环神经网络
深度学习(四)~循环神经网络
循环神经网络
1. RNN训练流程
【RNN训练过程】
a. 前向计算每个神经元的输出值;
b. 反向计算每个神经元的误差项值;
c. 计算每个权重的梯度。
d. 最后再用随机梯度下降算法更新权重
2. 参数学习
(1)【RNN前向传播算法】
循环神经网络在时刻t的更新公式为

- x(t)代表在序列 t 时刻训练样本的输入;
- h(t) 代表在序列 t 时刻模型的隐藏状态. h(t)由x(t)和 h(t-1) 共同决定;
- o(t) 代表在序列 t 时刻模型的输出. o(t)只由模型当前的隐藏状态 h(t) 决定;
- L(t) 代表在序列 t 时刻模型的损失函数. 模型整体的损失函数是所有的L(t)相加和;
- y(t) 代表在序列 t 时刻训练样本序列的真实输出;
- f,σ为激活函数,通常前者f选择tanh,后者σ选择softmax;
- U是状态-状态权重矩阵,W是状态-输入权重矩阵,U,W,V这三个矩阵就是我们的模型的线性关系参数,它在整个RNN网络中是共享的。也正是因为是共享的,它体现了RNN的模型的“循环反馈”的思想.
(2)【随时间反向传播算法(BPTT)】
由于序列的每个位置都有损失函数,因此最终损失L为:
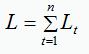
求 L 在 t 时刻对 W 、U 、V的偏导数:
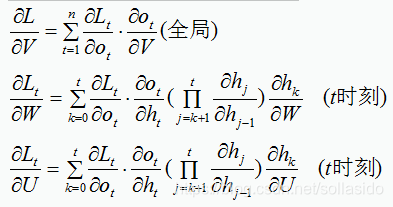
(3) 随时间反向传播算法(BPTT) VS 实时循环学习算法(RTRL)
① 在RNN中,一般网络输出维度远低于输入维度,因此BPTT算法计算量更小;
② BPTT需要保存所有时刻的中间梯度,空间复杂度较高,RTRL算法不需要梯度回传,适合在线学习或者无限序列任务
3. RNN应用:
(1). 序列到类别模式
特点:
输入:单词序列
输出:文本类别
一种是将最后时刻的状态作为整个序列的表示;另一种是对整个序列的所有状态进行平均,从而作为整个序列的表示

g(*)为分类器
应用:文本分类
(2). 同步的序列到序列模式
特点:每一时刻都有输入和输出,输入序列与输出序列的长度相同。例如为每个单词标注对应的词性标签
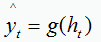
g(*)为分类器
应用:序列标注
(3). 异步的序列到序列模式
特点:也称编码器-解码器(Encoder-Decoder)模型,即输入序列和输出序列不需要严格的对应关系,也不需要保持相同的长度
流程:异步的序列到序列模式一般通过先编码后解码的方式来实现。先将样本x按不同时刻输入到一个循环神经网络(编码器)中,并得到其编码hT.再使用另一个循环神经网络(解码器)得到输出序列y(1:M)
应用:机器翻译
4. 长程依赖问题
参数学习过程中连乘项可能发生极大或极小的情况,从而影响最终结果,也即梯度消失与梯度爆炸问题
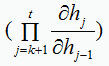
(1). 梯度消失
在参数学习过程中,连乘项若很多项小于1,则结果越来越趋近于0,导致信息损失过多,发生梯度消失
sigmoid 函数的导数范围是(0, 0.25],tanh 函数的导数范围是 (0, 1] ,均不大于一,因此容易累乘越来越小,出现梯度消失问题(例如:δ(wx+b)中,wx+b越大,δ导数越小).
一般采取的方式是优化技巧(优化激活函数,譬如将sigmold改为relu)或改变模型
(2). 梯度爆炸
在参数学习过程中,连乘项若很多项很大,则结果越来越大,导致计算量极大,发生梯度爆炸问题
一般采取的方式是权重衰减(正则化)或梯度截断
梯度截断思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内,从而防止梯度爆炸。
tanh 函数的收敛速度要快于 sigmoid 函数,梯度消失的速度要慢于 sigmoid 函数。
5. 改进方案-基于门控的循环神经网络
为了解决这两个问题,学者们引入了基于门控的循环神经网络.
(1) LSTM
与传统的循环神经网络相比,LSTM采用三门机制,输入门、遗忘门以及输出门和一个内部记忆单元。
遗忘门: 控制前一步记忆单元中的信息有多大程度被遗忘掉
输入门: 决定从当前步骤添加哪些信息
输出门: 决定下一个隐藏状态应该是什么
(2) GRU
GRU是在LSTM上进行简化而得到的,只有两个门,分别为更新门和重置门
重置门: 候选隐含状态使用了重置门来控制过去有多少信息被遗忘
更新门: 控制过去的隐含状态在当前时刻的重要性
LSTM与GRU等算法将在续篇详细介绍

- 深度学习(07)_RNN-循环神经网络-02-Tensorflow中的实现
- 动手学深度学习(第六章 循环神经网络)
- 动手学深度学习(二)——文本预处理&语言模型&循环神经网络
- 动手学深度学习(文本预处理+语言模型+循环神经网络基础)
- 深度学习(6)——循环神经网络RNN+LSTM
- 深度学习中的循环神经网络LSTM详解
- 【吴恩达deeplearning.ai】深度学习(9):循环神经网络
- 机器学习与深度学习系列连载: 第二部分 深度学习(十四)循环神经网络 2(Gated RNN - LSTM )
- 深度学习(DL)-- RNN循环神经网络算法详解
- 深度学习(Deep Learning)读书思考六:循环神经网络一(RNN)
- 机器学习与深度学习系列连载: 第二部分 深度学习(十五)循环神经网络 3(Gated RNN - GRU)
- 机器学习与深度学习系列连载: 第二部分 深度学习(十三)循环神经网络 1(Recurre Neural Network 基本概念 )
- 机器学习与深度学习系列连载: 第二部分 深度学习(十六)循环神经网络 4(BiDirectional RNN, Highway network, Grid-LSTM)
- 深度学习(八):循环神经网络简述
- 深度学习(06)_循环神经网络RNN和LSTM_01
- 深度学习循环神经网络
- 深度学习(花书)学习笔记——第十章 序列建模:循环神经网络
- Task02_pyTorch动手深度学习(文本预处理、语言模型、循环神经网络基础)
- 深度学习(DL)-- BRNN双向循环神经网络算法详解
- 循环神经网络 RNN Recurrent Neural Networks 介绍