【Java从头开始到光头结束】No8.Map集合之TreeMap回顾(附JDK 1.8 源码)
Map集合之TreeMap,附JDK 1.8 源码
基础回顾 → 集合之TreeMap
————————————————————————————————————
文章部分内容选自书本《码出高效:Java开发手册》
相关内容:
【Java从头开始到光头结束】No7.回顾Map集合基础与树形数据结构
1.整体回顾TreeMap

下边是类关系图,TreeMap相关我已经用红色框勾出:
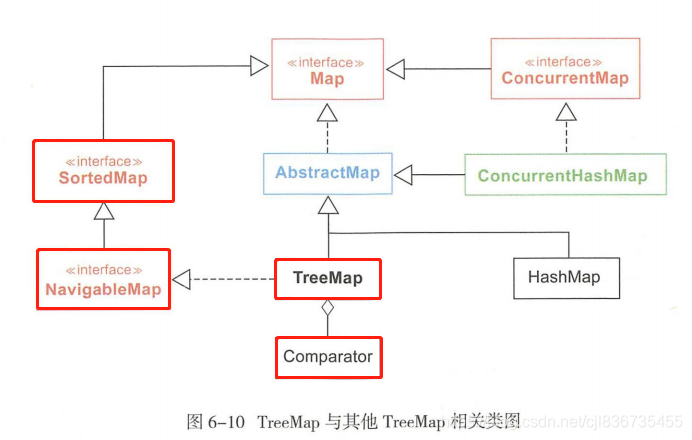
TreeMap在Map集合大家庭中还是占有很大一部分位置的,图左两个接口内容将在去重的部分说明。补充一下就是,TreeMap中key是不能为Null的,value可以,并且TreeMap也不是线程安全的。
2.TreeMap去重
TreeMap 的接口继承树中,有两个与众不同的接口 SortedMap 和 NavigableMap。
SortedMap 表示它的 Key 是有序不可重复的,支持获取头尾 Key-Value 元素,或者根据 Key 指定范围获取子集合等。插入的 Key 必须实现 Comparable 或额外的比较器Comparator,所以 Key 不允许为 null,而Value 可以。
Comparable,以able结尾,表示它有自身具备某种能力的性质,表明 Comparable 对象本身是可以与同类型进行比较的,它的比较方法是 compare To ,而 Comparator,以 or 结尾 自身是比较器的实践者,它的比较方法是 compare。
约定俗成,不管是 Comparable 还是 Comparator 小于的情况返回-1, 等于的情况返回0,大于的情况返回 1。
NavigableMap 接口继承了 SortedMap 接口,根据指定的搜索条件返回匹配的 Key-Value 。不同于HashMap, TreeMap 并非定要覆写 hash Code 和 equals 方法来达到 Key 去重目的。
————————————————————————————————
总结一下上述概念,由于TreeMap中Key有序的设计理念,导致首先Key无法为null,key元素的排序依靠key元素自身实现Comparable 接口或给TreeMap 对象提供额外的第三方比较器Comparator,这个我们在下来源码中可以看到,也因为key的有序性,在接口中实现了获取首尾或中间部分的单个或一组 key-value 值。
下边我们看书上的一个小例子,看看为什么TreeMap 并非定要覆写 hash Code 和 equals 方法来达到 Key 去重目的
package review.map.treemap;
import java.util.HashMap;
import java.util.TreeMap;
public class ReviewTreeMap {
public static void main(String[] args) {
// 设计特定的key类,复写方法来测试TreeMap和HashMap的不同去重方式
TreeMap<Key, String> tp = new TreeMap<>();
HashMap<Key, String> hp = new HashMap<>();
tp.put(new Key(), "value one");
tp.put(new Key(), "value twe");
hp.put(new Key(), "value one");
hp.put(new Key(), "value twe");
// 此时的 TreeMap size = 2
System.out.println("TreeMap Size: " + tp.size());
// 此时的 HashMap size = 1
System.out.println("HashMap Size: " + hp.size());
}
}
class Key implements Comparable<Key> {
@Override
// 返回负的常数 表示对比永不相等
public int compareTo(Key other) {
return -1 ;
}
// hashCode()和equals()方法比较结果都写死为→相同
@Override
public int hashCode() {
return 1;
}
@Override
public boolean equals(Object obj) {
return true;
}
}
控制台输出如下:
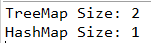
上述小例子再次证明了HashMap 使用 hashCode,equals 实现去重的。而 TreeMap 依靠 Comparable或Comparator 来实现 Key 的去重。这个信息非常重要,因为如果没有覆盖正确的方法,那么 TreeMap 的最大特性将无法发挥出来,甚至在运行时会出现异常。如果要用
TreeMap对Key 进行排序,调用如下方法(源码)

如果 Comparator 不为null,则优先使用比较器 comparator的compare 方法,如果为
null ,则使用 Key 实现的自然排序 Comparable 接口的 compareTo 方法。如果两者都无
法满足则抛出异常:

3.轻度解析TreeMap源码
基于红黑树实现的 TreeMap 提供了平均和最坏复杂度均为 O(log n) 的增删改查操作,并且实现了 NavigableMap 接口,该集合最大的特点是 Key 的有序性。
在了解到TreeMap的底层实现红黑树之后,我们看源码只会更加便捷,先从最基础的成员属性看起(说明我直接就写在注释上了):
// 首先是我们用于Key去重的第三方比较器
private final Comparator<? super K> comparator;
// 因为是红黑树所以会有 根节点
private transient Entry<K,V> root;
// map集合中的元素个数
private transient int size = 0;
// 用来记录对map集合的修改次数
private transient int modCount = 0;
// 红黑树的节点颜色判断
private static final boolean RED = false;
private static final boolean BLACK = true;
// Entry<K,V>就是我们存放一个键值对的对象
// 这里因为是红黑树实现,所以除过K,V还有红黑树的概念属性
// → left左节点,right右节点,parent父节点和节点颜色(默认黑色)
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
// ...
}
下来我们看一下构造方法及其使用到的其他方法:
// 无参构造,此时比较器为null,如果比较器一直为null
// 注意key要实现Comparable接口,否则put会报错
public TreeMap() {
comparator = null;
}
// 提供比较器comparator的构造方法
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
// 参数为一个集合,不深入了解的话就看到方法名为putAll,就能知道是把m集合的元素全部收入囊中
// 依旧没有提供比较器comparator。
public TreeMap(Map<? extends K, ? extends V> m) {
comparator = null;
putAll(m);
}
// 参数也是一个集合,但和上边不一样的是,此时m集合是SortedMap,是有序的集合
// 有序集合到有序集合就肯定比上边方便,同时也可以获取到比较器comparator
public TreeMap(SortedMap<K, ? extends V> m) {
comparator = m.comparator();
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
// —————————————————————————————————————————————————————————————————————————————
// 构造方法中使用到的其他方法:
public void putAll(Map<? extends K, ? extends V> map) {
int mapSize = map.size();
// 这里就判断当前TreeMap集合是不是为空,传入的map集合是否为空
// 以及传入的集合是否为SortedMap(有序集合)
// 如果你能确定参数传的是有序集合的话,建议直接使用第三种构造方法。
if (size==0 && mapSize!=0 && map instanceof SortedMap) {
Comparator<?> c = ((SortedMap<?,?>)map).comparator();
if (c == comparator || (c != null && c.equals(comparator))) {
++modCount;
try {
buildFromSorted(mapSize, map.entrySet().iterator(),
null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
return;
}
}
super.putAll(map);
}
// buildFromSorted()这个方法就不深入去看了,可以自己大致过一遍,
// 具体内容就是一些集合遍历以及红黑树节点选择放置的问题了。我觉得看到这里就可以了。
TreeMap 通过 put()和 deleteEntry() 实现红黑树的增加和删除节点操作,下面的源码分析以插入主流程为例,删除操作的主体流程与插入操作基本类似,不再展开:
// put()方法,参数是Key-Value值
public V put(K key, V value) {
/*
* t 表示当前节点,先把根节点 root 引用赋值给当前节点
* 如果根节点为null,则直接将put的这个Key-Value值存进根节点,存储的单位是Entry
* 这里调用compare(key, key)是没有实际的操作意义,只是想先预检一下Key是不是可以比较的
*/
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
// ———————————————————————————————————————————————————————
// cmp来存放比较结果
int cmp;
// 新插入节点的父节点
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
// ———————————————————————————————————————————————————————
/*
* 这一段逻辑就是在comparator不为空的情况下使用它来比较判定,找到新插入节点的父节点parent
* 根据红黑树的原则,小的向左走,大的向右走,如果遇到相等的Key值,则会覆盖原值(setValue)
*/
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
// ———————————————————————————————————————————————————————
/*
* 这一段逻辑就是在comparator为空的情况下使用它自身的Comparable来比较判定
* 实现的结果和上边一致,只是改变了比较手段。
*/
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
// ———————————————————————————————————————————————————————
// 这个e就是新插入的节点,其父节点是parent
Entry<K,V> e = new Entry<>(key, value, parent);
// 具体区分是左子节点还是右子节点
if (cmp < 0)
parent.left = e;
else
parent.right = e;
// ———————————————————————————————————————————————————————
// 我们已知的是红黑树也是平衡二叉查找树,他和AVL树一样都是通过旋转来维持左右子树平衡的
// 下边这个方法就是做的这件事,名字意译为【在插入后修正】
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
fixAfterInsertion(e);方法做的事主要就是判断树高度之后,对原树进行旋转和重新着色,让其在此保持平衡,代码内容依旧红黑树的特征内容,但是比较简单,每句代码代表的意思也比较单一,这里我直接上图书上的内容



其中比较麻烦的除过着色以外,还有旋转,分为左旋和右旋,书上这里讲解了左旋(NIL节点是假想在叶子结点上的两个虚拟子节点,都为黑色)

这里put的内容大概就这么多,下来我们看一下其他方法的源码:
/**
* 获取第一个Key,注意这里的第一个key可不是插入顺序意义上的
* 是Key排序结果之后第一个Key
*/
public K firstKey() {
return key(getFirstEntry());
}
/**
* 因为红黑树的实现原则,最小的元素在最左边
* 所以这里一直在向左下方遍历。
*/
final Entry<K,V> getFirstEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.left != null)
p = p.left;
return p;
}
/**
* 获取最后一个Key,也可以理解为排序后最大的Key
*/
public K lastKey() {
return key(getLastEntry());
}
/**
* 向右下方遍历
*/
final Entry<K,V> getLastEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.right != null)
p = p.right;
return p;
}
// ———————————————————————————————————————————————————————
/**
* 弹出第一个Entry→方法返回第一个Entry,并将它从TreeMap中删除
*/
public Map.Entry<K,V> pollFirstEntry() {
Entry<K,V> p = getFirstEntry();
Map.Entry<K,V> result = exportEntry(p);
if (p != null)
deleteEntry(p);
return result;
}
/**
* 弹出最后一个Entry
*/
public Map.Entry<K,V> pollLastEntry() {
Entry<K,V> p = getLastEntry();
Map.Entry<K,V> result = exportEntry(p);
if (p != null)
deleteEntry(p);
return result;
}
// 上边的弹出方法分别都是先取得对应弹出位置的Entry p,
// 然后通过exportEntry()方法再获取一次Entry实现→result,然后删除Entry p,
// 最后返回result,看似多此一举,我们细看一下exportEntry()方法:
// 主要是返回了一个SimpleImmutableEntry实现类
static <K,V> Map.Entry<K,V> exportEntry(TreeMap.Entry<K,V> e) {
return (e == null) ? null :
new AbstractMap.SimpleImmutableEntry<>(e);
}
// 而SimpleImmutableEntry类只包含key和value属性,对用户比较简洁明了,也比较安全
// 因为我们TreeMap中的Entry是有实现红黑树特征的,有更多的属性和引用指向。
public SimpleImmutableEntry(Entry<? extends K, ? extends V> entry) {
this.key = entry.getKey();
this.value = entry.getValue();
}
// 其他方法类似floorEntry(),lowerEntry(),ceilingEntry(),higherEntry()
// 和上边都差不多,不再过多阐述。
// ———————————————————————————————————————————————————————
// 因为TreeMap是有序的,实现的有SortedMap和NavigableMap接口,
// 其有序数据集合可以进行进行多种多样的集合划分,如下图内容
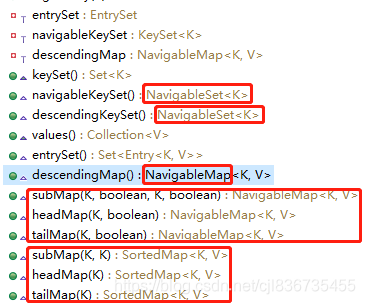
subMap(key, key):返回两个参数key之间的键值对;
tailMap(key): 返回比key小的键值对;
headMap(key): 返回比key大的键值对;
测试代码如下:
TreeMap<String, String> tp = new TreeMap<>();
tp.put("a1", "value 1");
tp.put("a2", "value 2");
tp.put("a3", "value 3");
tp.put("a4", "value 4");
tp.put("a5", "value 5");
tp.put("a6", "value 6");
System.out.println(tp);
System.out.println("subMap(a2, a5): " + tp.subMap("a2", "a5"));
System.out.println("tp.tailMap(a4): " + tp.tailMap("a4"));
System.out.println("tp.headMap(a3): " + tp.headMap("a3"));
结果如下:
subMap(key, key)方法,返回值包含左边界key值,不包含右边界key值。
tailMap(key)方法,返回值包含参数边界key值。
headMap(key)方法,返回值不包含参数边界key值的。

NavigableMap接口是SortedMap的子接口,实现内容更加丰富,可以根据需要来获取对应的接口实现。
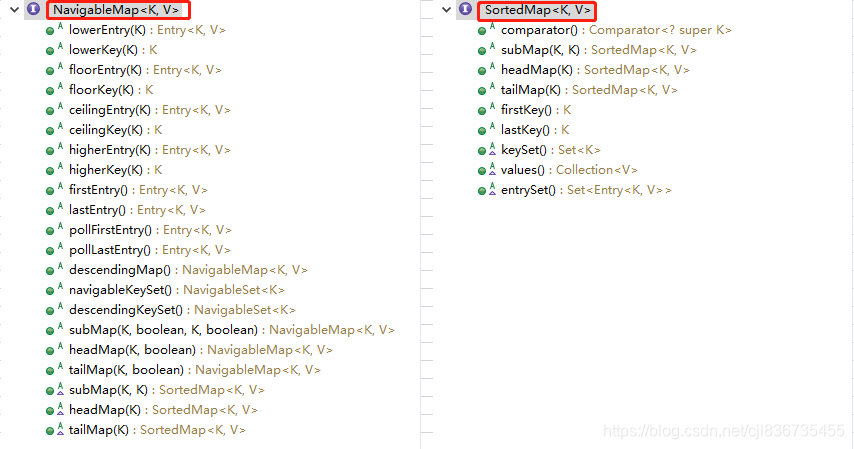
以及还有一个NavigableSet,descendingMap()的意思是反序的map集合

我们常用到的关于TreeMap的内容大概就和么多,里边还有一些关于红黑树颜色啊节点判断的方法,如果你们了解了红黑树旋转规则之后也是可以看明白的,这里内容繁杂就不在赘述。
—————————————————————————————————————
最后上一下书上的总结:
总体来说,TreeMap 的时间复杂度比 HashMap 要高一些,但是合理利用好TreeMap 集合的有序性和稳定性,以及支持范围查找的特性,往往在数据排序的场景中特别高效。
另外,TreeMap 是线程不安全的集合,不能在多线程之间进行共享数据的写操作。在多线程进行写操作时 需要添加互斥机制,或者把对象放在 Collections.synchroinzedMap(treeMap) 中实现同步。
在JDK7 之后的 HashMap,TreeSet,ConcurrentHashMap,也使用红黑树的方式管理节点。如果只是对单个元素进行排序 使用 TreeSet 即可。TreeSet 底层其实就是TreeMap, Value 共享使用一个静态 Object 对象,如下源码所示。
private static final Object PRESENT = new Object();
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
—————————————————————————————————————
OK 以上就是今天回顾TreeMap的全部内容,我们下次HashMap再见。

- java集合(6):TreeMap源码分析(jdk1.8)
- Java集合框架成员之HashTable类的源码分析(基于JDK1.8版本)
- java中的ArrayList集合源码分析(jdk1.8版本)。
- java集合-HashMap源码详解(基于JDK1.8版本)
- 【JDK1.8】JDK1.8集合源码阅读——TreeMap(一)
- Java集合--JDK 1.8 ConcurrentHashMap 源码剖析
- java1.8 常用集合源码学习:TreeMap
- Java集合源码实现三:HashMap(jdk1.8)
- 【JDK1.8】JDK1.8集合源码阅读——TreeMap(二)
- 【Java集合】JDK1.8源码之ArrayList(详细注释+常见问题)
- 【集合框架】JDK1.8源码分析之TreeMap(五)
- Java集合源码实现二:LinkedList(jdk1.8)
- Java集合源码实现五:HashSet(jdk1.8)
- Java集合源码实现一:ArrayList(jdk1.8)
- Java集合:LinkedList (JDK1.8 源码解读)
- 【JDK1.8】JDK1.8集合源码阅读——TreeMap(一)
- Java集合源码实现四:LinkedHashMap(jdk1.8)
- Java集合学习笔记(二)—— ArrayList源码学习(jdk1.8)
- java基础提高篇--集合源码分析--jdk1.8 HashMap源码
- java基础提高篇--集合源码分析--jdk1.8 ArrayList源码