Redis学习历程(三) - 全局命令、数据结构及单线程架构
2020-06-10 04:36
295 查看
一、全局命令
针对 键 来说的一些通用的命令。
| key | 描述 |
|---|---|
| keys * | 返回当前所以的 Key |
| dbsize | 返回当前数据库中 Key 的总数。共有16个库哦! |
| exists key | 检查键是否存在。存在则返回 1、不存在则返回 0 |
| del key | 删除键 |
| expire key seconds | 添加过期时间,当超过过期时间后,自动删除键 |
| ttl key | 返回键的剩余过期时间。1、大于等于 0 的整数:表示键剩余的过期时间。2、返回 -1:键没设置过期时间。3、返回 -2:键 不存在。 |
| type key | 返回数据结构类型。键不存在,则返回 none |
二、数据结构和内部编码
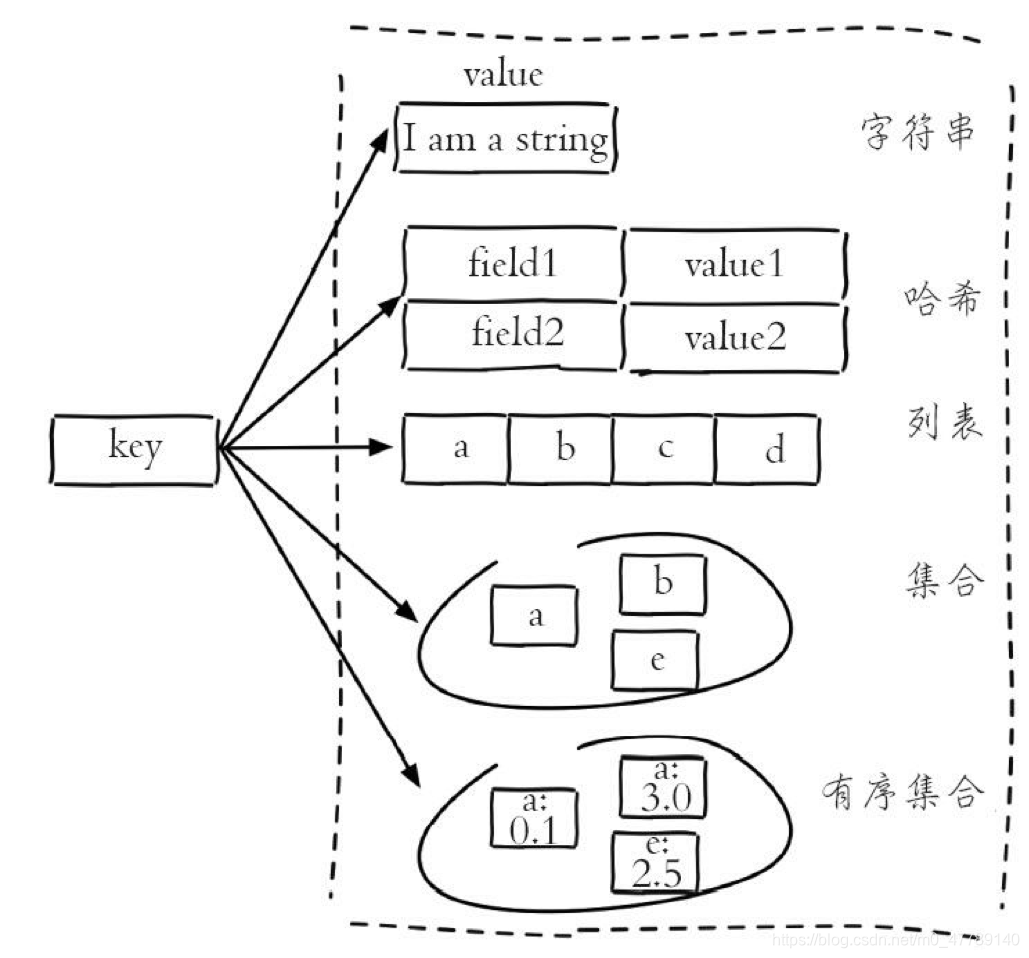
Redis五种数据结构分别是:string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合),但这些只是 Redis 对外的数据结构。如图所示:
对于每种数据结构,实际上都有自己底层的内部编码实现,而且是多种实现。这样 Redis 会在合适的场景选择合适的内部编码,如图所示:
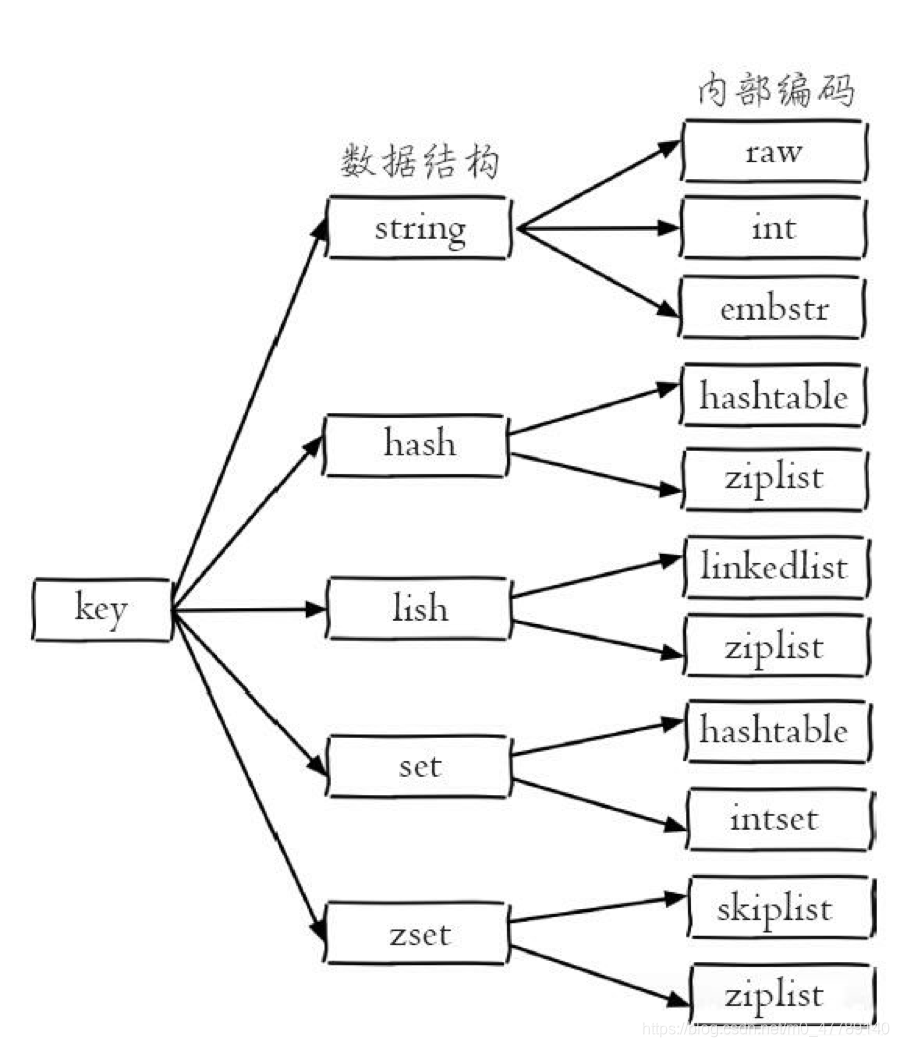
如上图所示,每种数据结构都有两种以的内部编码实现。例如 list 数据结构 包含了 linkedlist 和 ziplist 两种内部编码。同时有些内部编码,例如 ziplist,可以作为多种外部数据结构的内部实现,可以通过 object encoding 命令查询内部编码:
127.0.0.1:6379> object encoding hello "embstr" 127.0.0.1:6379> object encoding mylist "quicklist"
可以看到键 hello 对应值的内部编码是 embstr,键 mylist 对应值的内部编码是 ziplist。
Redis 这样设计有两个好处:
- 可以改进内部编码,而对外的数据结构和命令没有影响。例如 Redis3.2 提供的 quicklist,结合了 ziplist 和 linkedlist 两者的优势,为列表类型提供了一种更加高效的内部编码实现。
- 不同内部编码 可以在不同场景下发挥各自的优势。例如 ziplist 比较节省内存,但是在列表 元素比较多的情况下,性能会有所下降,这时候 Redis 会根据 配置,将列表类型的内部实现转换为 linkedlist。
三、单线程架构
Redis 使用了单线程架构和 I/O 多路复用模型来实现高性能的内存数据库服务。那为什么单线程还能这么快,下面分析原因:
- Redis 将所有数据放在内存中,内存的响应时长大约为 100 纳秒,这是 Redis 达到每秒万级别访问的重要基础。
- 单线程避免线程切换和竞态产生的消耗。CPU 不需要上下文切换带来的性能损耗以及处理锁的问题。
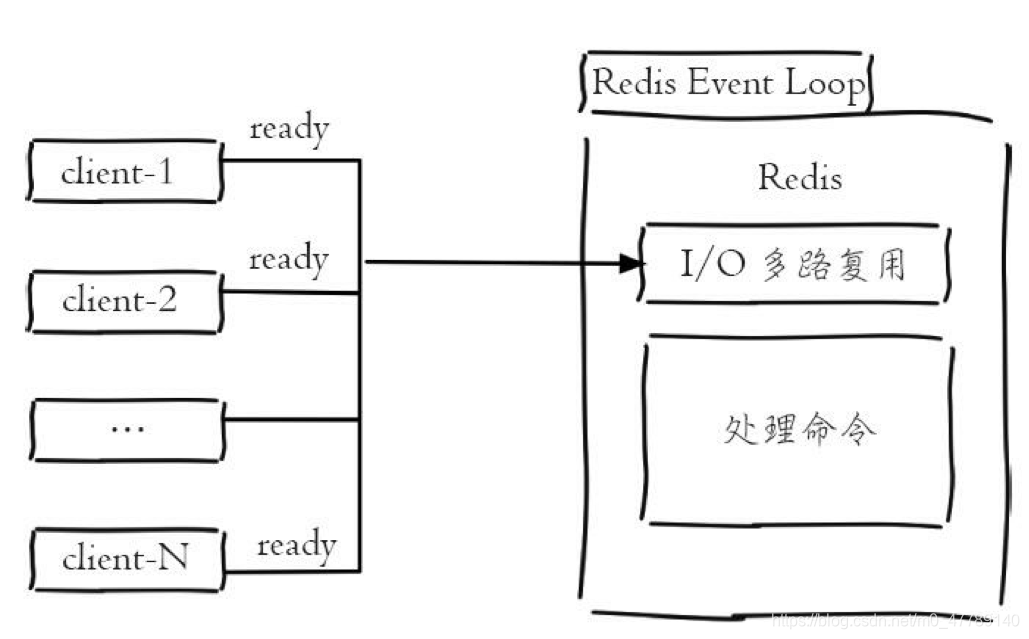
- Redis 使用 epoll 作为 I/O 多路复用技术的实现,再加上 Redis 自身的事件处理模型将 epoll 中的连接、读写、关闭都转换为事件,从而不用不在网络 I/O 上浪费过多的时间,如图所示:
本文参考
1.《Redis 开发与运维》
2. https://juejin.im/post/5bb01064e51d453eb93d8028#heading-11

相关文章推荐
- 高可用Redis(一):通用命令,数据结构和内部编码,单线程架构
- redis学习(二)--- 数据结构和常用命令
- redis 源码学习(核心数据结构剖析)
- redis学习笔记---redis特性(expire、事务、数据排序、config命令)
- Redis学习笔记2--Redis数据类型及相关命令
- Redis学习_数据类型操作命令
- Redis基础学习--安装、简介、基本数据类型及相应命令
- Redis的单机安装和5中数据结构的常用命令
- redis 学习手册之哈希表数据类型hashes操作命令
- Redis学习笔记之底层数据结构
- 【嵌入式学习历程11】数据结构之二叉树
- Redis学习笔记【03】 - 常用全局命令
- Redis学习笔记-Redis内部数据结构
- redis 学习手册之无序集合数据类型sets操作命令
- Redis学习-数据结构
- Redis命令、数据结构场景、配置文件总结
- 记录我的数据结构(C语言)学习历程(2017年3月30号开始):
- 【嵌入式学习历程8】数据结构之链表
- redis学习记录(三)-redis中的数据结构
- Redis学习和应用记录(2)--常用数据类型及命令