Pandas聚合操作 groupby和agg的用法归纳
笔者在打比赛过程中经常需要用到聚合操作,现将自己平常遇到的几种用法总结如下,便于大家和自己查询。
我们直接通过例子进行讲解,首先,我们来定义一个dataframe:
import pandas as pd
import numpy as np
# 自定义函数,便于后面使用
def fun(arrs):
res = 100 * len(arrs)
return res
df = pd.DataFrame({'key1':['a', 'a', 'b', 'b', 'a','a','a','a'],
'key2':['one', 'two', 'one', 'two', 'one','two','two','two'],
'data1':np.random.randint(0,5,8),
'data2':np.random.randint(0,5,8),
'data3':np.random.randint(0,5,8)})
生成的dataframe如下:
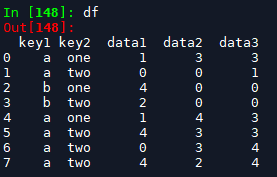
1. groupby聚合之后,只对一列进行操作
1.1 只进行一种统计
data1 = df.groupby(['key1', 'key2'])['data1'].sum() # 结果类型为Seris, index为复合index
结果如下:
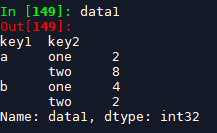
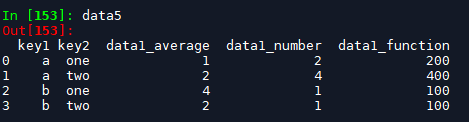
返回的data1的类型是Series,它的index为聚合键,也可以看作由(key1,key2)组成的复合index。我们可以通过reset_index操作将其转化为dataframe这种更加直观的形式。
data2 = data1.reset_index() # 类型为dataframe, columns为key1, key2, data1; index为阿拉伯数字
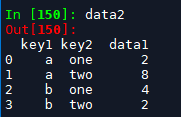
1.2 进行多种统计,包括上面定义的自定义函数
当我们需要对选取的列运用多种统计函数的时候,我们需要用到**agg()**操作
data3 = df.groupby(['key1','key2'])['data1'].agg(['mean', 'count', fun]) # agg里为列表,返回类型为dataframe, index为聚合键; columns为统计函数名称,即mean, count, fun
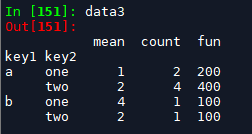
一般来说,这样的列名不是我们想要的,除了直接更改列名之外,我们可以直接在聚合的时候就指定列名,如下:
data4 = df.groupby(['key1','key2'])['data1'].agg({'data1_average':'mean', 'data1_number':'count', 'data1_function':fun})
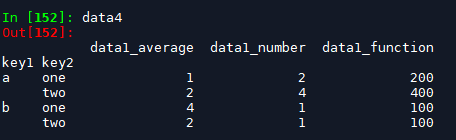
返回值data4是dataframe类型,其中的columns列名变成了我们指定的字典的键,index仍为聚合键,我们可以通过reset_index()操作使之变成两列
2. groupby聚合之后,对所有列进行操作
2.1 只进行一种统计
如果我们聚合之后想对所有列进行操作,那么groupby之后就不需要指定列,直接跟统计函数即可:
data6 = df.groupby(['key1']).sum() # 类型为dataframe, index为聚合键, columns为data1, data2, data3; # 需要注意的是,不符合运算定义的key2列被忽略(key2这一列为字符串,没有sum函数)
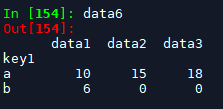
其中聚合之后的列名仍为原来的列名,假如有需要,可以直接通过data6.columns属性进行修改。结果中不含key2列,这是因为key2这一列为字符串,没有sum函数,所以自动被忽略
2.2 进行多种统计,包括自定义函数
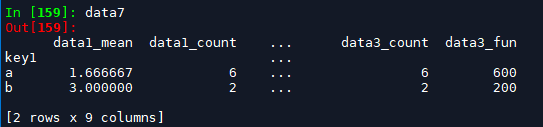
data7 = df.groupby(['key1']).agg(['mean', 'count', fun]) # 类型为dataframe, index为聚合键, columns为复合列名,
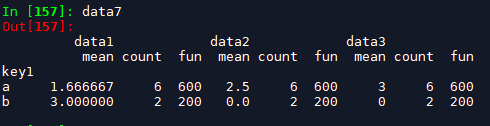
一般会通过对data7.columns属性进行修改,来符合我们平常的习惯
data7.columns = ['_'.join(x) for x in data7.columns]
3. groupby聚合之后,对列进行选择,但是对所有列都进行相同统计
3.1 只进行一种统计
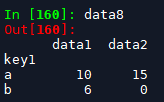
data8 = df.groupby(['key1'])[['data1','data2']].sum()
3.2 进行多种统计
同样的,进行多种统计,我们需要用到agg函数
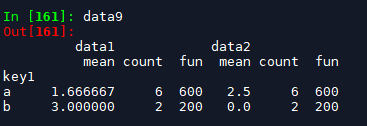
data9 = df.groupby(['key1'])[['data1','data2']].agg(['mean', 'count', fun]) # 结果为复合列名
4. groupby聚合之后,对列进行选择,并对不同的列进行不同的操作
要达到这种目的,我们对agg()函数里传入字典,字典的key为列名,value为对应的统计函数列表如下:
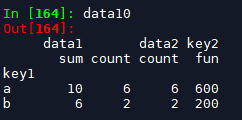
agg_dict1 = {'data1':['sum','count'], 'data2':['count'], 'key2':[fun]}
data10 = df.groupby(['key1']).agg(agg_dict1)
# 结果为复合键
我为什么把上面的统计函数列表加粗呢?这是因为,当每列都只需要进行一种统计操作的时候,字典的value为列表还是函数名,所产生的结果有所不同,如下:
agg_dict2 = {'data1':'sum', 'data2':'count', 'key2':fun}
data11 = df.groupby(['key1']).agg(agg_dict2)
agg_dict3 = {'data1':['sum'], 'data2':'count', 'key2':fun}
data12 = df.groupby(['key1']).agg(agg_dict3)
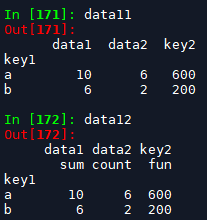
结果的列名一个是原来的列名,一个是复合列名。我的理解是,当统计函数包含在列表里的时候,就默认为可能需要进行多种统计,所以聚合之后的列名就不能再是原来的列名(否则区分不开)
好啦,笔者目前见过的关于groupby和agg的聚合操作基本就这些啦,希望对大家有帮助~

- 简要说明python pandas中groupby,agg等的用法
- Pandas —— groupby( )聚合分组
- 对比MySQL学习Pandas的groupby分组聚合
- python/pandas数据挖掘 groupby,聚合
- Pandas分组方法groupby和聚合函数agg相关
- pandas聚合和分组运算之groupby - 2
- pandas聚合和分组运算——GroupBy技术(1)
- pandas-09 pd.groupby()的用法
- Hive环境搭建以及基本操作和运维(详细),如内置函数,Join和GroupBy以及where用法 和JDBC 的java代码操作(Mysql数据库)
- python/pandas数据挖掘(十四)-groupby,聚合,分组级运算
- 详解pandas数据分析之groupby分组聚合(基于电商平台数据)
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
- pandas数据分组和聚合操作
- pandas中groupby()函数的用法
- python的pandas库的sort_values、set_index、reset_index、cumsum、groupby函数的用法
- 关于pandas.DataFrame的groupby的用法
- Pandas之groupby( )用法笔记小结
- pandas的groupby以及pivot_table用法——以计算恩格尔系数为例
- pandas聚合和分组运算之groupby
- pandas groupby 分组的操作