数据挖掘 | [有监督学习——分类] 朴素贝叶斯及python代码实现——利用sklearn
朴素贝叶斯分类
相关文章:
数据挖掘 | [关联规则] 利用apyori库的关联规则python代码实现
数据挖掘 | [有监督学习——分类] 决策树基本知识及python代码实现——利用sklearn
数据挖掘 | [无监督学习——聚类] K-means聚类及python代码实现——利用sklearn
数据挖掘 | [无监督学习——聚类] 凝聚层次聚类及python代码实现——利用sklearn
贝叶斯分类
- 贝叶斯分类是一种对属性集和类变量的概率关系建模的分类方法,它可以预测类成员关系的可能性,如给定样本属于一个特定类的概率。
- 贝叶斯分类是基于贝叶斯定理的,而贝叶斯定律是建立在联合概率以及条件概率基础上的。
贝叶斯定理
假设A,B是任意两个随机事件,则有:
- 联合概率:表示两个事件共同发生的概率。A与B的联合概率表示为 P(AB) 或者P(A,B)。
- 条件概率:事件B在另外一个事件A已经发生条件下的发生概率。条件概率表示为P(B|A)。
- A与B的联合概率和条件概率满足如下关系:
P(A,B)=P(B|A) * P(A)
P(A,B)=P(A|B) * P(B) - 贝叶斯定理:
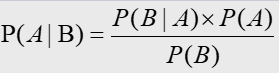
贝叶斯定理在分类中的应用
如果从统计学的角度对分类问题形式化,则有如下现象:
- 设X表示为属性集, Y表示为类变量。如果我们通过前期数据处理,形成一个包含X和Y的数据集合,将X与Y看成是随机变量,我们就可以对属性X发生、类变量Y发生以及在Y发生条件下X发生的概率P(X)、P(Y)、P(X|Y)的概率进行估计,那么我们就也就可以计算出P(Y|X)的概率。
P(Y|X)的分类意义在于:在属性X存在的条件下,我们可以预测它属于类Y的概率有多大。P(Y|X)称为Y的后验概率,P(Y)称为Y的先验概率。
要准确估计类标号与属性值的每一种可能组合的后验概率非常困难,需要很大的训练集。此时,贝叶斯定理给我们提供了一种可能:它允许我们用先验概率P(Y),类条件概率P(X|Y)和属性X的证据概率P(X)来表示后验概率:
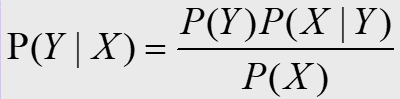
在比较不同Y值的后验概率时,分母P(X)总是一样的,可以看成是一个常数,因此可以忽略,P(Y)可以通过数据集估计,对于P(X|Y)的估计,就可以使用贝叶斯分类方法。
朴素贝叶斯分类
朴素贝叶斯分类在求P(Y | X)值时,假定一个属性值对给定类的影响独立于其他属性,这一假定称为类条件独立。做此假定目的是为了简化计算,因此称为“朴素的”。
sklearn提供的朴素贝叶斯算法
- Gaussian Naive Bayes
- Multinomial Naive Bayes
- Complement Naive Bayes
- Bernoulli Naive Bayes
- Categorical Naive Bayes
- Out-of-core naive Bayes
-
Gaussian Naive Bayes:GaussianNB实现高斯朴素贝叶斯算法进行分类。这些特征的可能性假定为高斯:
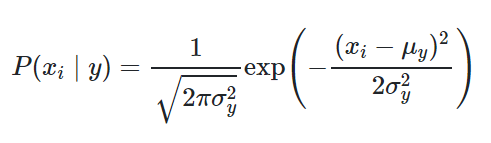
两个参数使用最大似然估计。 -
Multinomial Naive Bayes:MultinomialNB实现了用于多项分布数据的朴素贝叶斯算法,并且是文本分类中使用的两个经典朴素贝叶斯变体之一(其中数据通常表示为单词向量计数,尽管众所周知tf-idf向量在实践中也能很好地工作) 。
-
ComplementNB实现补码朴素贝叶斯(CNB)算法。CNB是标准多项式朴素贝叶斯(MNB)算法的改编,特别适合于不平衡数据集。
-
BernoulliNB对根据多元伯努利分布分配的数据实施朴素的贝叶斯训练和分类算法;也就是说,可能有多个特征,但每个特征都假定为一个二进制值(伯努利(Bernoulli),布尔值)变量。因此,此类要求将样本表示为二进制值特征向量。
-
CategoricalNB为分类分布的数据实现分类朴素贝叶斯算法。它假定由索引描述的每个功能 i,具有自己的分类分布。
本文使用的是高斯朴素贝叶斯。
python代码实现
import numpy as np # 快速操作结构数组的工具
import pandas as pd # 数据分析处理工具
from sklearn.model_selection import train_test_split #训练集测试集分割函数
from sklearn.preprocessing import LabelEncoder #将字符串转化为数字
from sklearn.naive_bayes import GaussianNB #高斯朴素贝叶斯
data_pd=pd.read_csv('csv文件路径',sep=',')
#删除包含缺失值的个案
print("删除缺失值前个案数:",len(data_pd))
c=data_pd.columns.values.tolist()
#print(c)
#数据中缺失值被标记为“?”
for i in c:
data_pd=data_pd[~data_pd[i].isin(['?'])]
print("删除缺失值后个案数:",len(data_pd))
data_arr=np.array(data_pd) #将dataframe转换成array
#生成属性数据集和结果数据集
dataMat = np.mat(data_arr)
arrMat = dataMat[:,0:9] #该数据前几个变量为数据属性,最后一个为分类结果
resultMat = dataMat[:,9]
#以下代码参考:https://www.geek-share.com/detail/2725984217.html
# 构造数据集成pandas结构
attr_names = ['age','menopause','tumor-size','inv-nodes','node-caps',
'deg-malig','breast','breast-quad','irradiat'] #特征属性的名称
#每行为一个对象,每列为一种属性,最后一个为结果值
attr_pd = pd.DataFrame(data=arrMat,columns=attr_names)
#print(attr_pd)
#将数据集中的字符串转化为代表类别的数字。因为sklearn的决策树只识别数字
le = LabelEncoder()
#为每一列序列化,就是将每种字符串转化为对应的数字。用数字代表类别
for col in attr_pd.columns:
attr_pd[col] = le.fit_transform(attr_pd[col])
#print(attr_pd)
attr_arr=np.array(attr_pd)
#此处数据类型的转换是为了最后结果输出的时候可以正常调用.sum()方法
#.A 将numpy中的matrix(矩阵)数据类型转换为numpy中的array(数组)数据类型
result_arr=resultMat.A
#将numpy中的array(数组)数据类型转换为list(列表类型)
result_list=[]
for i in result_arr:
for j in i:
result_list.append(j)
#拆分训练集和测试集
Xtrain,Xtest,Ytrain,Ytest=train_test_split(attr_arr,result_list,test_size=0.2,random_state=420)
#以下代码参考:https://scikit-learn.org/stable/modules/naive_bayes.html
#训练
gnb = GaussianNB()
gnb.fit(Xtrain,Ytrain)
print(gnb)
#预测
predict = gnb.predict(Xtest)
#输出预测结果
score = gnb.score(Xtest,Ytest)
print("预测准确度:",score)
#print(predict)
#y_pred = gnb.fit(Xtrain, Ytrain).predict(Xtest)
print("Number of mislabeled points out of a total %d points : %d"
% (Xtest.shape[0], (Ytest != predict).sum()))
输出的结果:
删除缺失值前个案数: 286 删除缺失值后个案数: 277 GaussianNB(priors=None, var_smoothing=1e-09) 预测准确度: 0.8214285714285714 Number of mislabeled points out of a total 56 points : 10
一些参考

- 『sklearn学习』利用 Python 练习数据挖掘
- 数据挖掘(Python)——利用sklearn进行数据挖掘,实现算法:svm、knn、C5.0、NaiveBayes
- 朴素贝叶斯分类算法介绍及python代码实现案例
- 朴素贝叶斯的概率理论及其python代码实现文本分类的实例
- 小白学数据:教你用Python实现简单监督学习算法
- 利用 Python学习数据挖掘【1】
- 利用朴素贝叶斯算法进行分类-Java代码实现
- 如何利用Python来学习数据挖掘?需要掌握Python中的哪些知识?
- Python、sklearn、KNN分类算法学习——以鸢尾花数据分类为例
- Caffe python利用classify.py实现对单通道(灰度图)的数据进行分类
- python实战:sklearn的KNN算法实现手写数据的分类
- 利用python+jieba+gensim+sklearn实现微博文本性别分类
- python机器学习---监督学习---朴素贝叶斯(用于分类)
- python实现拉格朗日插值法——————基于对python数据挖掘和大数据技术的代码修改
- 【机器学习算法-python实现】K-means无监督学习实现分类
- 数据挖掘之Apriori算法详解和Python实现代码分享
- 机器学习与数据挖掘-K最近邻(KNN)算法的实现(java和python版)
- 【Python数据挖掘课程】三.Kmeans聚类代码实现、作业及优化
- 玩转数据系列:利用阿里云机器学习在深度学习框架下实现智能图片分类
- Python数据挖掘课程 三.Kmeans聚类代码实现、作业及优化