一文搞懂哈希表
1、什么叫哈希表
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做**散列表 ** (这是百度百科的解释)。
简单点说,就是哈希表也叫散列表(英文名 Hash Table),它也是一种数据结构,它的特点是:可以根据一个key值来直接访问数据,因此查找速度快。
相信大家都知道,几个最基本的数据结构中,数组的查询效率最高。其实哈希表的本质就是数组。就是哈希表的底层实现用到了数组,就是在数组的基础上进行了一些加工,让其变得有特色,然后 就变成了哈希表。
2、哈希表的实现方式
哈希表有下面两种实现方式:
1、数组+链表
2、数组+二叉树
这也是我上面说哈希表的本质是数组的原因,就是在数组的基础上加一些其他的东西,但是数组一般存放的是单一的数据,而哈希表中存放的是一个键值对。
3、哈希表中的几个概念
啥是散列函数
我们借用一个百度百科上的例子来说明:
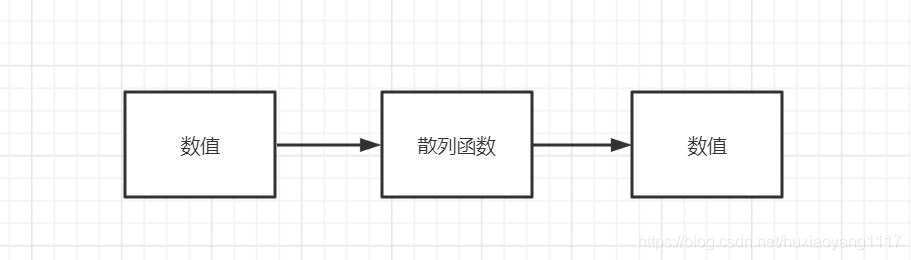
 我们如果要想快速找到姓王的这个人,我们就可以直接根据他的姓氏的首字母来来快速定位,放到数学里就是给你一个值,经过一个函数的加工变成了另外一个值,然后这个函数我们就叫做散列函数。类似于下图的过程
我们如果要想快速找到姓王的这个人,我们就可以直接根据他的姓氏的首字母来来快速定位,放到数学里就是给你一个值,经过一个函数的加工变成了另外一个值,然后这个函数我们就叫做散列函数。类似于下图的过程
关键值Key
从左往右看,第一个数值,经过散列函数的加工,变成了另外一个数值。那么第一个数值就是所说的key。总体看下来,可以这么说,哈希表就是通过将关键值也就是key通过一个散列函数加工处理之后得到一个值,这个值就是数据存放的位置,我们就可以根据这个值快速的找到我们想要的数据。
深入了解哈希表
相信大家对数组都很熟悉,下标索引从0开始,连续的,可以直接通过下标访问。比如有一个数组arr,有5个元素,我们可以通过arr[1]拿到第二个元素,查询速度很快。
那我们看看哈希是什么样子的。先看一幅图

这个图就很形象的说明 了我们的之前说的,哈希表就是通过将关键值也就是key通过一个散列函数加工处理之后得到一个值,这个值就是数据存放的位置,我们就可以根据这个值快速的找到我们想要的数据。
键值对和Entry
键值对就是我们所说的key-value ,简单的值就是一个值对应另外一个值比如a对应b,那么a就是key,b就是value。entry就是jdk对于键值对的一个官方名称,毕竟好多语言里都会有键值对,我们java要和别的语言区别开来。
4、 哈希表如何存数据
通过上图我们可以发现,哈希表的本质是数组,,现在有一个长度为8的数组,我们要做的就是把学生信息存到这个数组中,学生信息包括学生学号和姓名,也就是对应的key-value,我们先通过一个哈希函数对这个key进行计算,确定这个entry所存放的位置,然后将这个entry放入数组中的当前索引的位置即可。但是有一个问题,我们知道这个存放entry的下标索引是key经过hash函数的加工得到的,那么会不会存在说,别的key也经过hash函数,也得到这个下标索引,这就是我们所说的hash冲突的问题。
哈希冲突
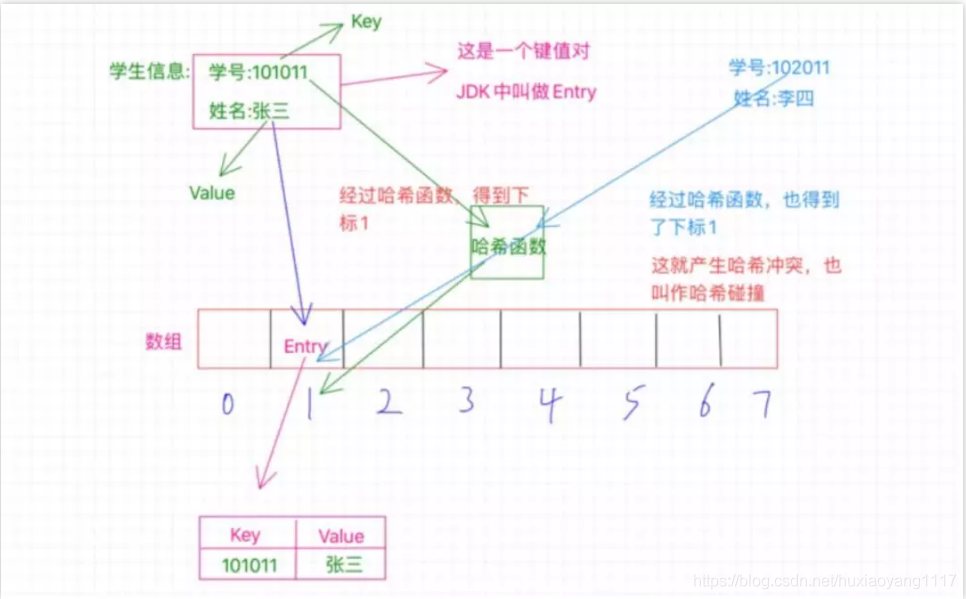
就如上图所示,张三的key经过哈希函数得到了1,李四的key经过哈希函数也得到了1 ,这个时候应该怎么办呢,怎么存呢。
处理哈希冲突
- 开放寻址法
开放寻址法简单点说,就是位置被占了,那就另外找个位置存就可以了,怎么找其他位置呢?我们说个最基本的,就是如果当前位置被占了,那就看看该位置的后一个位置是否可用,可用的话,就存这里,如果还是被占用的话,在继续看下一个位置,直到找到空位置为止。
- 拉链法
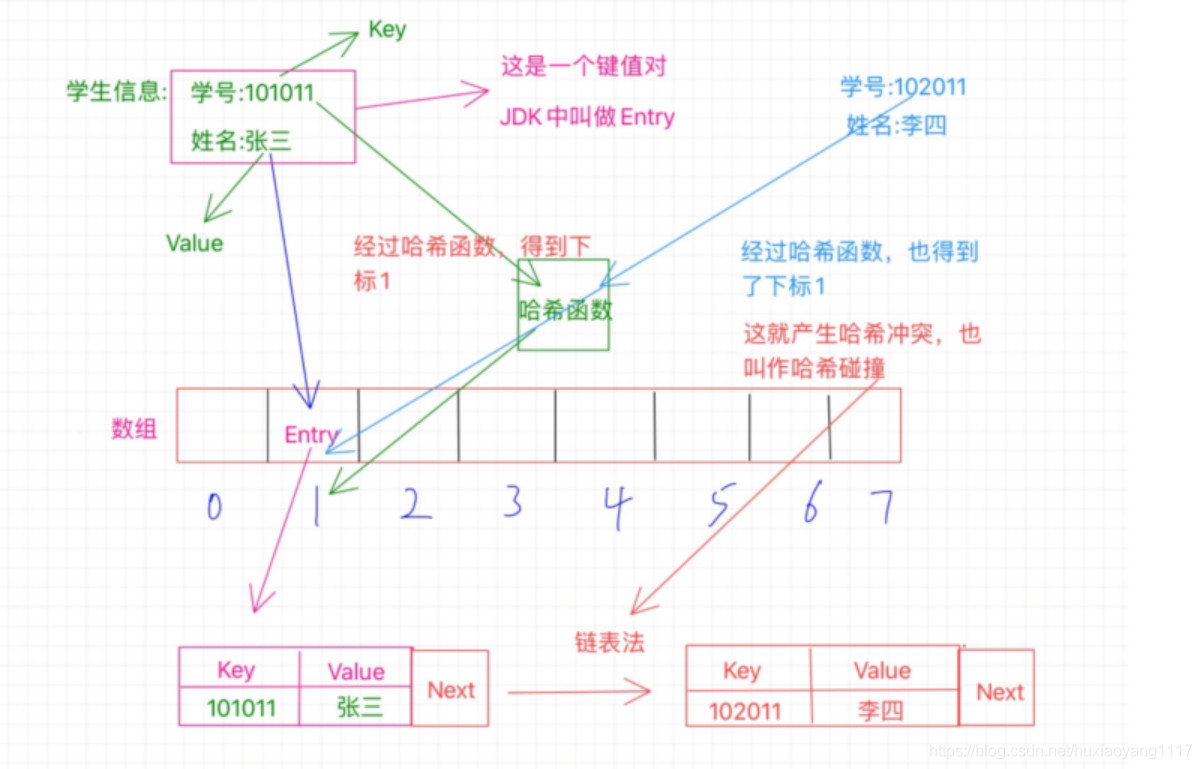
拉链法与开放寻址法不同,还是存在该位置,可是,该位置已经被占用了,就在这个位置这里就采用了链表,什么意思呢?如下图中所示,现在张三和李四都要放在1找个位置上,但是张三先来的,已经占了这个位置,那李四呢?解决办法就是链表,这时候这个1的位置存放的不单单是之前的那个Entry了,此时的Entry还额外的保存了一个next指针,这个指针指向数组外的另外一个位置,将李四安排在这里,然后张三那个Entry中的next指针就指向李四的这个位置,也就是保存的这个位置的内存地址,如果还有冲突,那就把又冲突的那个Entry放在一个新位置上,然后李四的Entry中的next指向它,这样就形成了一个链表。
5、哈希表的扩容
当哈希表被占的位置变多时,哈希冲突的概率就会变高,所以当哈希表被占了一定的位置时,就很有必要对哈希表进行扩容。
这个扩容怎么扩呢,这里会有一个负载因子(增长因子)的概念,简单点说,就是已经被占的位置和总位置的百分比,拿Hashmap 来说,他的负载因子是0.75,当达到这个值的时候,会把原数组进行扩容成原来的2倍,然后把原数组中的所有entry,在 全部重新hash一遍,计算出新的位置,放到新的数组中。
哈希表如何读取数据
我们还用上面那张图,比如我们现在要通过学号102011来查找学生的姓名,怎么操作呢?我们首先通过学号利用哈希函数得出位置1,然后我们就去位置1拿数据啊,拿到这个Entry之后我们得看看这个Entry的key是不是我们的学号102011,如果不是,就根据这个Entry的next知道下一给位置,在比较key,直到成功找到李四,这就是拉链法的读取方式 。而开放寻址法的读取方式也类似,先通过学号利用哈希函数得出位置1,然后我们就去位置1拿数据啊,看拿到的key是否一样,不一样就去下一位置找,在对key进行比较,直到成功找到。
哈希表的核心 哈希函数
在哈希表中,哈希函数的设计很重要,一个好的哈希函数可以极大的提升性能,减少hash冲突的发生。
选取散列函数的可参考的因素:(1)计算散列地址所需的时间;(2)关键字长度;(3)散列表大小;(4)关键字的分布情况;(5)查找记录的频率。
设计哈希函数的方法:
-
直接定址法
取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key) = a·key + b,其中a和b为常数(这种散列函数叫做自身函数)。
-
数字分析法
假设某公司的员工登记表以员工的手机号作为关键字。手机号一共11位。前3位是接入号,对应不同运营商的子品牌;中间4位表示归属地;最后4位是用户号。不同手机号前7位相同的可能性很大,所以可以选择后4位作为散列地址,或者对后4位反转(1234 -> 4321)、循环右移(1234 -> 4123)、循环左移等等之后作为散列地址。数字分析法通常适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的若干位分布比较均匀,就可以考虑这个方法。
-
除留余数法
f(key) = key mod p (p≤m),m为散列表长。这种方法不仅可以对关键字直接取模,也可在折叠、平方取中后再取模。根据经验,若散列表表长为m,通常p为小于或等于表长(最好接近m)的最小质数,可以更好的减小冲突。此方法为最常用的构造散列函数方法。
-
随机数法
f(key) = random(key),这里random是随机函数。当关键字的长度不等时,采用这个方法构造散列函数是比较合适的。
在实际的应用中,不同的情况,用不同的散列函数,如果关键字是英文、中文字符、各种各样的符号,都可以转换为某种数字来处理,比如其他的Unicode编码。
本人是一个刚入行的小白,本篇是学习Hashtable时,所做的学习笔记,如发现问题,请留言,谢谢 !

- 一文搞懂HMM(隐马尔可夫模型)
- 一文搞懂:词法作用域、动态作用域、回调函数、闭包
- 【分类问题中模型的性能度量(二)】超强整理,超详细解析,一文彻底搞懂ROC、AUC
- 一文搞懂浏览器缓存机制
- 一文搞懂 Java 中的枚举,写得非常好
- 一文搞懂MySQL的Join,聊一聊秒杀架构设计
- 猿人进化系列7——一文搞懂IO
- 一文彻底搞懂 Design 设计的 CoordinatorLayout 和 AppbarLayout 联动,让 Design 设计更简单~
- 一文搞懂反向传播算法
- 一文搞懂深度学习正则化的L2范数
- 一文搞懂:词法作用域、动态作用域、回调函数、闭包
- 一文搞懂HTTP协议及相关常见面试题
- 一文让你彻底搞懂BATCH_SIZE
- 一文搞懂双亲委派模型
- 一文搞懂 Webpack 多入口配置
- 一文搞懂交叉熵损失
- 一文搞懂HMM(隐马尔可夫模型)
- 一文搞懂 Python 矩阵和数组的区别
- 一文搞懂最大似然估计法