彻底明白Redis集群主从切换原理
写在前面
参考文章:
- https://www.cnblogs.com/dadonggg/p/8628735.html
1.Redis Cluster
为了支持高可用,Redis提供了集群部署方案,当master发生故障时,能及时进行主从切换。
redis-cli 使用参数【-c】连接集群中任意一个节点,无论是主还是从,都没有任何区别,都能访问整个集群。
Jedis使用JedisCluster时也一样,配置一个节点即可访问整个集群,配置多个更安全。
这是因为Redis集群是去中心化的,每个节点都维护着集群所有节点的信息。
2.什么是主从切换?
主从切换是指某个master不可用时,它的其中一个从节点升级为master的操作。
通过投票机制来判断master是否不可用,参与投票的是所有的master,所有的master之间维持着心跳,如果一半以上的master确定某个master失联,则集群认为该master挂掉,此时发生主从切换。
通过选举机制来确定哪一个从节点升级为master。选举的依据依次是:网络连接正常->5秒内回复过INFO命令->10*down-after-milliseconds内与主连接过的->从服务器优先级->复制偏移量->运行id较小的。选出之后通过slaveif no ont将该从服务器升为新master。
通过配置文件参数【cluster-node-timeout】指定心跳超时时间,默认是15秒。
3. 集群信息
在任意节点执行[cluster nodes]命令都能查询集群信息,因为每个节点都维护集群信息,而且一般情况下都是相同的,例如:

每列信息是:
[runid] [ip:port] [flags] [mster_runid] [ping-sent] [pong-recv] [config-epoch] [link-state] [hash slot]
详细解释:
-
runid: 该行描述的节点的id。
-
ip:prot: 该行描述的节点的ip和port
-
flags: 逗号分隔的标记位,可能的值有:
master: 该行描述的节点是master slave: 该行描述的节点是slave fail?:该行描述的节点可能不可用 fail:该行描述的节点不可用(故障)
-
master_runid: 该行描述的节点的master的id,如果本身是master则显示-
-
ping-sent: 最近一次发送ping的Unix时间戳,0表示未发送过
-
pong-recv:最近一次收到pong的Unix时间戳,0表示未收到过
-
config-epoch: 好像是主从切换的次数
-
link-state: 连接状态,connnected 和 disconnected
-
hash slot: 该行描述的master中存储的key的hash的范围
默认情况下,每个节点都会持久化集群信息到workdir下的[ndoes-6379.conf]文件中,用于节点重启后能够正确的加入集群。
4. 主从切换日志
可通过日志,观察主从切换:

如上图所示:集群中有9个节点,端口分别是7001~7009
7007的master在10:38:29时发现失联,此时状态是[disconnected],
15秒后在10:38:45时,被确定为不可用,此时状态是[fail]。
并在下一秒即10:38:46时完成主从切换,7007原来的从节点7006升级为master。
5. 从节点重启
slave重启时,会根据集群信息加入到集群;首先检查master是否在线,如果在线则自动成为其slave;如果master不在线,则成为新master的slave。
Redis的主从关系是链式的,一个从节点也是可以拥有从节点的,所以一个当一个slave重启时,如果其原来的master现在也是从节点的,但是该slave仍然会成为它的从节点,就出现了从节点的从节点。
6. 从节点均衡
当某个master无可用的slave时,Redis Cluster会尝试将其他master的slave转移给这个master,作为它的从节点。
7. 集群不可用
当集群不可用时,客户端会收到 【CLUSTERDOWN the cluster is down 】的错误信息;也可以通过命令【cluster info】查看一个集群的状态,如果输出的【cluster_stat】是ok说明状态正常,如果是fail,则说明集群不可用,如下图:
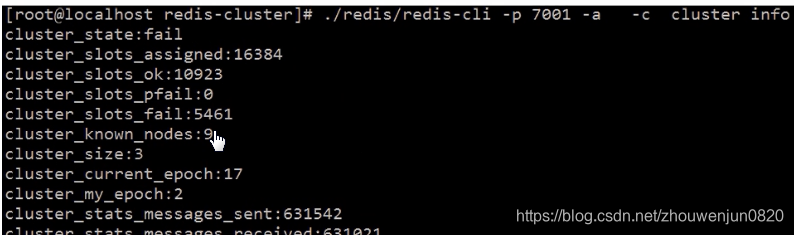
在以下3种情况下,集群会不可用:
- 某个master和其slave同时失联。
- 某个master失联,并且其无slave。
- 超过半数的master同时失联。
可以发现这三种情况均是master不可用并且无法进行主从切换,而只有master支持写操作,所以此时集群不可用。
下面通过日志观察集群不可用:

如上图所示,在 11:19:10 同时关闭master(7004)和其所有slave,3个节点的连接状态立刻变成 disconnected,
在 11:19:31 时master(7004)被判断为fail状态,并且此时无可用的slave,因此 cluster_state 变成 fail, 此时客户端任何指令都将响应: cluster is down
注意在 11:19:10 ~ 11:19:30 之间,集群状态是ok,客户端如果不访问master(7004)则无异常,如果访问master(7004),因为该节点已关闭,所以操作系统会响应: Connection Refused
8. 集群容错测试
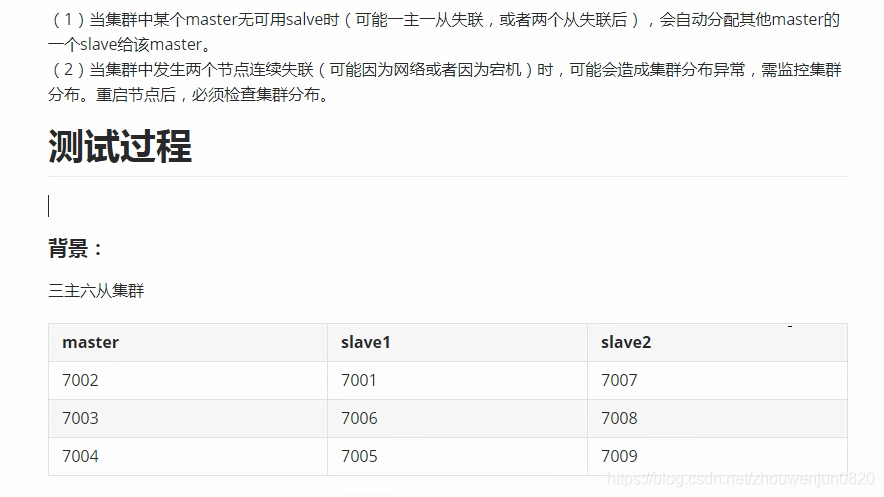
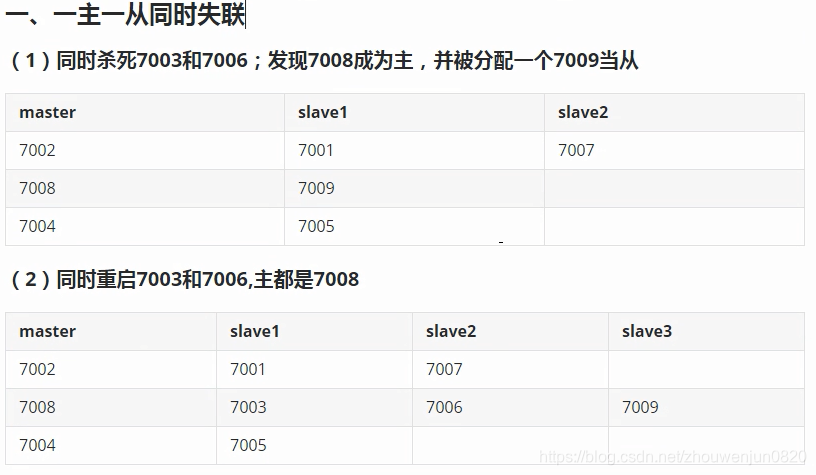
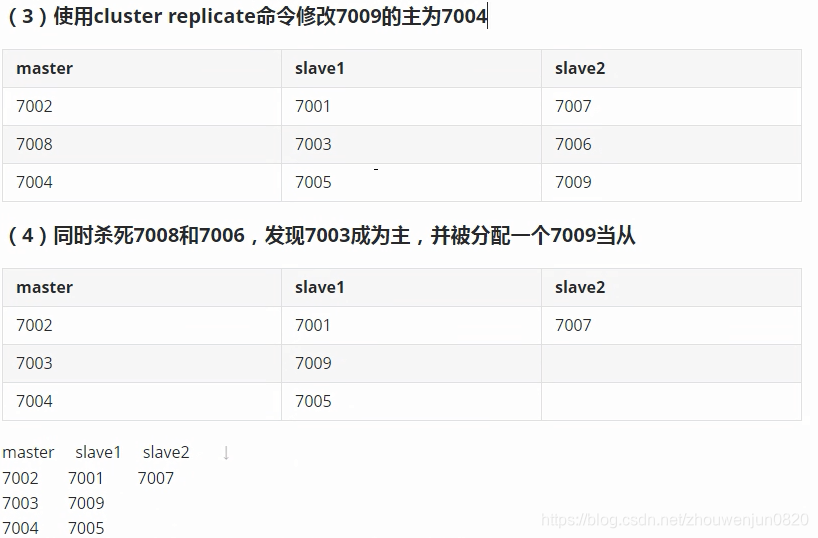
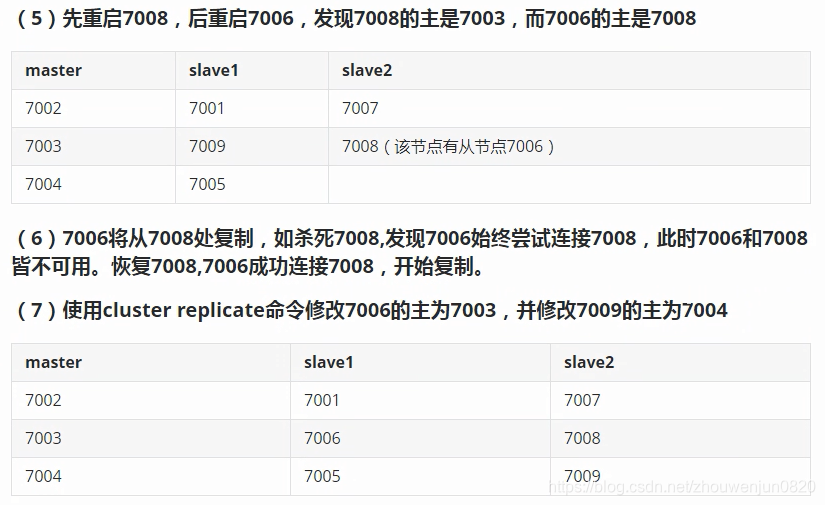
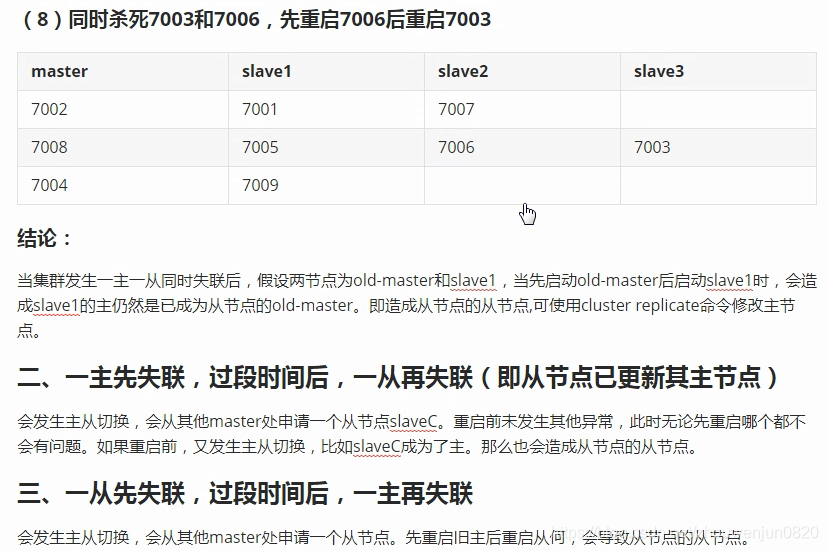
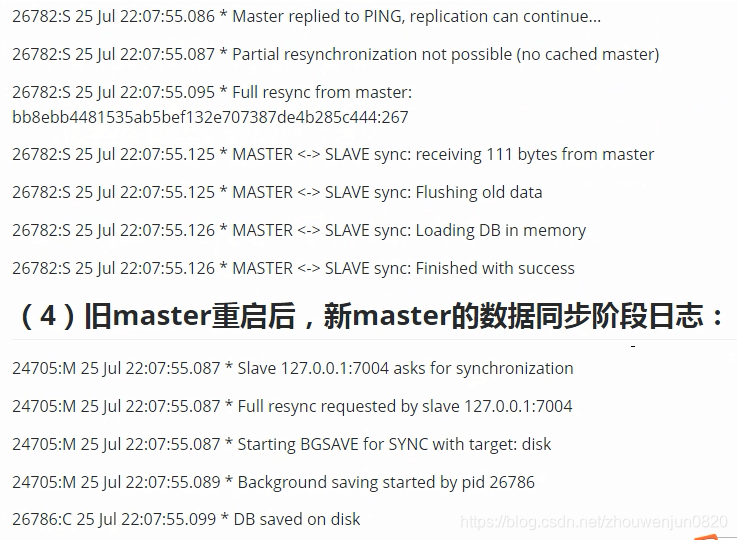
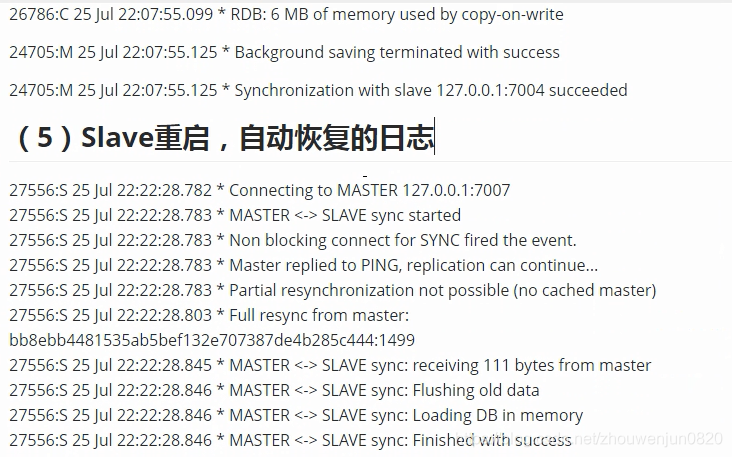
9. 典型日志整理

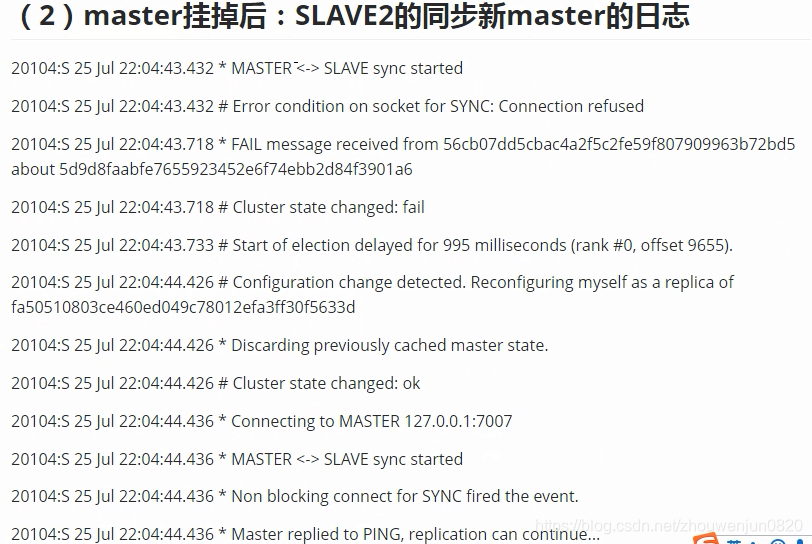
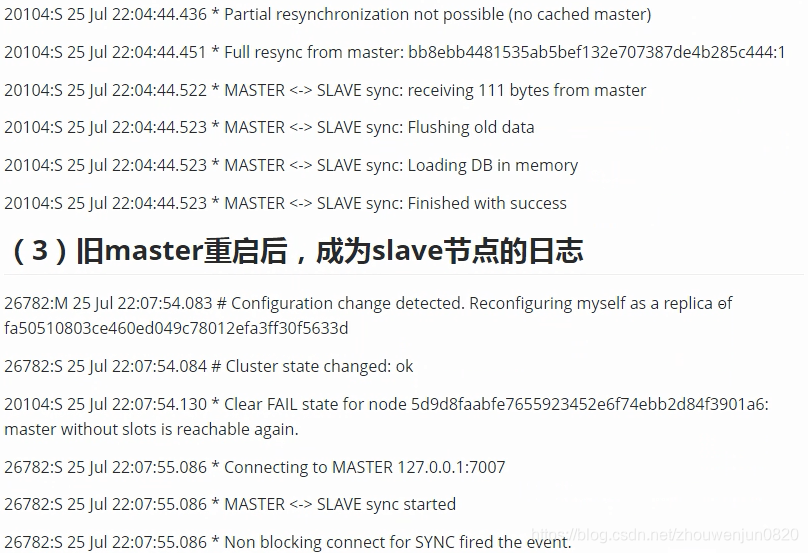


- Redis集群redis主从自动切换Sentinel(哨兵模式)
- redis原理及集群主从配置
- Redis集群(九):Redis Sharding集群Redis节点主从切换后客户端自动重新连接
- redis主从切换的集群管理
- redis 集群如何手动切换主从
- redis sentinel 集群配置-主从切换
- redis集群核心原理:gossip通信、jedis Smart定位、主备切换
- Redis集群_3.redis主从自动切换Sentinel(转)
- redis主从切换的集群管理
- Redis集群 - redis主从配置初步:简单主从切换(哨兵模式)
- redis主从复制和集群实现原理
- redis集群主从切换,jedis客户端如何自动切换访问
- redis主从切换的集群管理
- Redis集群:redis主从自动切换Sentinel
- Redis 集群方案- 主从切换测试
- Redis集群_3.redis 主从自动切换Sentinel
- redis主从复制和集群实现原理
- redis原理及集群主从配置
- redis 非集群的主从配置及切换
- Redis集群_3.redis主从自动切换Sentinel