Ubuntu 16.04 shell 命令使用小结
1.解压文件:
sudo tar -zxvf ./下载/eclipse-jee-neon-a-linux-gtk-x86_64.tar.gz -C /usr/lib/jvm
2.删除文件:sudo rm -rf 文件(夹)名
3.重定向文件:cd usr/lib/jvm
4.卸载软件:sudo apt-get purge remove 软件名
5.移动文件:sudo mv jdk-8u121-linux-x64.tar.gz /opt/java
6.给文件重命名:
mv hive-default.xml.template hive-default.xml
7.修改配置文件:
vim hive-site.xml
8.启动 mysql 😒 mysql -u root -p
9.退出mysql: mysql>quit
10.启动hadoop:
$ cd /usr/local/hadoop #进入Hadoop安装目录
$ ./sbin/start-dfs.sh
11.启动hive:
$ cd /usr/local/hive
$ ./bin/hive
12.

“无法访问”原因——spark 2 中不存在spark-assembly-.jar,所以hive没有办法找到这个JAR包。
解决办法: 修改//bin/hive文件,将SPARK_HOME后面的lib/spark-assembly-.jar替换成jars/*.jar,

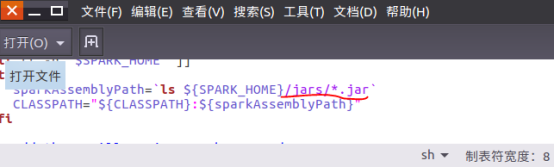


问题解决。
13.

Loggin initialized using configuration in jar:file:/usr/local/hive/lib/hive-common-1.2.1.jar!/hive-long4j.properties
Exception in thread “main” java.lang.RuntimeException:
原因:standby异常,namenode没有激活。由于hive是基于hadoop集群运行的,需要将我们搭的hadoop HA集群的NameNode激活。
14. 针对 DataNode 没法启动解决方法(注意这会删除 HDFS 中原有所有数据):
$cd /usr/local/hadoop
$./sbin/stop-dfs.sh # 关闭
$rm -r ./tmp # 删除 tmp 文件,注意这会删除 HDFS 中原有的所有数据
$./bin/hdfs namenode -format # 重新格式化 NameNode
$./sbin/start-dfs.sh # 重启

- 使用shell命令小结
- Ubuntu 16.04下Shell脚本中使用数组提示:Syntax error: "(" unexpected
- ubuntu16.04安装vim及vim的命令使用方法
- ubuntu16.04安装pycharm生成快捷方式以及命令使用说明
- ubuntu 16.04 使用较多的压缩和解压命令
- ubuntu shell 使用命令大全
- ubuntu16.04使用命令启动tomcat
- shell脚本的sed命令使用小结
- ubuntu 使用adb shell命令识别android设备
- Ubuntu 16.04 使用小结
- 使用新的 apt 命令在 Ubuntu 16.04 LTS 下管理软件包
- Ubuntu 16.04 apt终端命令的使用以及软件的安装和卸载
- shell 中find和xargs命令使用小结
- Ubuntu 16.04 apt终端命令的使用以及软件的安装和卸载
- Android 使用 shell 命令小结
- Ubuntu 16.04下在Shell终端下使用nautilus快速打开窗口文件夹
- ubuntu 使用adb shell命令配置
- 使用新的 apt 命令在 Ubuntu 16.04 LTS 下管理软件包
- shell命令使用小记
- 使用mount命令在Ubuntu上挂接Windows的共享文件夹