基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(一)
系列文章
- 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目
- 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来
- 基于 abp vNext 和 .NET Core 开发博客项目 - 完善与美化,Swagger登场
- 基于 abp vNext 和 .NET Core 开发博客项目 - 数据访问和代码优先
- 基于 abp vNext 和 .NET Core 开发博客项目 - 自定义仓储之增删改查
- 基于 abp vNext 和 .NET Core 开发博客项目 - 统一规范API,包装返回模型
- 基于 abp vNext 和 .NET Core 开发博客项目 - 再说Swagger,分组、描述、小绿锁
- 基于 abp vNext 和 .NET Core 开发博客项目 - 接入GitHub,用JWT保护你的API
- 基于 abp vNext 和 .NET Core 开发博客项目 - 异常处理和日志记录
- 基于 abp vNext 和 .NET Core 开发博客项目 - 使用Redis缓存数据
- 基于 abp vNext 和 .NET Core 开发博客项目 - 集成Hangfire实现定时任务处理
- 基于 abp vNext 和 .NET Core 开发博客项目 - 用AutoMapper搞定对象映射
- 基于 abp vNext 和 .NET Core 开发博客项目 - 定时任务最佳实战(一)
- 基于 abp vNext 和 .NET Core 开发博客项目 - 定时任务最佳实战(二)
- 基于 abp vNext 和 .NET Core 开发博客项目 - 定时任务最佳实战(三)
从本篇就开始博客页面的接口开发了,其实这些接口我是不想用文字来描述的,太枯燥太无趣了。全是CRUD,谁还不会啊,用得着我来讲吗?想想为了不半途而废,为了之前立的Flag,还是咬牙坚持吧。
准备工作
现在博客数据库中的数据是比较混乱的,为了看起来像那么回事,显得正式一点,我先手动搞点数据进去。
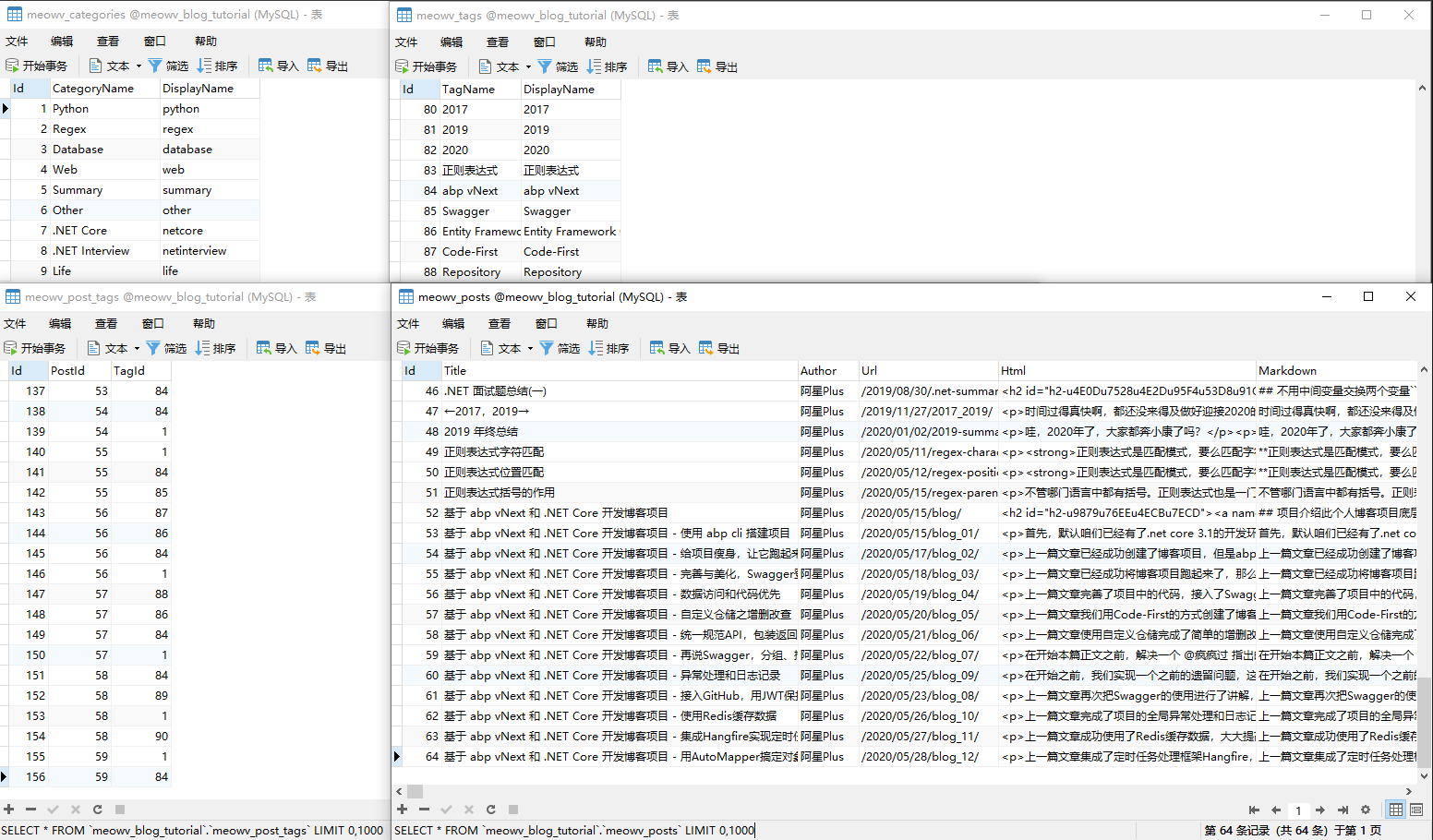
搞定了种子数据,就可以去愉快的写接口了,我这里将根据我现在的博客页面去分析所需要接口,感兴趣的去点点。
为了让接口看起来清晰,一目了然,删掉之前在
IBlogService中添加的所有接口,将5个自定义仓储全部添加至
BlogService中,然后用
partial修饰。
//IBlogService.cs
public partial interface IBlogService
{
}
//BlogService.cs
using Meowv.Blog.Application.Caching.Blog;
using Meowv.Blog.Domain.Blog.Repositories;
namespace Meowv.Blog.Application.Blog.Impl
{
public partial class BlogService : ServiceBase, IBlogService
{
private readonly IBlogCacheService _blogCacheService;
private readonly IPostRepository _postRepository;
private readonly ICategoryRepository _categoryRepository;
private readonly ITagRepository _tagRepository;
private readonly IPostTagRepository _postTagRepository;
private readonly IFriendLinkRepository _friendLinksRepository;
public BlogService(IBlogCacheService blogCacheService,
IPostRepository postRepository,
ICategoryRepository categoryRepository,
ITagRepository tagRepository,
IPostTagRepository postTagRepository,
IFriendLinkRepository friendLinksRepository)
{
_blogCacheService = blogCacheService;
_postRepository = postRepository;
_categoryRepository = categoryRepository;
_tagRepository = tagRepository;
_postTagRepository = postTagRepository;
_friendLinksRepository = friendLinksRepository;
}
}
}
在Blog文件夹下依次添加接口:
IBlogService.Post.cs、
IBlogService.Category.cs、
IBlogService.Tag.cs、
IBlogService.FriendLink.cs、
IBlogService.Admin.cs。
在Blog/Impl文件夹下添加实现类:
IBlogService.Post.cs、
BlogService.Category.cs、
BlogService.Tag.cs、
BlogService.FriendLink.cs、
BlogService.Admin.cs。
同上,
.Application.Caching层也按照这个样子添加。
注意都需要添加partial修饰为局部的接口和实现类,所有文章相关的接口放在
IBlogService.Post.cs中,分类放在
IBlogService.Category.cs,标签放在
IBlogServic 1044 e.Tag.cs,友链放在
IBlogService.FriendLink.cs,后台增删改所有接口放在
IBlogService.Admin.cs,最终效果图如下:
文章列表页
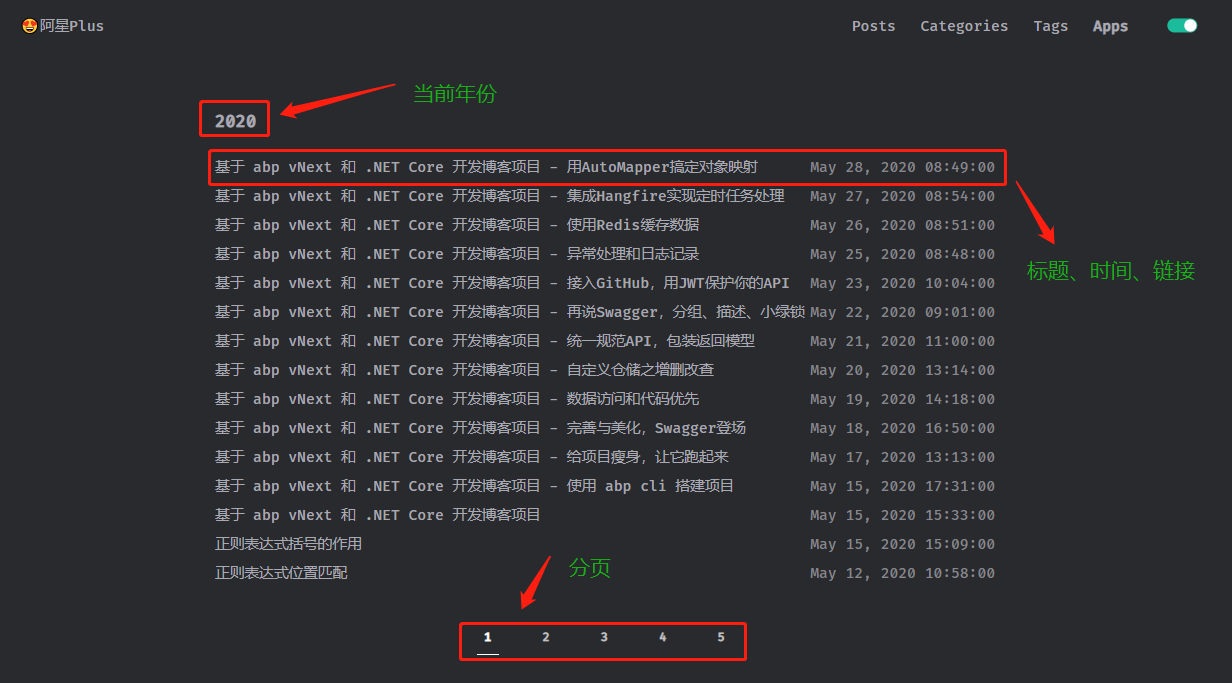
分析:列表带分页,以文章发表的年份分组,所需字段:标题、链接、时间、年份。
在
.Application.Contracts层Blog文件夹下添加返回的模型:
QueryPostDto.cs。
//QueryPostDto.cs
using System.Collections.Generic;
namespace Meowv.Blog.Application.Contracts.Blog
{
public class QueryPostDto
{
/// <summary>
/// 年份
/// </summary>
public int Year { get; set; }
/// <summary>
/// Posts
/// </summary>
public IEnumerable<PostBriefDto> Posts { get; set; }
}
}
模型为一个年份和一个文章列表,文章列表模型:
PostBriefDto.cs。
//PostBriefDto.cs
namespace Meowv.Blog.Application.Contracts.Blog
{
public class PostBriefDto
{
/// <summary>
/// 标题
/// </summary>
public string Title { get; set; }
/// <summary>
/// 链接
/// </summary>
public string Url { get; set; }
/// <summary>
/// 年份
/// </summary>
public int Year { get; set; }
/// <summary>
/// 创建时间
/// </summary>
public string CreationTime{ get; set; }
}
}
搞定,因为返回时间为英文格式,所以
CreationTime给了字符串类型。
在
IBlogService.Post.cs中添加接口分页查询文章列表
QueryPostsAsync,肯定需要接受俩参数分页页码和分页数量。还是去添加一个公共模型
PagingInput吧,在
.Application.Contracts下面。
//PagingInput.cs
using System.ComponentModel.DataAnnotations;
namespace Meowv.Blog.Application.Contracts
{
/// <summary>
/// 分页输入参数
/// </summary>
public class PagingInput
{
/// <summary>
/// 页码
/// </summary>
[Range(1, int.MaxValue)]
public int Page { get; set; } = 1;
/// <summary>
/// 限制条数
/// </summary>
[Range(10, 30)]
public int Limit { get; set; } = 10;
}
}
Page设置默认值为1,
Limit设置默认值为10,
Range Attribute设置参数可输入大小限制,于是这个分页查询文章列表的接口就是这个样子的。
//IBlogService.Post.cs
public partial interface IBlogService
{
/// <summary>
/// 分页查询文章列表
/// </summary>
/// <param name="input"></param>
/// <returns></returns>
Task<ServiceResult<PagedList<QueryPostDto>>> QueryPostsAsync(PagingInput input);
}
ServiceResult和
PagedList是之前添加的统一返回模型,紧接着就去添加一个分页查询文章列表缓存接口,和上面是对应的。
//IBlogCacheService.Post.cs
using Meowv.Blog.Application.Contracts;
using Meowv.Blog.Application.Contracts.Blog;
using Meowv.Blog.ToolKits.Base;
using System;
using System.Threading.Tasks;
namespace Meowv.Blog.Application.Caching.Blog
{
public partial interface IBlogCacheService
{
/// <summary>
/// 分页查询文章列表
/// </summary>
/// <param name="input"></param>
/// <param
15a8
name="factory"></param>
/// <returns></returns>
Task<ServiceResult<PagedList<QueryPostDto>>> QueryPostsAsync(PagingInput input, Func<Task<ServiceResult<PagedList<QueryPostDto>>>> factory);
}
}
分别实现这两个接口。
//BlogCacheService.Post.cs
public partial class BlogCacheService
{
private const string KEY_QueryPosts = "Blog:Post:QueryPosts-{0}-{1}";
/// <summary>
/// 分页查询文章列表
/// </summary>
/// <param name="input"></param>
/// <param name="factory"></param>
/// <returns></returns>
public async Task<ServiceResult<PagedList<QueryPostDto>>> QueryPostsAsync(PagingInput input, Func<Task<ServiceResult<PagedList<QueryPostDto>>>> factory)
{
return await Cache.GetOrAddAsync(KEY_QueryPosts.FormatWith(input.Page, input.Limit), factory, CacheStrategy.ONE_DAY);
}
}
//BlogService.Post.cs
/// <summary>
/// 分页查询文章列表
/// </summary>
/// <param name="input"></param>
/// <returns></returns>
public async Task<ServiceResult<PagedList<QueryPostDto>>> QueryPostsAsync(PagingInput input)
{
return await _blogCacheService.QueryPostsAsync(input, async () =>
{
var result = new ServiceResult<PagedList<QueryPostDto>>();
var count = await _postRepository.GetCountAsync();
var list = _postRepository.OrderByDescending(x => x.CreationTime)
.PageByIndex(input.Page, input.Limit)
.Select(x => new PostBriefDto
{
Title = x.Title,
Url = x.Url,
Year = x.CreationTime.Year,
CreationTime= x.CreationTime.TryToDateTime()
}).GroupBy(x => x.Year)
.Select(x => new QueryPostDto
{
Year = x.Key,
Posts = x.ToList()
}).ToList();
result.IsSuccess(new PagedList<QueryPostDto>(count.TryToInt(), list));
return result;
});
}
PageByIndex(...)、
TryToDateTime()是
.ToolKits层添加的扩展方法,先查询总数,然后根据时间倒序,分页,筛选出所需字段,根据年份分组,输出,结束。
在
BlogController中添加API。
/// <summary>
/// 分页查询文章列表
/// </summary>
/// <param name="input"></param>
/// <returns></returns>
[HttpGet]
[Route("posts")]
public async Task<ServiceResult<PagedList<QueryPostDto>>> QueryPostsAsync([FromQuery] PagingInput input)
{
return await _blogService.QueryPostsAsync(input);
}
[FromQuery]设置input为从URL进行查询参数,编译运行看效果。
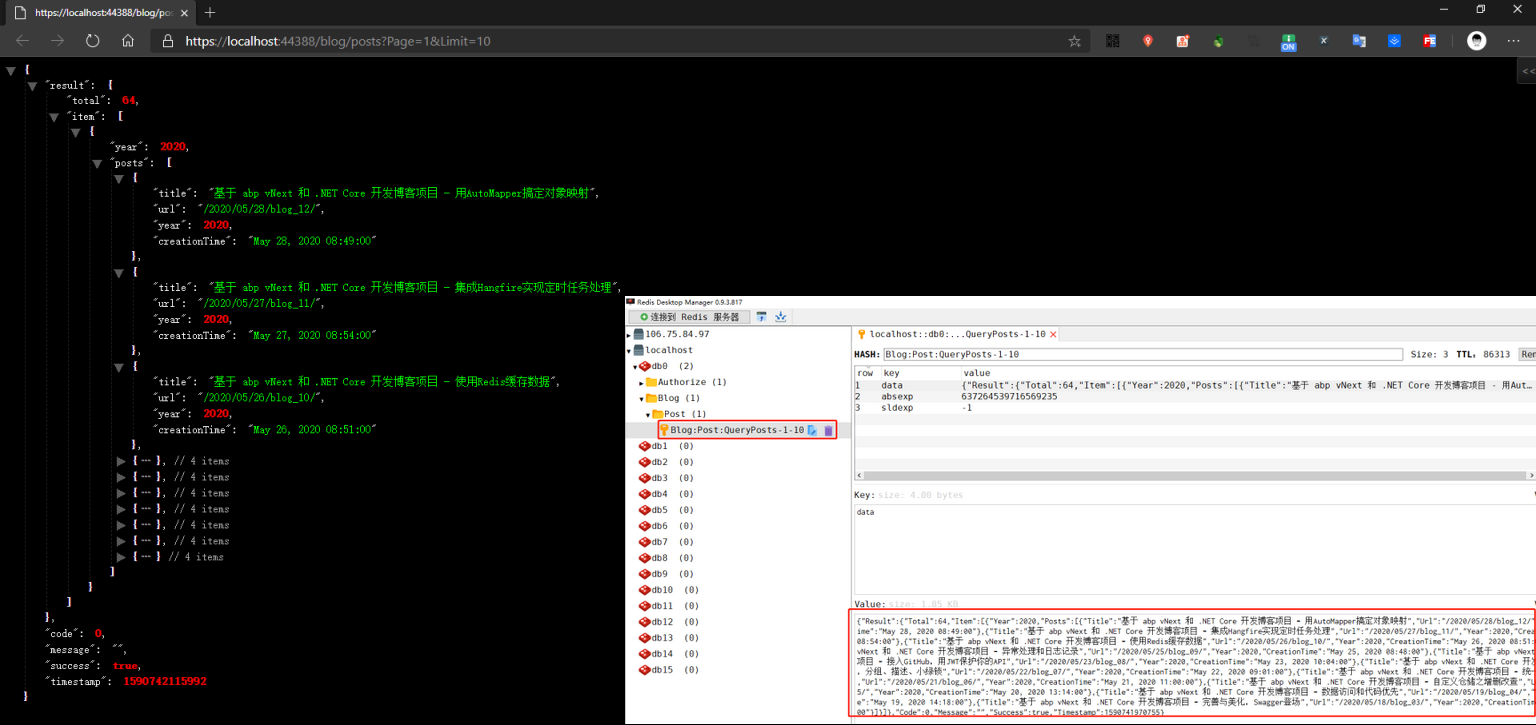
已经可以查询出数据,并且缓存至Redis中。
获取文章详情
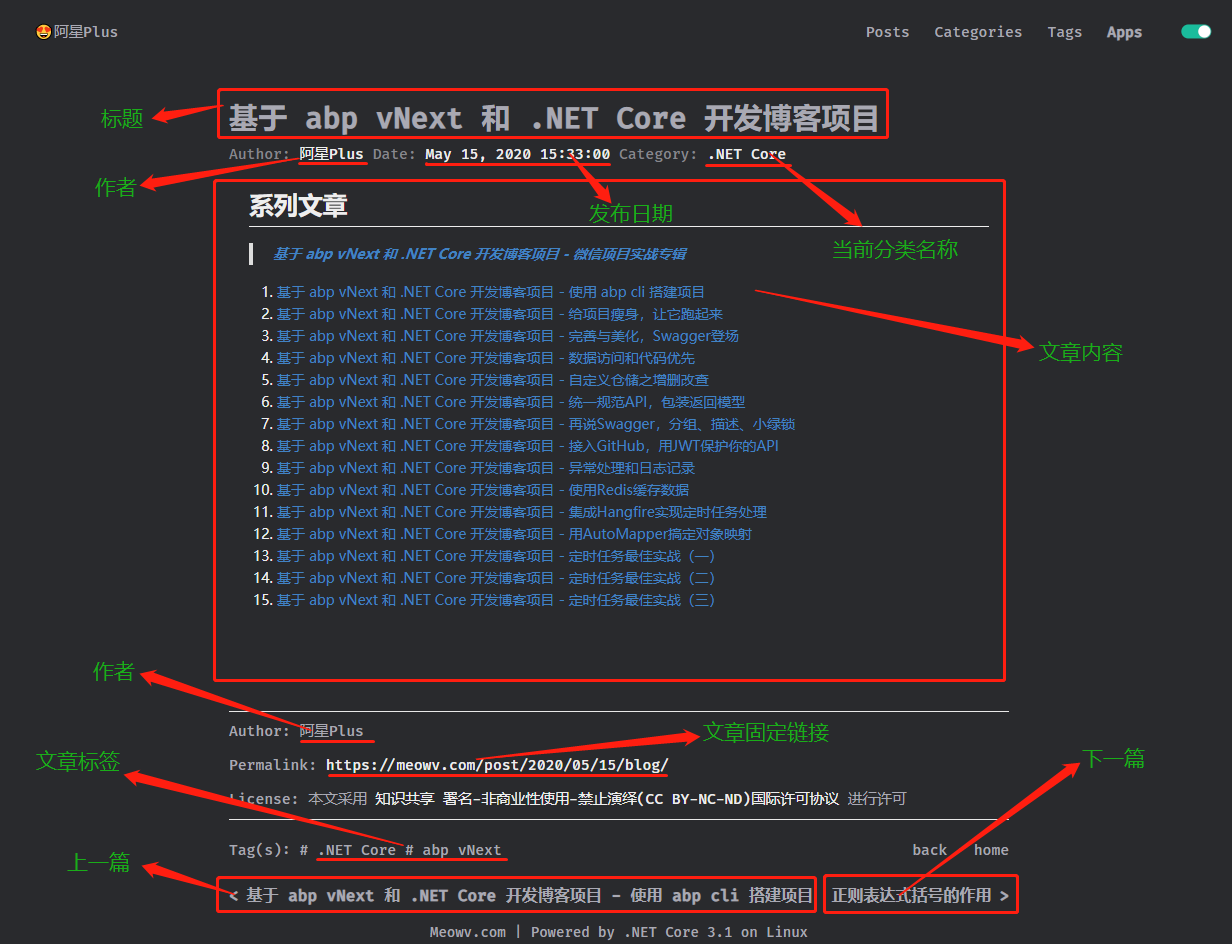
分析:文章详情页,文章的标题、作者、发布时间、所属分类、标签列表、文章内容(HTML和MarkDown)、链接、上下篇的标题和链接。
创建返回模型:
PostDetailDto.cs
//PostDetailDto.cs
using System.Collections.Generic;
namespace Meowv.Blog.Application.Contracts.Blog
{
public class PostDetailDto
{
/// <summary>
/// 标题
/// </summary>
public string Title { get; set; }
/// <summary>
/// 作者
/// </summary>
public string Author { get; set; }
/// <summary>
/// 链接
/// </summary>
public string Url { get; set; }
/// <summary>
/// HTML
/// </summary>
public string Html { get; set; }
/// <summary>
/// Markdown
/// </summary>
public string Markdown { get; set; }
/// <summary>
/// 创建时间
/// </summary>
public string CreationTime{ get; set; }
/// <summary>
/// 分类
/// </summary>
public CategoryDto Category { get; set; }
/// <summary>
/// 标签列表
/// </summary>
public IEnumerable<TagDto> Tags { get; set; }
/// <summary>
/// 上一篇
/// </summary>
public PostForPagedDto Previous { get; set; }
/// <summary>
/// 下一篇
/// </summary>
public PostForPagedDto Next { get; set; }
}
}
同时添加
CategoryDto、
TagDto、PostForPagedDto。
//CategoryDto.cs
namespace Meowv.Blog.Application.Contracts.Blog
{
public class CategoryDto
{
/// <summary>
/// 分类名称
/// </summary>
public string CategoryName { get; set; }
/// <summary>
/// 展示名称
/// </summary>
public string DisplayName { get; set; }
}
}
//TagDto.cs
namespace Meowv.Blog.Application.Contracts.Blog
{
public class TagDto
{
/// <summary>
/// 标签名称
/// </summary>
public string TagName { get; set; }
/// <summary>
/// 展示名称
/// </summary>
public string DisplayName { get; set; }
}
}
//PostForPagedDto.cs
namespace Meowv.Blog.Application.Contracts.Blog
{
public class PostForPagedDto
{
/// <summary>
/// 标题
/// </summary>
public string Title { get; set; }
/// <summary>
/// 链接
/// </summary>
public string Url { get; set; }
}
}
添加获取文章详情接口和缓存的接口。
//IBlogService.Post.cs
public partial interface IBlogService
{
/// <summary>
/// 根据URL获取文章详情
/// </summary>
/// <param name="url"></param>
/// <returns></returns>
Task<ServiceResult<PostDetailDto>> GetPostDetailAsync(string url);
}
//IBlogCacheService.Post.cs
public partial interface IBlogCacheService
{
/// <summary>
/// 根据URL获取文章详情
/// </summary>
/// <param name="url"></param>
/// <returns></returns>
Task<ServiceResult<PostDetailDto>> GetPostDetailAsync(string url, Func<Task<ServiceResult<PostDetailDto>>> factory);
}
分别实现这两个接口。
//BlogCacheService.Post.cs
public partial class BlogCacheService
{
private const string KEY_GetPostDetail = "Blog:Post:GetPostDetail-{0}";
/// <summary>
/// 根据URL获取文章详情
/// </summary>
/// <param name="url"></param>
/// <param name="factory"></param>
/// <returns></returns>
public async Task<ServiceResult<PostDetailDto>> GetPostDetailAsync(string url, Func<Task<ServiceResult<PostDetailDto>>> factory)
{
return await Cache.GetOrAddAsync(KEY_GetPostDetail.FormatWith(url), factory, CacheStrategy.ONE_DAY);
}
}
//BlogService.Post.cs
/// <summary>
/// 根据URL获取文章详情
/// </summary>
/// <param name="url"></param>
/// <returns></returns>
public async Task<ServiceResult<PostDetailDto>> GetPostDetailAsync(string url)
{
return await _blogCacheService.GetPostDetailAsync(url, async () =>
{
var result = new ServiceResult<PostDetailDto>();
var post = await _postRepository.FindAsync(x => x.Url.Equals(url));
if (null == post)
{
result.IsFailed(ResponseText.WHAT_NOT_EXIST.FormatWith("URL", url));
return result;
}
var category = await _categoryRepository.GetAsync(post.CategoryId);
var tags = from post_tags in await _postTagRepository.GetListAsync()
join tag in await _tagRepository.GetListAsync()
on post_tags.TagId equals tag.Id
where post_tags.PostId.Equals(post.Id)
select new TagDto
{
TagName = tag.TagName,
DisplayName = tag.DisplayName
};
var previous = _postRepository.Where(x => x.CreationTime> post.CreationTime).Take(1).FirstOrDefault();
var next = _postRepository.Where(x => x.CreationTime< post.CreationTime).OrderByDescending(x => x.CreationTime).Take(1).FirstOrDefault();
var postDetail = new PostDetailDto
{
Title = post.Title,
Author = post.Author,
Url = post.Url,
Html = post.Html,
Markdown = post.Markdown,
CreationTime= post.CreationTime.TryToDateTime(),
Category = new CategoryDto
{
CategoryName = category.CategoryName,
DisplayName = category.DisplayName
},
Tags = tags,
Previous = previous == null ? null : new PostForPagedDto
{
Title = previous.Title,
Url = previous.Url
},
Next = next == null ? null : new PostForPagedDto
{
Title = next.Title,
Url = next.Url
}
};
result.IsSuccess(postDetail);
return result;
});
}
ResponseText.WHAT_NOT_EXIST是定义在
MeowvBlogConsts.cs的常量。
TryToDateTime()和列表查询中的扩展方法一样,转换时间为想要的格式。
简单说一下查询逻辑,先根据参数url,查询是否存在数据,如果文章不存在则返回错误消息。
然后根据
post.CategoryId就可以查询到当前文章的分类名称。
联合查询post_tags和tag两张表,指定查询条件post.Id,查询当前文章的所有标签。
最后上下篇的逻辑也很简单,上一篇取大于当前文章发布时间的第一篇,下一篇取时间倒序排序并且小于当前文章发布时间的第一篇文章。
最后将所有查询到的数据赋值给输出对象,返回,结束。
在
BlogController中添加API。
/// <summary>
/// 根据URL获取文章详情
/// </summary>
/// <param name="url"></param>
/// <returns></returns>
[HttpGet]
[Route("post")]
public async Task<ServiceResult<PostDetailDto>> GetPostDetailAsync(string url)
{
return await _blogService.GetPostDetailAsync(url);
}
编译运行,然后输入URL查询一条文章详情数据。
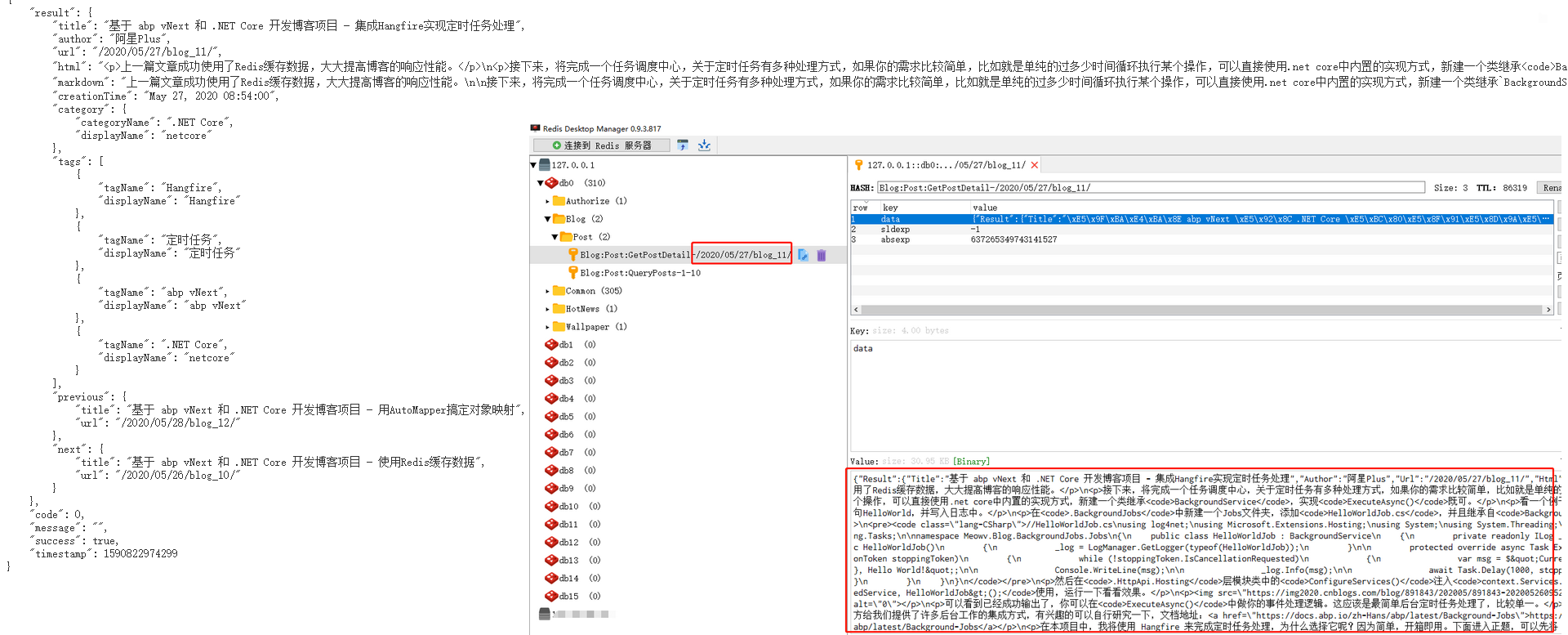
成功输出预期内容,缓存同时也是ok的。
开源地址:https://github.com/Meowv/Blog/tree/blog_tutorial
搭配下方课程学习更佳 ↓ ↓ ↓


- 基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(三)
- IOS8开发之:基于Swift实战UI从入门到精通(5大项目、深入解析拉手团购项目)
- 项目视频讲解_基于SSH2+Maven+EasyUI+MySQL技术实战开发易买网电子商务交易平台
- 北风网基于ASP.NET技术下多用户博客系统全程实战开发(NNblog)
- 基于 Laravel 开发博客应用系列 —— 从测试开始(一):创建项目和PHPUnit
- 基于ASP.NET WPF技术及MVP模式实战太平人寿客户管理项目开发(Repository模式)
- java博客开发项目实战(完整)
- 项目实战(连载):基于Angular2+Mongodb+Node技术实现的多用户博客系统教程(1)
- 学习笔记(十八)项目实战接口开发SprintBoot
- 项目视频讲解_基于Weblogic、Oracle实战开发企业级CRM客户关系管理系统(Jquery、存储过程)新
- 项目视频讲解_基于Flex4.X+BlazeDS+Spring3+JPA+Hibernate+MySQL实战开发在线书店
- 项目实战(连载):基于Angular2+Mongodb+Node技术实现的多用户博客系统教程(2)
- Node.js项目实战-构建可扩展的Web应用(第一版):3 Node.js基于Mocha的测试驱动开发和行为驱动开发
- Java系列--第七篇 基于Maven的Android开发实战项目
- 学习笔记(十七)项目实战接口开发SprintBoot
- Swift项目开发实战-基于分层架构的多版本iPhone计算器-直播公开课
- 项目实战(连载):基于Angular2+Mongodb+Node技术实现的多用户博客系统教程(3)
- 基于ASP.NET WPF技术及MVP模式实战太平人寿客户管理项目开发(Repository模式)课程分享
- 分享一个基于Net Core 3.1开发的模块化的项目
- 2019最新java博客项目开发项目实战(完整)