JNI方法实现图片压缩(压缩率极高)
前言
直接使用项目或直接复制libs中的so库到项目中即可(当前只构建了armeabi),需要其他ABI可检下项目另外使用CMake构建即可。
结果预览:
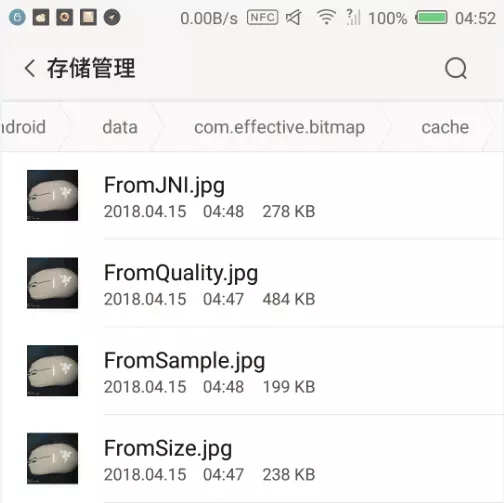
效果图.png

jni_278KB.png

quality_484KB.png

sample_199KB.png

size_238KB.png
原图大小5.99M~~ 我们把所有经过压缩的图片放到同等大小的情况后,很明显,采样压缩跟尺寸压缩都不是我们想要的结果,而质量压缩跟JNI压缩我设置的质量压缩值都是30,JNI压缩出来只有278KB,直接质量压缩出来的有484KB,综合之后,JNI才是综合最优的方式,当然,如果只是头像,我们设置可以把配置值设置得更小,图片就更小。
为什么iPhone手机图片的质量比Android的好?
首先了解两个图像处理库:libjpeg、Skia。
Skia:图像处理引擎,Google在Android系统上就是采用Skia,它是基于libjpeg的二次封装,Google在很多其它产品也使用了这个库,比如Chorme,Firefox等等。
libjpeg:早期的图像处理引擎,用于PC端。
官方文档可以看到libjpeg.doc这样一段话:
boolean optimize_coding
TRUE causes the compressor to compute optimal Huffman coding tables
for the image. This requires an extra pass over the data and
therefore costs a good deal of space and time. The default is
FALSE, which tells the compressor to use the supplied or default
Huffman tables. In most cases optimal tables save only a few percent
of file size compared to the default tables. Note that when this is
TRUE, you need not supply Huffman tables at all, and any you do
supply will be overwritten.
boolean optimize_coding:
- 参数为TRUE时,图片压缩算法使用最优的哈夫曼编码表,它需要额外传递数据,因此会耗费CPU运算时间,以及开辟很多临时内存空间。
- 参数为FALSE时,使用默认的哈夫曼编码表。在大多数情况,使用最优哈夫曼编码表相比默认哈夫曼编码表,能节省图像文件很大比例的大小。
为什么使用最优哈夫曼编码表可以节省图像文件很大的比例大小呢?
哈夫曼树和哈夫曼编码
当树中的节点被赋予一个表示某种意义的数值,我们称之为该节点的权。从树的根节点到任意节点的路径长度(经过的边数)与该节点上权值的乘积称为该节点的带权路径长度。树中所有叶节点的带权路径长度之和称为该树的带权路径长度(WPL)。当带权路径长度最小的二叉树被称为哈夫曼树,也成为最优二叉树。
如下图所示,有三课二叉树,每个树都有四个叶子节点a,b,c,d,分别取带权7,5,2,4。他们的带权路径长度分别为
(a) WPL = 7x2+5x2+2x2+4x2=36
(b) WPL = 2X1+4X2+7X3+5X3 = 46
(c) WPL = 7x1+5x2+2x3+4x3 = 35
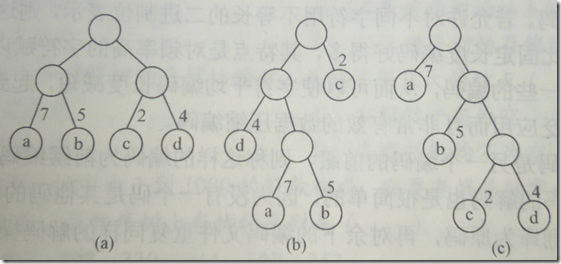
节点如果像c中的方式分布的话,WPL能取最小值(可证明),我们称为哈夫曼树。
哈夫曼树构造
哈夫曼树在构造时每次从备选节点中挑出两个权值最小的节点进行构造,每次构造完成后会生成新的节点,将构造的节点从备选节点中删除并将新产生的节点加入到备选节点中。新产生的节点权值为参与构造的两个节点权值之和。举例如下:
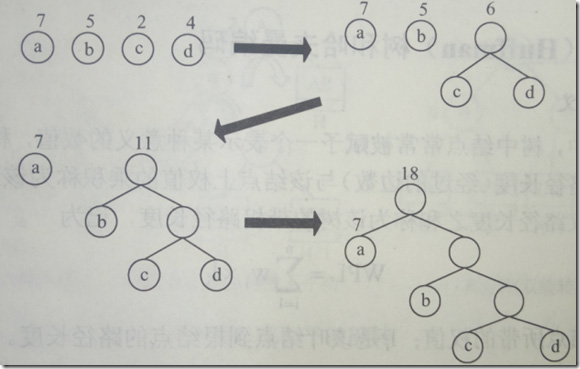
- 备选节点为a,b,c,d,权值分别为7,5,2,4
- 选出c和d进行构造(权值最小),生成新节点为e(权值为6),备选节点变为7,5,6
- 选出b和e进行构造,生成新节点f(权值为11),备选节点为7,11
- 将最后的7和11节点进行构造,最后生成如图所示的哈夫曼树
哈夫曼树应用
在处理字符串序列时,如果对每个字符串采用相同的二进制位来表示,则称这种编码方式为定长编码。若允许对不同的字符采用不等长的二进制位进行表示,那么这种方式称为可变长编码。可变长编码其特点是对使用频率高的字符采用短编码,而对使用频率低的字符则采用长编码的方式。这样我们就可以减少数据的存储空间,从而起到压缩数据的效果。而通过哈夫曼树形成的哈夫曼编码是一种的有效的数据压缩编码。
如果没有一个编码是另一个编码的前缀,则称这样的编码为前缀编码。如0,101和100是前缀编码。由前缀码形成的序列可以被唯一的组成一个字符串序列。如00101100可以被唯一的分析为0,0,101和100。
示例:
我们对一个字符串进行统计发现a-f出现的频率分别为a:45,b:13,c:12,d:16,e:9,f:5,我们对该字符串进行采用哈夫曼编码进行存储。
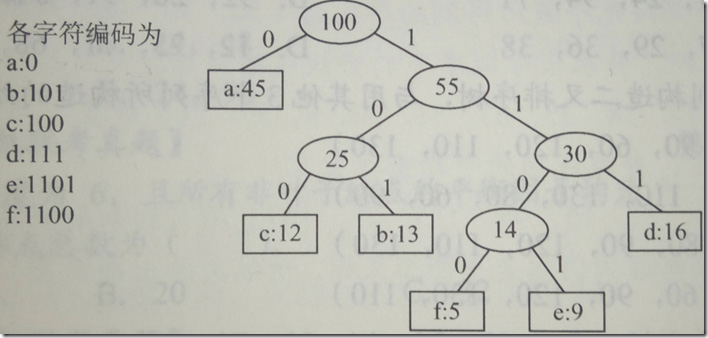
WPL = 1x45+3x(13+12+16)+4x(5+9)=224
这样算下来使用224二进制位就可以将该字符串存储起来,因为哈夫曼码是前缀码,所以可以唯一的还原出原来的字符序列。如果我们每个字符使用3位进行存储(至少3位),那么需要300bit才能将该字符串存储下。
其次了解下libjpeg使用哈夫曼编码是对图片上的每个像素(ARGB)进行编码,比如
ARGB(每个颜色通道取值范围0-255)的编码分别是:
A:001
R:010
G:011
B:100
如果采用定长,那一个图片下来一个人像素就是001010011100...
如果我们使用可变长编码方式,遍历、再嵌套遍历,再嵌套遍历每一个像素来获取前缀编码(没错,这个运算过程很大,而且临时变量内存也需要很大,但相对于今天的手机CPU来说,so easy),我们大致可以得到这样的编码:
A:01
R:10
G:11
B:100
那一个图片下来一个人像素就是011011100...
编码长度的优化后,接下来干的事就是计算权重以及每个颜色通道对应的编码的出现频次构建哈夫曼树了,这里就参考上面的图片了。
通过上面的介绍,可以知道最优哈夫曼编码其实是使用了可变长编码方式,而默认的哈夫曼编码使用了定长编码方式,因此需要更多的存储空间,呈现出来的手机图片自然会大很大。
libjpeg把optimize_coding参数默认设置为FALSE是因为10多年前的Android手机CPU跟内存都非常吃紧,所以当年没有设置为TRUE。如今的手机CPU跟内存都“起飞了”,Goolge的Skia图像处理引擎却还是使用optimize_coding的默认值FALSE。我们无法修改系统Skia的这个参数值,所以只能默默忍受size很大的图像文件。
经过大量图像压缩测试结果,得到两个结论:
1.图片压缩到相同的质量,FALSE所产出的图像文件大小是TRUE的5-10倍。
2.图片压缩到相同的质量,Android所产出的图像文件大小比iOS也是大5-10倍。
所以,通过使用libjpeg编译自己的native library修改optimize_coding参数的值,达图像质量相同,所产出的图像却能节省5-10倍空间大小的效果。
实现的步骤:
1.构建libjpeg的so库
到官方下载对应自己电脑系统类型的压缩包,创建Android项目导入压缩包里头的xx.h、xx.c文件构建so库。bither/bither-android-lib已经做了这个工作,因此我们只需直接拿他的libjpegbither.so即可。
2.导入libjpeg的声明头文件,因为步骤1的libjpegbither.so是对这些头文件的实现,因此需要导入这些头文件。
3.创建CMake脚本
cmake_minimum_required(VERSION 3.4.1)
add_library( effective-bitmap
SHARED
src/main/cpp/effective-bitmap.c )
include_directories( src/main/cpp/jpeg/
)
add_library(jpegbither SHARED IMPORTED)
set_target_properties(jpegbither
PROPERTIES IMPORTED_LOCATION
${CMAKE_SOURCE_DIR}/libs/${ANDROID_ABI}/libjpegbither.so)
find_library( log-lib
log )
find_library( jnigraphics-lib jnigraphics )
target_link_libraries( effective-bitmap
jpegbither
${log-lib}
${jnigraphics-lib})
4.配置gradle关联CMakeLists.txt构建脚本,以及指定产出的ABI的类型
android {
// ...
defaultConfig {
// ...
externalNativeBuild {
cmake {
cppFlags ""
}
}
ndk {
abiFilters 'armeabi'
}
}
externalNativeBuild {
cmake {
path "CMakeLists.txt"
}
}
}
5.编写C/C++代码
int generateJPEG(BYTE* data, int w, int h, int quality,
const char* outfilename, jboolean optimize) {
int nComponent = 3;
// jpeg的结构体,保存的比如宽、高、位深、图片格式等信息
struct jpeg_compress_struct jcs;
struct my_error_mgr jem;
jcs.err = jpeg_std_error(&jem.pub);
jem.pub.error_exit = my_error_exit;
if (setjmp(jem.setjmp_buffer)) {
return 0;
}
jpeg_create_compress(&jcs);
// 打开输出文件 wb:可写byte
FILE* f = fopen(outfilename, "wb");
if (f == NULL) {
return 0;
}
// 设置结构体的文件路径
jpeg_stdio_dest(&jcs, f);
jcs.image_width = w;
jcs.image_height = h;
// 设置哈夫曼编码
jcs.arith_code = false;
jcs.input_components = nComponent;
if (nComponent == 1)
jcs.in_color_space = JCS_GRAYSCALE;
else
jcs.in_color_space = JCS_RGB;
jpeg_set_defaults(&jcs);
jcs.optimize_coding = optimize;
jpeg_set_quality(&jcs, quality, true);
// 开始压缩,写入全部像素
jpeg_start_compress(&jcs, TRUE);
JSAMPROW row_pointer[1];
int row_stride;
row_stride = jcs.image_width * nComponent;
while (jcs.next_scanline < jcs.image_height) {
row_pointer[0] = &data[jcs.next_scanline * row_stride];
jpeg_write_scanlines(&jcs, row_pointer, 1);
}
jpeg_finish_compress(&jcs);
jpeg_destroy_compress(&jcs);
fclose(f);
return 1;
}
6.构建so库
源码:https://github.com/zengfw/EffectiveBitmap (本地下载)
参考链接:
Why the image quality of iPhone is much better than Android?
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对脚本之家的支持。
您可能感兴趣的文章:

- java本地方法调用(JNI)的参考代码----实现将String转换成char*,将char*转换成String.
- JAVA用JNI方法调用C代码实现HelloWorld(含windows及ubuntu两种操作系统环境下的操作)
- 模仿android_debug_JNITest实现apk 调用framework java JNI中方法
- Android平台Camera实时滤镜实现方法探讨(一)--JNI操作Bitmap
- java JNI 实现原理 (三) JNI中的RegisterNatives方法
- 实现JNI的另一种方法:使用RegisterNatives方法传递和使用Java自定义类 (转)
- android JNI实现方法(一)——CDT
- Android JNI处理图片实现黑白滤镜的方法
- JavaSE JNI 动态注册本地方法(c语言实现native层)
- 编写android程序调用jni本地方法的实现(详细例子)
- Android中关于JNI 的学习(六)JNI中注冊方法的实现
- Android(安卓)开发通过NDK调用JNI,使用opencv做本地c++代码开发配置方法实现边缘检测代码(2)
- 使用jni实现在C语言中调用Java的方法
- Android Studio中导入JNI生成的.so库的实现方法
- Java通过调用C/C++实现的DLL动态库――JNI的方法
- JAVA用JNI方法调用C代码实现HelloWorld
- cocosdx交叉编译到android使用jni实现java端调用C++方法
- Java本地方法理解及通过JNI的简单实现
- 实现硬件访问服务的JNI方法
- JNI中实现自定义onLoad()方法