壁纸爬取——协程应用
(协程)壁纸爬取
一、 算法解析
1.1 进入爬取壁纸的网站(表层网页)
彼岸桌面壁纸-二次元 (少爬涩图,健康生活!)
1.2 获取显示单张壁纸的页面(深层网页)地址
选择网页元素:Ctrl+Shift+C
你学废了吗?学废扣眼珠子,没学废点赞收藏
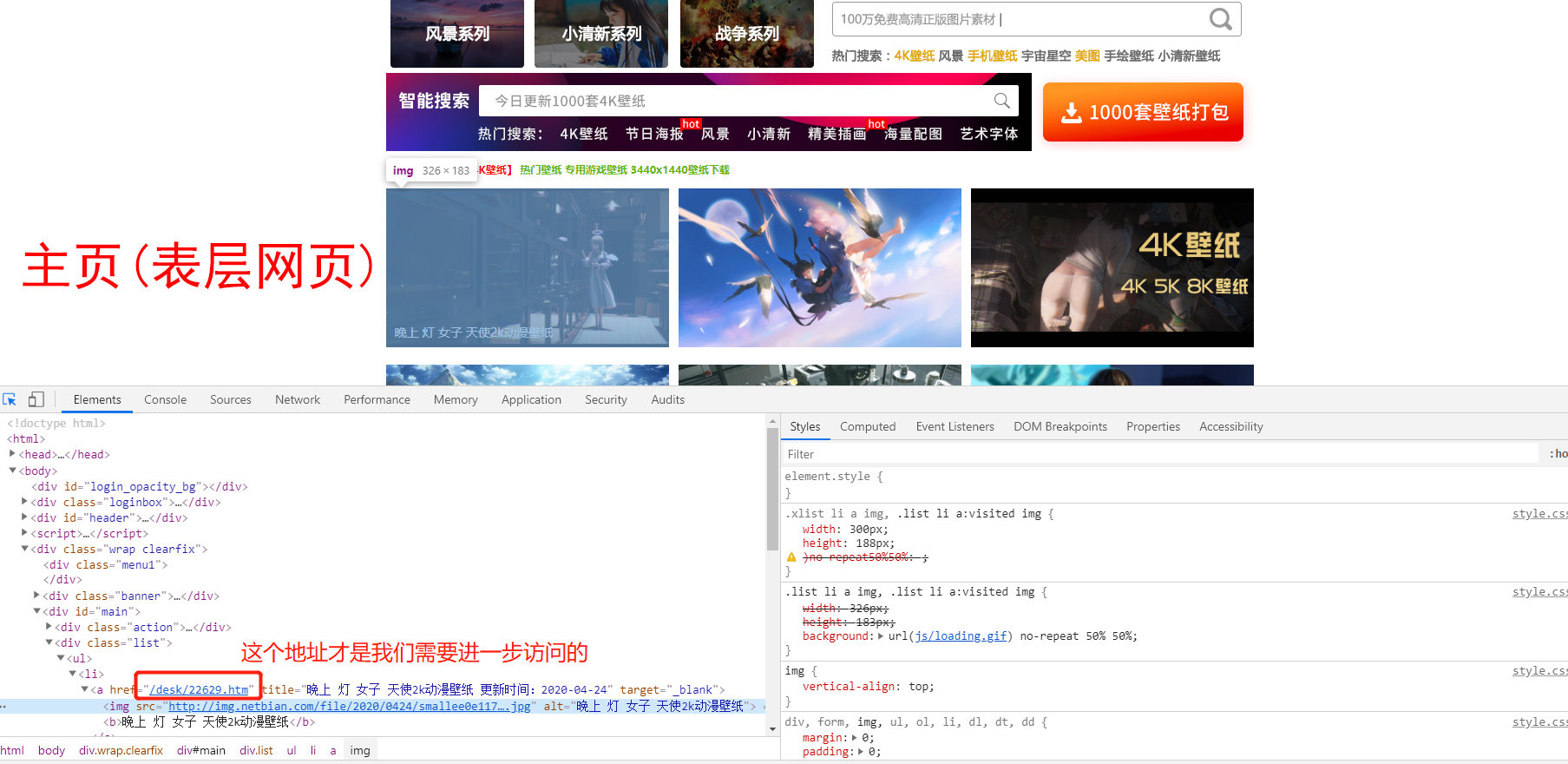
问:为什么不是下面那个 "img src=..." 的地址呢?
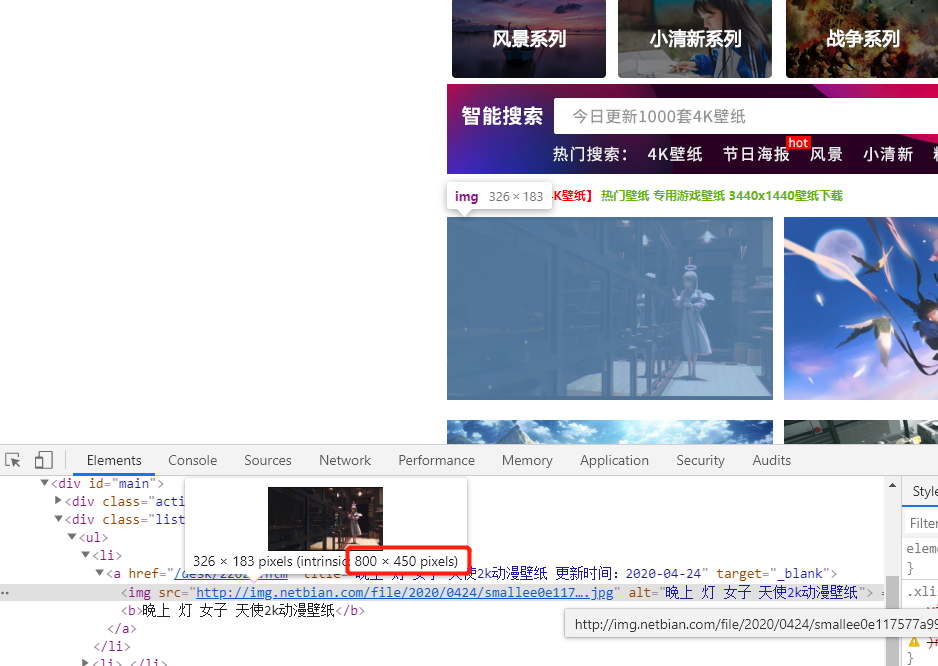
答:下面的地址的确是一个图片的地址,但是该图片是800*450(我们要1920*1080),是用来显示该页面这个小图的(如下图)
所以你喜欢 大 还是喜欢 小?你品你细品
1.3 进入单张壁纸的页面
① 你可以点击 "/desk/22629.htm"
② 在浏览器网址输入栏输入 "http://www.netbian.com/desk/22629.htm"
(② 这个是重点,因为爬取时我们需要这个完整地址才能访问下面这个页面)
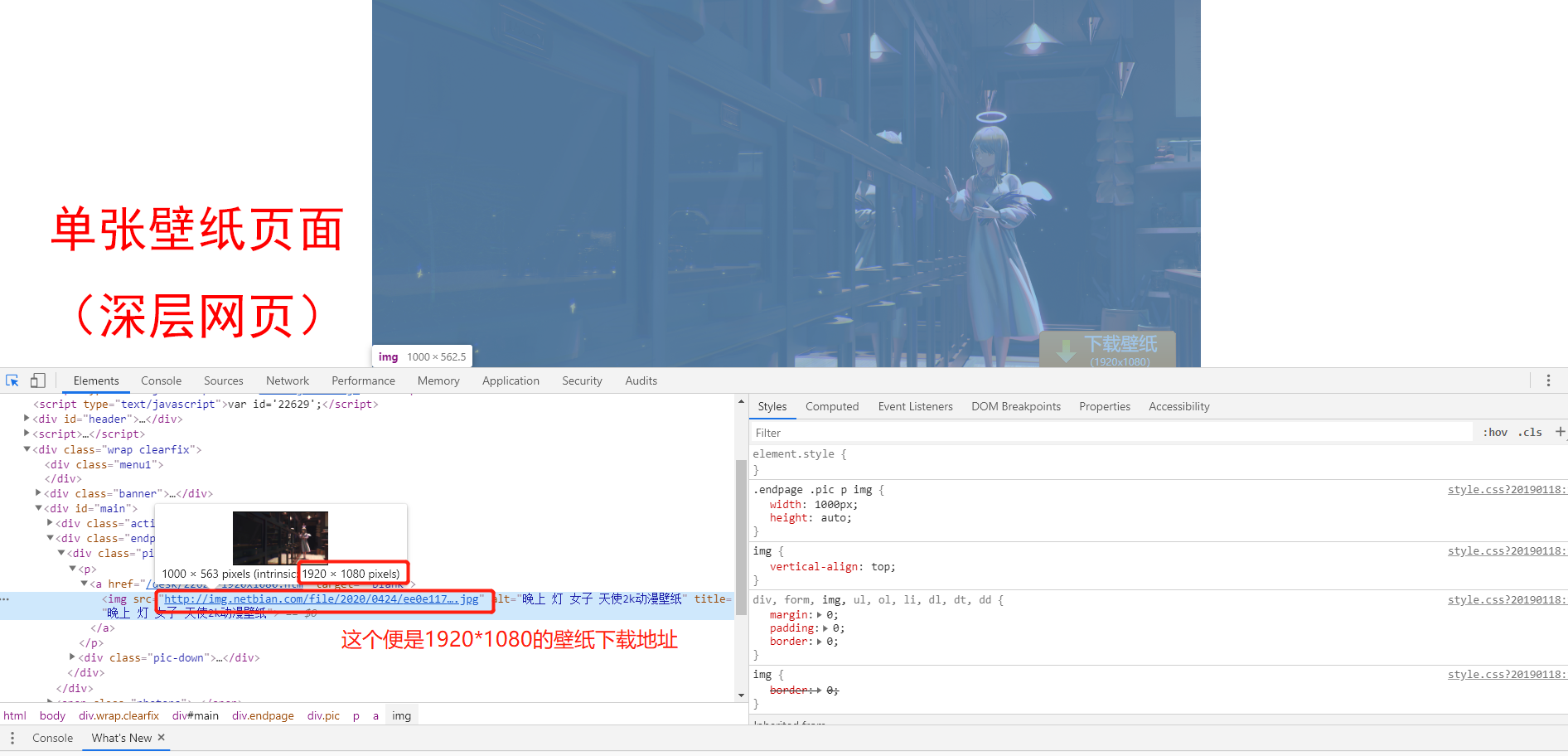
此时的 "img src=..." 就是我们 大 壁纸的最终下载地址
1.4 思路总结
-
① 访问主页(表层网页)
-
② 将主页的源代码全部读取出来
查看源代码:
① 右键→查看网页源代码
② Ctrl+U
-
② 通过正则匹配将读取的网页源代码中 所有 单张壁纸页面的(深层网页)地址 "/desk/*.htm" 筛选出来,作为字符串对象
-
③ http://www.netbian.com + "/desk/*.htm" 将两个字符串合并为完整的 url
-
④ 通过上面完整的网址访问每张壁纸的深层网页,并将深层网页的源代码读取出来
-
⑤ 通过正则匹配将 1920*1080壁纸 的下载地址,筛选出来
-
⑥ 访问该壁纸的下载地址,以二进制的形式将数据读取,并以 "*.jpg(.png)" 格式进行写入为本地文件
1.5 思路代码重现
① 以下部分都有标明 重点 与 非重点
重点:核心算法的展现(如何访问网页并通过正则匹配提取所需的url)
非重点:下载功能,显示下载进度,自动为文件名命名
※ 读者看懂重点的核心算法就好了,其余的功能有兴趣自己琢磨
② 建议从主函数开始食用,不然绝对懵逼
③ 你也可以下载这个小项目自己去Van~Van~
该项目下载地址:
链接:https://pan.baidu.com/s/1SVIMVzmPIEJ7kEsvMpK23Q
提取码:fkgz
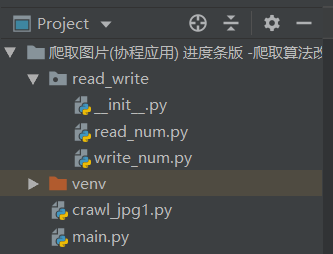
1.5.1 工程目录结构
1.5.2 导入模块以及定义全局变量
# 最好把 gevent 相关的模块放最前面,以免出现BUG import gevent from gevent import monkey monkey.patch_all() import requests import re from read_write.read_num import read from read_write.write_num import write # 爬取到的图片下载地址存放列表 url_deep_list = [] # 以下四个变量并非重点,我们关注核心算法 # 图片文件的名字 name_jpg = 0 # 允许开始下载的标志 flag_download = 0 gl_url_ok_num = 0 url_num = 0
1.5.3 访问主页(表层网页)提取 深层网页 地址——重点
def get_surface_url(surface_page): """表层网页提取出深层网页地址 :param surface_page: 表层网页 :return: 返回一个 深层网页 地址列表 """ # 通过目标网站,相当于获取了一个 response 这个可操作对象 response = requests.get(surface_page) # TODO .+? 非贪婪匹配 当遇到 .时前面的非贪婪匹配任务结束,接着匹配htm url_add = r'/desk/.+?\.htm' # response.text 即代表该对象的文本数据,源代码数据 # 从源代码数据中匹配 url_add 相关的内容,从而生成一个列表 url_list_old = re.findall(url_add, response.text) # print(url_list_old) url_list_new = [] for str_old in url_list_old: str_new = 'http://www.netbian.com' + str_old url_list_new.append(str_new) # print(url_list_new) return url_list_new
1.5.4 访问深层网页地址,提取下载地址——重点
def get_deep_url(deep_page): """通过深层网页获取 1920*1080 的壁纸地址 :param deep_page: 深层网页地址 :return: 返回一个 壁纸 下载地址 """ response = requests.get(deep_page) # 此页面已经能找到 1920*1080 jpg图片的下载地址了,我们通过正则匹配,分组“()”进行提取 # ① 首先锁定目标地址的头 /desk/.+?-1920x1080.htm # ② 接着再往下匹配的地址,即为最终下载地址 # 总结:之所以可以分两部分进行锁定匹配,是因为 # ① search 是可以通过跨行匹配(不过一旦匹配成功一个,即返回对象) # ② .*? 到 <img src... 之间正好没有 \n 换行符,所以能往后一直匹配(因为 . 是匹配除了\n外的所有任意一个字符) url_add = r'/desk/.+?-1920x1080.htm.*?<img src="(http://img.netbian.com/file/.+?.jpg)"' deep_url = re.search(url_add, response.text) # 返回的对象需要,通过 group() 进行提取 # print(deep_url.group(1)) return deep_url.group(1)
1.5.5 下载图片——非重点
def download_jpg(local_path):
"""通过获取的地址列表下载壁纸
:param local_path: 下载到的本地位置
"""
global name_jpg
global gl_url_ok_num
# for url in url_list:
while True:
# print("开始下载图片...")
# url = q_url.get()
if flag_download == 1:
if url_deep_list:
url = url_deep_list[0]
url_deep_list.pop(0)
# name_jpg += 1
response = requests.get(url)
# 请求成功以后,正式开始下载时,才给它 +1 起名字,因为 +1 操作不需要等待,
# 所以不会切换协程,直接通过 open 已经为文件起好名字了,即使下载等待,
# 也不会影响已经有名字的文件了
# 如果 name_jpg += 1 放上面会出现当 协程遇到 requests 时网络请求,在等待时间,会让第二个协程来执行,
# 这样 name_jpg += 1,这样等待第一个协程开始下载时,名字就会变为 3,
# 而且极有可能出现各种BUG,经过试验:名字会从3开始,而且最终少了两个文件
name_jpg += 1
with open('%s/%d.jpg' % (local_path, name_jpg), 'wb') as ft:
ft.write(response.content)
# print("成功下载一张壁纸...")
gl_url_ok_num += 1
if not url_deep_list:
# print("全部下载完毕...")
break
else:
break
# print(url)
else:
print("还没有爬取到地址...无法开始下载")
gevent.sleep(2.5)
continue
# write("%s/num.txt" % local_path, str(name_jpg))
1.5.6 控制爬取的页面(从第几页开始,爬取若干页)——非重点
① 第一页

② 第二页
③ 第三页(这回懂了吧,改变 url 的部分参数便可以访问不同页面)
def crawl_url(page_num, page_start):
"""爬取出一个个下载地址,并加入列表 url_deep_list 当中
:param page_num: 需要爬取的网页数
:param page_start: 从第几个页面开始爬取
"""
global flag_download
global url_num
print("开始爬取地址...")
j = 0
flag = 0
while j < page_num:
if flag == 0:
if page_start == 1:
url_list_surface = get_surface_url('http://www.netbian.com/erciyuan/index.htm')
else:
url_list_surface = get_surface_url('http://www.netbian.com/erciyuan/index_%d.htm' % (page_start + j))
flag = 1
else:
url_list_surface = get_surface_url('http://www.netbian.com/erciyuan/index_%d.htm' % (page_start + j))
for url_surface in url_list_surface:
url_deep = get_deep_url(url_surface)
# TO
ad8
DO url_deep 是单个图片的最终的下载地址,把它存入队列
# print(url_deep)
url_deep_list.append(url_deep)
print()
j += 1
# 等所有网页爬取完毕,才开始下载,是为了能让下载进度能读取到总下载图片数量
url_num = len(url_deep_list)
flag_download = 1
print("爬取地址完毕...")
# return url_list_deep
1.5.7 显示下载进度(附加功能)——非重点
def download_rate():
global url_num
global gl_url_ok_num
while True:
if flag_download == 1:
url_ok_num = gl_url_ok_num
print("\r下载进度: %.2f%%---[%d/%d]..." %
(url_ok_num * 100 / url_num, url_ok_num, url_num), end="")
gevent.sleep(0.5)
if url_ok_num == url_num:
print("\n全部下载完毕...")
break
else:
print("还未爬取完地址...无法显示下载进度")
gevent.sleep(3)
continue
1.5.8 主函数(看不懂就从主函数看起)
def craw_jpg():
"""
主函数
"""
global name_jpg
page_start = int(input("你希望从第几页开始爬取:"))
page_num = int(input("请输入你要爬取的页数:"))
local_path = str(input("请输入你要保存的地址:"))
num_txt_path = local_path + "/num.txt"
# TODO 不能通过 windows 来创建 num.txt 因为这样创建的 utf-8 文本不纯净,是BOM编码格式的,
# 前面会有几个字符,导致 int() 转换出现问题。所以应该让 python 来自行创建
try: # 先尝试打开 num.txt ,无需赋值,只是为了了解是否存在 num.txt 这个文件,下面还是会进行读取的赋值的
read(num_txt_path)
# 如果 发现异常——没有num.txt这个文件,则会 write 自动创建文件并写入数据
except FileNotFoundError:
print("没有发现命名文件[num.txt] ...")
name_jpg = input("请输入你要为文件命名的开头:")
write(num_txt_path, str(name_jpg))
else:
print(" num.txt 文件已存在...")
print()
finally:
name_jpg = int(read(num_txt_path)) - 1
# C:/Users/Administrator/Desktop/爬取图片
# name_jpg = int(read(num_txt_path))
print(name_jpg)
# TODO 生成5个协程 1个爬取网址和3个下载,1
15a8
个显示下载进度
gevent.joinall([
gevent.spawn(crawl_url, page_num, page_start),
gevent.spawn(download_jpg, local_path),
gevent.spawn(download_jpg, local_path),
gevent.spawn(download_jpg, local_path),
gevent.spawn(download_rate,),
])
# 是为了使下一次下载的名字是正常顺序(非重点)
write("%s/num.txt" % local_path, str(name_jpg + 1))
if __name__ == "__main__":
# 爬取网址: http://www.netbian.com/erciyuan/index.htm
# 下载到本地地址: C:/Users/Administrator/Desktop/爬取图片
craw_jpg()
1.5.9 这是txt文件写入与读取部分(用于为图片名称自动命名)——非重点
1.5.9.1 txt 读取
def read(file):
# 打开文件
num_file = open(file, "r", encoding="Utf-8")
# 现将指针放回开头
num_file.seek(0, 0)
num_read = num_file.readline()
# 关闭文件
num_file.close()
return num_read
if __name__ == "__main__":
num = read("num.txt")
print(num)
print()
print("正在测试 read_num 模块...")
1.5.9.2 txt 写入
def write(file, i):
# 打开文件
num_file = open(file, "w", encoding="Utf-8")
# 现将指针放回开头
num_file.seek(0, 0)
num_file.write(i)
# 关闭文件
num_file.close()
if __name__ == "__main__":
write("num.txt", str(2))
print("正在测试 read_num 模块...")
程序运行结果:
你希望从第几页开始爬取:1 请输入你要爬取的页数:2 请输入你要保存的地址:C:/Users/Administrator/Desktop/爬取图片 没有发现命名文件[num.txt] ... 请输入你要为文件命名的开头:1 0 开始爬取地址... 还没有爬取到地址...无法开始下载 还没有爬取到地址...无法开始下载 还没有爬取到地址...无法开始下载 还未爬取完地址...无法显示下载进度 爬取地址完毕... 下载进度: 100.00%---[34/34]... 全部下载完毕...
二、总结
一、算法思想
- 每个表层网页有若干张图片,是我们最终需要下载的图片(1920*1080)的缩小版用于展示的小图片。
- 但我们可以通过爬取该页面的这些图片的链接 即 url_suface,通过 get_deep_url( ) 进入深层页面,深层页面中间有个大图
- 再通过爬取该页面的最终下载网址得到一个个的 url_deep,最终将这些网址放入 url_deep_list 列表中
- 最后通过 url_deep_list 一个个取出下载
二、注意事项
-
先将所有地址爬取完毕再进行下载,方便统计需下载的总图片数量,用于显示下载进度的图片总数
-
使用协程进行下载,要注意合理分配时间给用于 下载的协程 和用于 显示下载进度的协程
因为协程的时间分配是很智能的,由于下载图片是需要请求且等待的过程,协程会自动将这些多余的时间分配给其他协程,这样显示下载进度的协程总是能分配到很多时间,导致用于下载协程出现阻塞,从而导致下载速度极慢!
-
所以我们要让 显示下载进度的协程 每隔0.5s显示一次(gevent.sleep(0.5)),那么这0.5s就可以分配给 用于下载的协程了
最后再附上下载地址:
链接:https://pan.baidu.com/s/1SVIMVzmPIEJ7kEsvMpK23Q
提取码:fkgz
算是简单的项目了(算法很容易),只是附加的功能看起来可能有点复杂,其实也有一大部分代码都是为了防止bug
有不足之处,恳请大佬指出orz!
或有看不懂的朋友也可以评论,我会尽快恢复的啦~ღ( ´・ᴗ・` )比心

- python 协程中的迭代器,生成器原理及应用实例详解
- Android应用开发——显示动态壁纸(GIF)
- python协程及应用(一):简介
- Win10 Mobile自动更换开始屏幕壁纸应用Dynamic Wallpaper下载
- python协程及应用(一):简介
- 协程VS多线程 应用场景比对
- yield学习续:yield return迭代块在Unity3D中的应用——协程
- 不只有时间 诺基亚推WP8待机壁纸应用
- 协程在Web服务器中的应用(配的图还不错)
- 说说Android桌面(Launcher应用)背后的故事(五)——桌面壁纸的添加
- 深入理解Python中协程的应用机制: 使用纯Python来实现一个操作系统吧!!
- WindowsPhone应用推荐--想要彰显自我个性?想定期更换锁屏壁纸?试试“焕屏”
- python中多线程,多进程,多协程概念及编程上的应用
- [Sw] Swoole-4.2.9 可以尝试愉快应用 Swoole 协程了
- Python中多进程、多线程、协程区别和应用场景
- 项目源码--Android高清壁纸应用
- 深入理解Python中协程的应用机制: 使用纯Python来实现一个操作系统吧!!
- 深入理解Python中协程的应用机制: 使用纯Python来实现一个操作系统吧!!
- 协程与Swoole框架的相关应用
- 协程的简单应用(aiohttp,asyncio)---爬虫