快速入门Kafka系列(1)——消息队列,Kafka基本介绍
自Redis快速入门系列结束后,博主决定后面几篇博客为大家带来关于Kafka的知识分享~作为快速入门Kafka系列的第一篇博客,本篇为大家带来的是消息队列和Kafka的基本介绍~
码字不易,先赞后看!

文章目录
快速入门Kafka
1、消息队列的介绍
消息(Message):是指在应用之间传送的数据,消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。
消息队列(Message Queue):是一种应用间的通信方式,消息发送后可以立即返回,有消息系统来确保信息的可靠专递,消息发布者只管把消息发布到MQ中而不管谁来取,消息使用者只管从MQ中取消息而不管谁发布的,这样发布者和使用者都不用知道对方的存在。
2、Kafka消息队列
Apache Kafka是一个分布式消息发布订阅系统。它最初由LinkedIn公司基于独特的设计实现为一个分布式的提交日志系统( a distributed commit log),,之后成为Apache项目的一部分。Kafka系统快速、可扩展并且可持久化。它的分区特性,可复制和可容错都是其不错的特性。
3、消息队列的应用场景
消息队列在实际应用中包括如下四个场景:
应用耦合:多应用间通过消息队列对同一消息进行处理,避免调用接口失败导致整个过程失败;
异步处理:多应用对消息队列中同一消息进行处理,应用间并发处理消息,相比串行处理,减少处理时间;
限流削峰:广泛应用于秒杀或抢购活动中,避免流量过大导致应用系统挂掉的情况;
消息驱动的系统:系统分为消息队列、消息生产者、消息消费者,生产者负责产生消息,消费者(可能有多个)负责对消息进行处理;
下面详细介绍上述四个场景以及消息队列如何在上述四个场景中使用:
4、消息队列的两种模式
消息队列包括两种模式,点对点模式(point to point, queue)和发布/订阅模式(publish/subscribe,topic)。
4.1 点对点模式
点对点模式下包括三个角色:
消息队列
发送者(生产者)
接收者(消费者)
关系大致如下:

消息发送者生产消息发送到queue中,然后消息接收者从queue中取出并且消费消息。消息被消费以后,queue中不再有存储,所以消息接收者不可能消费到已经被消费的消息。
点对点模式特点:
- 每个消息只有一个接收者(Consumer)(即一旦被消费,消息就不再在消息队列中);
- 发送者和接收者间没有依赖性,发送者发送消息之后,不管有没有接收者在运行,都不会影响到发送者下次发送消息;
- 接收者在成功接收消息之后需向队列应答成功,以便消息队列删除当前接收的消息;
4.1 发布/订阅模式
发布/订阅模式下包括三个角色
角色主题(Topic)
发布者(Publisher)
订阅者(Subscriber)
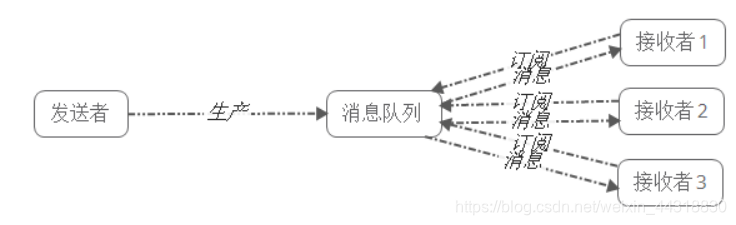
发布者将消息发送到Topic,系统将这些消息传递给多个订阅者。
发布/订阅模式特点:
- 每个消息可以有多个订阅者;
- 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。
- 为了消费消息,订阅者需要提前订阅该角色主题,并保持在线运行;
5、Kafka的基本介绍
5.1 Kafka的基本介绍
kafka是最初由linkedin公司开发的,使用scala语言编写,kafka是一个分布式,分区的,多副本的,多订阅者的日志系统(分布式MQ系统),可以用于搜索日志,监控日志,访问日志等
Kafka is a distributed,partitioned,replicated commit logservice。
kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
5.2 Kafka的好处
可靠性:分布式的,分区,复制和容错。
可扩展性:kafka消息传递系统轻松缩放,无需停机。
耐用性:kafka使用分布式提交日志,这意味着消息会尽可能快速的保存在磁盘上,因此它是持久的。
性能:kafka对于发布和订阅消息都具有高吞吐量。即使存储了许多TB的消息,他也能体现出稳定的性能。
kafka非常快:保证零停机和零数据丢失
5.3 分布式的发布与订阅系统
apache kafka是一个分布式发布-订阅消息系统和一个强大的队列,可以处理大量的数据,并使能够将消息从一个端点传递到另一个端点,kafka适合离线和在线消息消费。kafka消息保留在磁盘上,并在集群内复制以防止数据丢失。kafka构建在zookeeper同步服务之上。它与apache和spark非常好的集成,应用于实时流式数据分析。
5.4 kafka的主要应用场景
指标分析
Kafka 通常用于操作监控数据。这设计聚合来自分布式应用程序的统计信息, 以产生操作的数据集中反馈。
日志聚合解决方案
kafka可用于跨组织从多个服务器收集日志,并使他们以标准的合适提供给多个服务器。
流式处理
流式处理框架(spark,storm,flink)从主题中读取数据,对其进行处理,并将处理后的数据写入新的主题,供 用户和应用程序使用,kafka的强耐久性在流处理的上下文中也非常的有用。
本篇博客知识分享就到这里,受益或对大数据技术感兴趣的朋友可以点赞关注博主,下一篇博客将为大家介绍
Kafka集群的搭建,敬请期待|ू・ω・` )

 原创文章 276获赞 2834访问量 55万+
关注
私信
原创文章 276获赞 2834访问量 55万+
关注
私信

- 分布式消息队列kafka系列介绍 — 基本概念
- 分布式消息队列kafka系列介绍 — 核心API介绍及实例
- 分布式消息队列kafka系列介绍 — 核心API介绍及实例
- 快速入门Kafka系列(7)——kafka的log存储机制和kafka消息不丢失机制
- 分布式消息队列kafka系列介绍 — 核心API介绍及实例
- 分布式消息队列kafka系列介绍 — 配置文件详解
- kafka分布式消息队列 — 基本概念介绍
- 分布式消息队列kafka系列介绍 — 配置文件详解
- kafka分布式消息队列 — 基本概念介绍
- 分布式消息队列kafka系列介绍 — 核心API介绍及实例
- 分布式消息队列kafka系列介绍 — 配置文件详解
- Kafka 分布式消息队列介绍
- 消息队列系列(一):.Net平台下的消息队列介绍
- linux shell编程五步拳(张迅雷闪击shell系列) 第二集 shell编程基本语法快速入门
- 消息队列 Kafka 的基本知识及 .NET Core 客户端
- 快速入门系列--WCF--02消息、会话与服务寄宿
- java多线程系列-----1.多线程快速入门,线程安全,多线程之间通讯,并发包,并发队列,线程池原理,锁的深度化
- 快速入门系列--WCF--06并发限流、可靠会话和队列服务
- 消息队列-Kafka介绍
- 消息队列 Kafka 的基本知识及 .NET Core 客户端