算法与数据结构番外(1):优先队列
2020-05-04 15:20
671 查看
这是算法与数据结构番外系列的第一篇,这个系列未来的主要内容是补充一些与算法与数据结构相关的知识,这些知识比较零碎,同时也与[正传](https://albertcode.info/?tag=algorithm)关系密切,往往需要阅读了正传的相关内容以后,才能较好的理解这部分内容。如果对番外系列不感兴趣的话,是可以跳过此系列内容的,不会影响理解其他文章的内容。
**阅读本文前,需要首先了解[队列](https://albertcode.info/?p=102)和[堆](https://albertcode.info/?p=129)的相关知识。**
此文优先队列的代码可以在我的 [github](https://github.com/AlbertShenC/Algorithm/tree/master/PriorityQueue) 上查看。
### 优先队列
优先队列是一种**特殊的队列**。队列具有**先进先出**的特性,对于普通队列而言,首先出队的元素是首先入队的元素,而优先队列中,**首先出队**的元素是目前队列中**优先级最高的元素**。
优先队列分为两类,最大优先队列和最小优先队列。一个最大优先队列的严格定义如下:
> 最大优先队列是一种用来维护由一组元素构成的集合 S 的数据结构,其中的每一个元素都有一个相关的值,称为关键字(key,也就是我们上文所说的优先级),一个最大优先队列应该支持以下操作:
>
> INSERT(S, x):把元素 x 插入集合 S 中。
>
> MAXIMUM(S):返回 S 中具有最大关键字的元素。
>
> EXTRACT-MAX(S):去掉并返回 S 中的具有最大关键字的元素。
**最大优先队列**最为著名的应用场景,是共享计算机系统的作业调度。最大优先队列将会记录将要执行的各个作业以及它们之间的相对优先级。当一个作业完成或者被中断后,调度器调用 EXTRACT-MAX 从所有的等待作业中,选出具有最高优先级的作业来执行,在任何时候,调度器都可以调用 INSERT 把一个新作业加入到队列中来。
相应的,**最小优先队列**则是选择集合中具有最小关键字的元素。最小优先队列经常被用于模拟。队列中保存要模拟的事件,每个事件都有一个发生时间作为其关键字,事件将会按照时间先后顺序依次发生。模拟程序调用 EXTRACT-MIN (即与 EXTRACT-MAX 正好相反的功能:去掉并返回 S 中的具有最小关键字的元素)选择下一个要模拟的事件,当一个新事件产生时,模拟器通过调用 INSERT 将其插入最小优先队列。
**优先队列可以使用堆来实现**,最大优先队列对应最大堆,最小优先队列对应最小堆。下面我们将以最大优先队列为例进行介绍。
### 优先队列的实现
#### 优先队列的定义
优先队列的定义与队列几乎完全一样:
```c
// 优先队列定义
typedef struct PriorityQueue{
int* array;
int max_size;
}PriorityQueue;
```
#### 辅助函数
这些辅助函数我们在[堆排序](https://albertcode.info/?p=129)的那一章中已经写好,这里可以直接使用。
获取堆中节点的父节点,左孩子和右孩子节点**下标**:
```c
#define PARENT(i) (i / 2)
#define LEFT(i) (2 * i)
#define RIGHT(i) (2 * i + 1)
```
交换数组两个元素的值:
```c
// 交换数组 下标i 和 下标j 对应的值
int swap(int *array, int i, int j){
int temp;
temp = array[i];
array[i] = array[j];
array[j] = temp;
return 0;
}
```
递归维护最大堆:
```c
// 递归维护最大堆
int MaintainMaxHeap(int *heap, int i){
int largest;
int left = LEFT(i);
int right = RIGHT(i);
if(left <= heap[0] && heap[left] > heap[i]){
largest = left;
} else{
largest = i;
}
if(right <= heap[0] && heap[right] > heap[largest]){
largest = right;
}
if(largest != i){
swap(heap, largest, i);
MaintainMaxHeap(heap, largest);
}
return 0;
}
```
这些辅助函数是直接采用的堆排序所用代码,由于篇幅有限,故不再重复解释,可以[点此](https://albertcode.info/?p=129#header-id-3)查看相关解释。
#### 初始化函数
```c
// 初始化优先队列
PriorityQueue* PriorityQueueInit(int max_size){
PriorityQueue* priority_queue = (PriorityQueue*)malloc(sizeof(PriorityQueue));
priority_queue->array = (int*)malloc(sizeof(int) * (max_size + 1));
priority_queue->array[0] = 0;
priority_queue->max_size = max_size;
return priority_queue;
}
```
我们在这里,依然使用堆排序中的数组解释方法:array[0] 用于储存堆中的**有效数据**个数,故数组的实际长度为 max_size + 1,堆顶元素是 array[1]。
#### 入队函数
```c
// 优先队列入队
int PriorityQueueEnqueue(PriorityQueue *priority_queue, int number_to_enqueue){
int i;
priority_queue->array[0] += 1;
i = priority_queue->array[0];
priority_queue->array[priority_queue->array[0]] = number_to_enqueue;
while(i > 1 && priority_queue->array[PARENT(i)] < priority_queue->array[i]){
swap(priority_queue->array, PARENT(i), i);
}
return 0;
}
```
整个**最大优先队列**本质上是一个**最大堆**,当我们插入一个数据时,首先将其插入至堆的尾部,此时可能会违背最大堆的性质,故我们将此元素不断**与其父节点的值进行比较**,若其小于父节点的值,说明此时整个堆已经是一个最大堆了;若其大于父节点的值,则将此节点与父节点交换,重复此步骤,直到此元素小于其父节点的值或此元素成为了堆顶节点。
显然,入队操作的时间复杂度是 $O(lgn)$ ,因为整个函数中影响其时间复杂度的过程为 while 循环,其最差情况是将此元素从叶节点一步一步交换至根节点,而树的高度为 $O(lgn)$ 。
整个过程如下图所示:

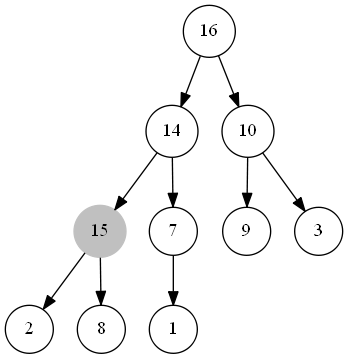
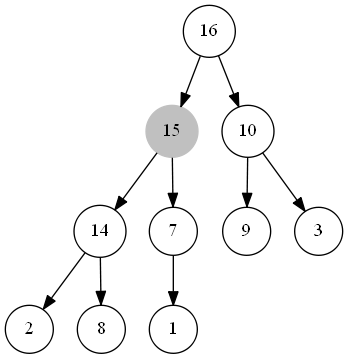
#### 出队函数
```c
// 优先队列队首元素
int PriorityQueueHead(PriorityQueue *priority_queue){
return priority_queue->array[1];
}
// 优先队列出队
int PriorityQueueDequeue(PriorityQueue *priority_queue){
int return_number = priority_queue->array[1];
priority_queue->array[1] = priority_queue->array[priority_queue->array[0]];
priority_queue->array[0] -= 1;
MaintainMaxHeap(priority_queue->array, 1);
return return_number;
}
```
在理解了堆排序以后,优先队列的出队操作很简单了。
一个最大优先队列出队时返回的值为**队列中的最大值**,即 array[1],那么我们只需要像堆排序时那样,将堆中最后一个有效数据复制到堆顶(array[1]),此时新的堆顶可能会违反最大堆的性质,为此我们只需对堆顶元素调用一次 MaintainMaxHeap() ,即可保证出队后,此堆依然是一个最大堆。
关于此过程的时间复杂度和正确性分析,我们已经在[堆排序](https://albertcode.info/?p=129)一章中介绍过了,在此就不赘述了,直接给出结果 $O(lgn)$ 。
### 总结
在理解了堆排序以后,优先队列就非常简单了,几乎连代码都不需要太多修改。从上文的分析,我们也能得出一个结论,优先队列最为关键的两个步骤(入队、出队)的时间复杂度均为 $O(lgn)$ 。
原文链接:[albertcode.info](https://albertcode.info/?p=134)
个人博客:[albertcode.info](https://albertcode.info)

相关文章推荐
- 【数据结构和算法】_04_优先队列 & 双向队列
- 数据结构 基于队列的广度优先遍历算法判断完全二叉树
- 【数据结构】浅谈算法和数据结构:优先队列和堆排序
- 数据结构和算法——队列的实现
- 数据结构和算法分析(10)表栈和队列的实际应用(二)
- 【原创】STL部分常用数据结构用法汇总 -优先队列,set
- 算法与数据结构【数据结构】——三、线性表:栈与队列
- Python算法与数据结构(四)------ 栈与队列
- 数据结构Java实现07----队列:顺序队列&顺序循环队列、链式队列、顺序优先队列
- 数据结构与算法:python语言描述之队列
- hdu 1205 吃糖果(数学:推理||数据结构:优先队列)
- 数据结构和算法:队列和栈
- 数据结构和算法 – 3.堆栈和队列
- Dijkstra单源最短路径算法; 优先队列+静态数组邻接表; STL优先队列还是没想明白排序原则;
- 算法_优先队列
- 算法和数据结构---排序---优先级队列
- 用JS描述的数据结构及算法表示——栈和队列(基础版)
- python数据结构与算法——小猫钓鱼(使用队列)
- 拓扑排序 详解 + 并查集 详解 + 最小生成树(MST)详解 【普利姆算法 + 优先队列优化 & 克鲁斯卡尔算法】
- 【坐在马桶上看算法】算法12:堆——神奇的优先队列(下) 推荐