词向量word2vec之CBOW算法
词向量模型之CBOW模型的原理与实现
关于词向量模型word2rec,平台里只有skip-gram一个模型的代码实现,本项目将对word2rec算法的第二个模型——CBOW模型进行补充
此项目用于交流与学习,如有问题,请大家积极指出,作者将第一时间在后续的版本中进行改正与优化,感谢大家支持!
欢迎大家来逛我的主页
来AI Studio互粉吧~等你哦~ https://aistudio.baidu.com/aistudio/personalcenter/thirdview/218138
CBOW的原理
2013年,Mikolov提出了经典的word2vec算法,该算法通过上下文来学习语义信息。word2vec包含两个经典模型,CBOW(Continuous Bag-of-Words)和Skip-gram.
我们重点介绍一下CBOW模型的原理:
举个例子:Two boys are playing basketball.
在这个句子中我们定'are'为中心词,则Two,boys,playing,basketball为上下文。CBOW模型的原理就是利用上下文来预测中心词,即利用Two,boys,playing,basketball预测中心词:are。这样一来,are的语义就会分别传入上下文的信息中。不难想到,经过大量样本训练,一些量词,比如one,two就会自动找到它们的同义词,因为它们都具有are等中心词的语义。
CBOW的算法实现
对比Skip-gram,CBOW和Skip-gram的算法实现如 图1 所示。本项目将补充CBOW的算法实现过程
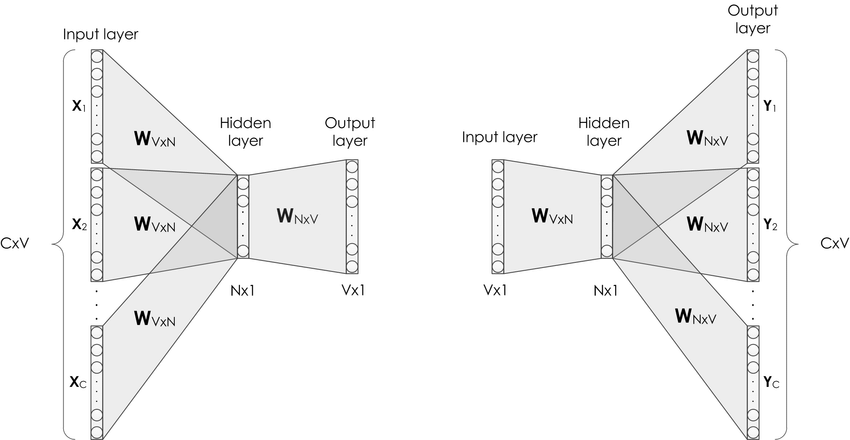
图1:CBOW和Skip-gram的算法实现
如 图1 所示,CBOW是一个具有3层结构的神经网络,分别是:
- Input Layer(输入层):接收one-hot张量 V∈R1×vocab_sizeV \in R^{1 \times \text{vocab\_size}}V∈R1×vocab_size 作为网络的输入,里面存储着当前句子中上下文单词的one-hot表示。
- Hidden Layer(隐藏层):将张量VVV乘以一个word embedding张量W1∈Rvocab_size×embed_sizeW^1 \in R^{\text{vocab\_size} \times \text{embed\_size}}W1∈Rvocab_size×embed_size,并把结果作为隐藏层的输出,得到一个形状为R1×embed_sizeR^{1 \times \text{embed\_size}}R1×embed_size的张量,里面存储着当前句子上下文的词向量。
- Output Layer(输出层):将隐藏层的结果乘以另一个word embedding张量W2∈Rembed_size×vocab_sizeW^2 \in R^{\text{embed\_size} \times \text{vocab\_size}}W2∈Rembed_size×vocab_size,得到一个形状为R1×vocab_sizeR^{1 \times \text{vocab\_size}}R1×vocab_size的张量。这个张量经过softmax变换后,就得到了使用当前上下文对中心的预测结果。根据这个softmax的结果,我们就可以去训练词向量模型。
在实际操作中,使用一个滑动窗口(一般情况下,长度是奇数),从左到右开始扫描当前句子。每个扫描出来的片段被当成一个小句子,每个小句子中间的词被认为是中心词,其余的词被认为是这个中心词的上下文。
CBOW算法和skip-gram算法最本质的区别就是:CBOW算法是以上下文预测中心词,而skip-gram算法是以中心城预测上下文。
CBOW的理想实现
使用神经网络实现CBOW中,模型接收的输入应该有2个不同的tensor:
-
代表当前上下文的tensor:假设我们称之为context_words VVV,一般来说,这个tensor是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中,每组上下文中每一个单词的ID。
-
代表目标词的tensor:假设我们称之为target_words TTT,一般来说,这个tensor是一个形状为[batch_size, 1]的整型tensor,这个tensor中的每个元素是一个[0, vocab_size-1]的值,代表目标词的ID。
在理想情况下,我们可以这样实现CBOW:把上下文中的每一个单词,依次作为输入,把当前句子中的中心词作为标签,构建神经网络进行学习,实现上下文预测中心词。具体过程如下:
- 声明一个形状为[vocab_size, embedding_size]的张量,作为需要学习的词向量,记为W0W_0W0。对于给定的输入VVV,即某一个上下文的单词,使用向量乘法,将VVV乘以W0W_0W0,这样就得到了一个形状为[batch_size, embedding_size]的张量,记为H=V∗W0H=V*W_0H=V∗W0。这个张量HHH就可以看成是经过词向量查表后的结果。
- 声明另外一个需要学习的参数W1W_1W1,这个参数的形状为[embedding_size, vocab_size]。将上一步得到的HHH去乘以W1W_1W1,得到一个新的tensor O=H∗W1O=H*W_1O=H∗W1,此时的OOO是一个形状为[batch_size, vocab_size]的tensor,表示当前这个mini-batch中的每一组上下文中的每一个单词预测出的目标词的概率。
- 使用softmax函数对mini-batch中每个中心词的预测结果做归一化,即可完成网络构建。
CBOW的实际实现
和课程中讲解的skip-gram一样,在实际中,为避免过于庞大的计算量,我们通常采用负采样的方法,来避免查询整个此表,从而将多分类问题转换为二分类问题。具体实现过程如图6:
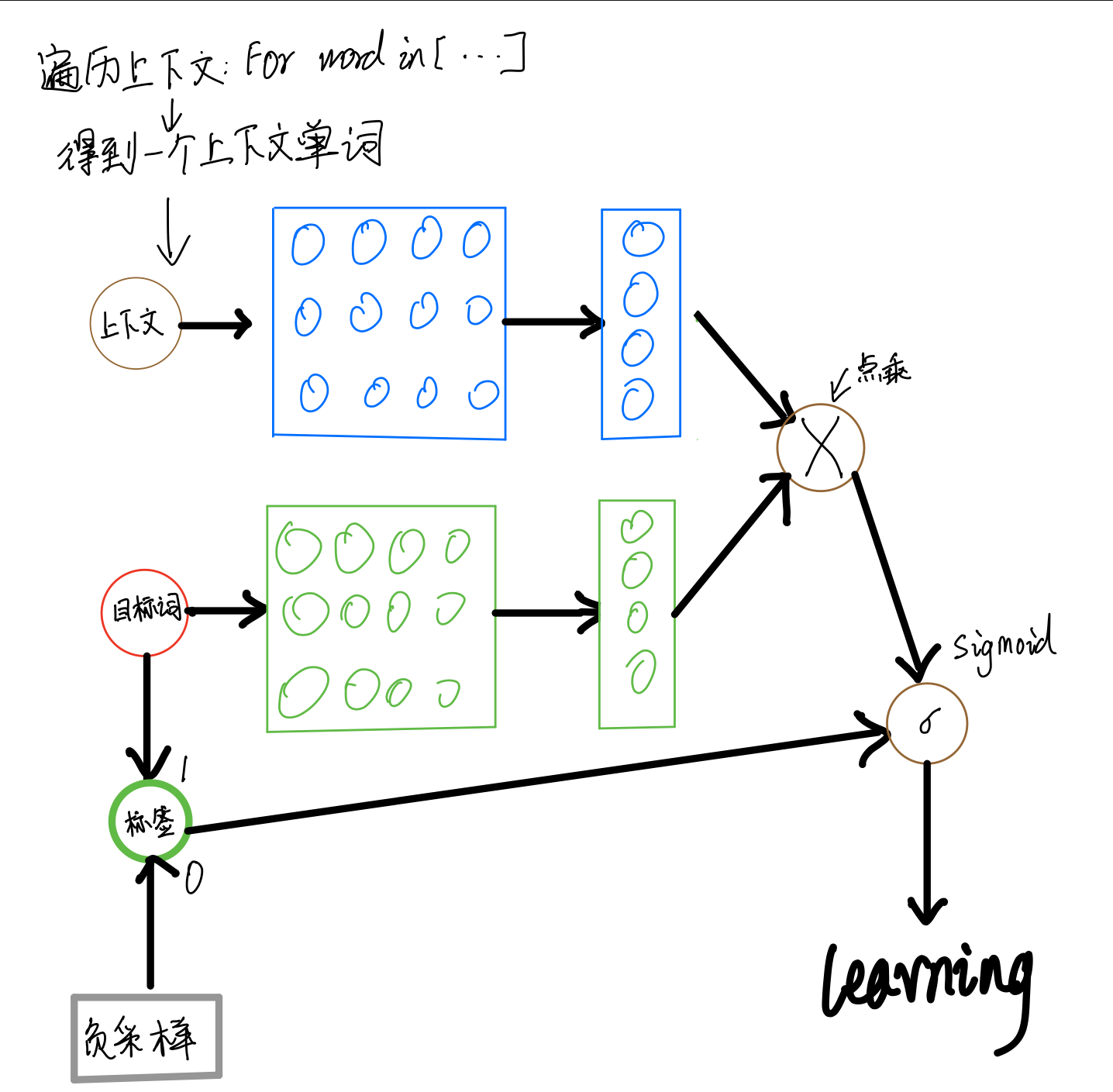
图6:CBOW算法的实际实现
在实现的过程中,通常会让模型接收3个tensor输入:
-
代表上下文单词的tensor:假设我们称之为context_words VVV,一般来说,这个tensor是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个中心词具体的ID。
-
代表目标词的tensor:假设我们称之为target_words TTT,一般来说,这个tensor同样是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个目标词具体的ID。
-
代表目标词标签的tensor:假设我们称之为labels LLL,一般来说,这个tensor是一个形状为[batch_size, 1]的tensor,每个元素不是0就是1(0:负样本,1:正样本)。
模型训练过程如下:
- 首先遍历上下文,得到上下文中的一个单词,用VVV(上下文)去查询W0W_0W0,用TTT(目标词)去查询W1W_1W1,分别得到两个形状为[batch_size, embedding_size]的tensor,记为H1H_1H1和H2H_2H2。
- 点乘这两个tensor,最终得到一个形状为[batch_size]的tensor O=[Oi=∑jH0[i,j]∗H1[i,j]]i=1batch_sizeO = [O_i = \sum_j H_0[i,j] * H_1[i,j]]_{i=1}^{batch\_size}O=[Oi=∑jH0[i,j]∗H1[i,j]]i=1batch_size。
- 使用随即负采样得到一些负样本(0),同时以目标词作为正样本(1),输入值标签信息label。
- 使用sigmoid函数作用在OOO上,将上述点乘的结果归一化为一个0-1的概率值,作为预测概率,根据标签信息label训练这个模型即可。
使用飞桨实现CBOW
接下来我们将学习使用飞桨实现CBOW模型的方法。在飞桨中,不同深度学习模型的训练过程基本一致,流程如下:
-
数据处理:选择需要使用的数据,并做好必要的预处理工作。
-
网络定义:使用飞桨定义好网络结构,包括输入层,中间层,输出层,损失函数和优化算法。
-
网络训练:将准备好的数据送入神经网络进行学习,并观察学习的过程是否正常,如损失函数值是否在降低,也可以打印一些中间步骤的结果出来等。
-
训练结果与总结:使用测试集合测试训练好的神经网络,看看训练效果如何。
在数据处理前,需要先加载飞桨平台(如果用户在本地使用,请确保已经安装飞桨)。
In[ ]import io import os import sys import requests from collections import OrderedDict import math import random import numpy as np import paddle import paddle.fluid as fluid from paddle.fluid.dygraph.nn import Embedding
数据处理
首先,找到一个合适的语料用于训练word2vec模型。我们选择text8数据集,这个数据集里包含了大量从维基百科收集到的英文语料,我们可以通过如下码下载,下载后的文件被保存在当前目录的text8.txt文件内。
In[ ]#下载语料用来训练word2vec
def download():
#可以从百度云服务器下载一些开源数据集(dataset.bj.bcebos.com)
corpus_url = "https://dataset.bj.bcebos.com/word2vec/text8.txt"
#使用python的requests包下载数据集到本地
web_request = requests.get(corpus_url)
corpus = web_request.content
#把下载后的文件存储在当前目录的text8.txt文件内
with open("./text8.txt", "wb") as f:
f.write(corpus)
f.close()
download()
接下来,把下载的语料读取到程序里,并打印前500个字符看看语料的样子,代码如下:
In[ ]#读取text8数据
def load_text8():
with open("./text8.txt", "r") as f:
corpus = f.read().strip("\n")
f.close()
return corpus
corpus = load_text8()
#打印前500个字符,简要看一下这个语料的样子
print(corpus[:500])
anarchism originated as a term of abuse first used against early working class radicals including the diggers of the english revolution and the sans culottes of the french revolution whilst the term is still used in a pejorative way to describe any act that used violent means to destroy the organization of society it has also been taken up as a positive label by self defined anarchists the word anarchism is derived from the greek without archons ruler chief king anarchism as a political philoso
一般来说,在自然语言处理中,需要先对语料进行切词。对于英文来说,可以比较简单地直接使用空格进行切词,代码如下:
In[ ]#对语料进行预处理(分词)
def data_preprocess(corpus):
#由于英文单词出现在句首的时候经常要大写,所以我们把所有英文字符都转换为小写,
#以便对语料进行归一化处理(Apple vs apple等)
corpus = corpus.strip().lower()
corpus = corpus.split(" ")
return corpus
corpus = data_preprocess(corpus)
print(corpus[:50])
['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first', 'used', 'against', 'early', 'working', 'class', 'radicals', 'including', 'the', 'diggers', 'of', 'the', 'english', 'revolution', 'and', 'the', 'sans', 'culottes', 'of', 'the', 'french', 'revolution', 'whilst', 'the', 'term', 'is', 'still', 'used', 'in', 'a', 'pejorative', 'way', 'to', 'describe', 'any', 'act', 'that', 'used', 'violent', 'means', 'to', 'destroy', 'the']
在经过切词后,需要对语料进行统计,为每个词构造ID。一般来说,可以根据每个词在语料中出现的频次构造ID,频次越高,ID越小,便于对词典进行管理。代码如下:
In[ ]#构造词典,统计每个词的频率,并根据频率将每个词转换为一个整数id
def build_dict(corpus):
#首先统计每个不同词的频率(出现的次数),使用一个词典记录
word_freq_dict = dict()
for word in corpus:
if word not in word_freq_dict:
word_freq_dict[word] = 0
word_freq_dict[word] += 1
#将这个词典中的词,按照出现次数排序,出现次数越高,排序越靠前
#一般来说,出现频率高的高频词往往是:I,the,you这种代词,而出现频率低的词,往往是一些名词,如:nlp
word_freq_dict = sorted(word_freq_dict.items(), key = lambda x:x[1], reverse = True)
#构造3个不同的词典,分别存储,
#每个词到id的映射关系:word2id_dict
#每个id出现的频率:word2id_freq
#每个id到词典映射关系:id2word_dict
word2id_dict = dict()
word2id_freq = dict()
id2word_dict = dict()
#按照频率,从高到低,开始遍历每个单词,并为这个单词构造一个独一无二的id
for word, freq in word_freq_dict:
curr_id = len(word2id_dict)
word2id_dict[word] = curr_id
word2id_freq[word2id_dict[word]] = freq
id2word_dict[curr_id] = word
return word2id_freq, word2id_dict, id2word_dict
word2id_freq, word2id_dict, id2word_dict = build_dict(corpus)
vocab_size = len(word2id_freq)
print("there are totoally %d different words in the corpus" % vocab_size)
for _, (word, word_id) in zip(range(50), word2id_dict.items()):
print("word %s, its id %d, its word freq %d" % (word, word_id, word2id_freq[word_id]))
there are totoally 253854 different words in the corpus word the, its id 0, its word freq 1061396 word of, its id 1, its word freq 593677 word and, its id 2, its word freq 416629 word one, its id 3, its word freq 411764 word in, its id 4, its word freq 372201 word a, its id 5, its word freq 325873 word to, its id 6, its word freq 316376 word zero, its id 7, its word freq 264975 word nine, its id 8, its word freq 250430 word two, its id 9, its word freq 192644 word is, its id 10, its word freq 183153 word as, its id 11, its word freq 131815 word eight, its id 12, its word freq 125285 word for, its id 13, its word freq 118445 word s, its id 14, its word freq 116710 word five, its id 15, its word freq 115789 word three, its id 16, its word freq 114775 word was, its id 17, its word freq 112807 word by, its id 18, its word freq 111831 word that, its id 19, its word freq 109510 word four, its id 20, its word freq 108182 word six, its id 21, its word freq 102145 word seven, its id 22, its word freq 99683 word with, its id 23, its word freq 95603 word on, its id 24, its word freq 91250 word are, its id 25, its word freq 76527 word it, its id 26, its word freq 73334 word from, its id 27, its word freq 72871 word or, its id 28, its word freq 68945 word his, its id 29, its word freq 62603 word an, its id 30, its word freq 61925 word be, its id 31, its word freq 61281 word this, its id 32, its word freq 58832 word which, its id 33, its word freq 54788 word at, its id 34, its word freq 54576 word he, its id 35, its word freq 53573 word also, its id 36, its word freq 44358 word not, its id 37, its word freq 44033 word have, its id 38, its word freq 39712 word were, its id 39, its word freq 39086 word has, its id 40, its word freq 37866 word but, its id 41, its word freq 35358 word other, its id 42, its word freq 32433 word their, its id 43, its word freq 31523 word its, its id 44, its word freq 29567 word first, its id 45, its word freq 28810 word they, its id 46, its word freq 28553 word some, its id 47, its word freq 28161 word had, its id 48, its word freq 28100 word all, its id 49, its word freq 26229
得到word2id词典后,我们可以进一步处理原始语料,把每个词替换成对应的ID,便于神经网络进行处理,代码如下:
In[ ]#把语料转换为id序列
def convert_corpus_to_id(corpus, word2id_dict):
#使用一个循环,将语料中的每个词替换成对应的id,以便于神经网络进行处理
corpus = [word2id_dict[word] for word in corpus]
return corpus
corpus = convert_corpus_to_id(corpus, word2id_dict)
print("%d tokens in the corpus" % len(corpus))
print(corpus[:50])
17005207 tokens in the corpus [5233, 3080, 11, 5, 194, 1, 3133, 45, 58, 155, 127, 741, 476, 10571, 133, 0, 27349, 1, 0, 102, 854, 2, 0, 15067, 58112, 1, 0, 150, 854, 3580, 0, 194, 10, 190, 58, 4, 5, 10712, 214, 6, 1324, 104, 454, 19, 58, 2731, 362, 6, 3672, 0]
接下来,需要使用二次采样法处理原始文本。二次采样法的主要思想是降低高频词在语料中出现的频次,从而优化整个词表的词向量训练效果,代码如下:
In[ ]#使用二次采样算法(subsampling)处理语料,强化训练效果
def subsampling(corpus, word2id_freq):
#这个discard函数决定了一个词会不会被替换,这个函数是具有随机性的,每次调用结果不同
#如果一个词的频率很大,那么它被遗弃的概率就很大
def discard(word_id):
return random.uniform(0, 1) < 1 - math.sqrt(
1e-4 / word2id_freq[word_id] * len(corpus))
corpus = [word for word in corpus if not discard(word)]
return corpus
corpus = subsampling(corpus, word2id_freq)
print("%d tokens in the corpus" % len(corpus))
print(corpus[:50])
8745112 tokens in the corpus [5233, 3080, 3133, 741, 476, 10571, 27349, 854, 15067, 58112, 854, 3580, 58, 10712, 214, 1324, 104, 454, 2731, 362, 3672, 371, 36, 539, 1423, 2757, 567, 686, 7088, 5233, 1052, 27, 320, 44611, 2877, 792, 186, 5233, 200, 602, 1134, 2621, 25, 8983, 279, 4147, 141, 6437, 4186, 32]
在完成语料数据预处理之后,需要构造训练数据。根据上面的描述,我们需要使用一个滑动窗口对语料从左到右扫描,在每个窗口内,通过上下文预测中心词,并形成训练数据。
在实际操作中,由于词表往往很大(50000,100000等),对大词表的一些矩阵运算(如softmax)需要消耗巨大的资源,因此可以通过负采样的方式模拟softmax的结果。具体来说,给定上下文和需要预测的中心词,把中心词作为正样本;通过词表随机采样的方式,选择若干个负样本。这样就把一个大规模分类问题转化为一个2分类问题,通过这种方式优化计算速度,代码如下:
In[ ]#构造数据,准备模型训练
#max_window_size代表了最大的window_size的大小,程序会根据max_window_size从左到右扫描整个语料
#negative_sample_num代表了对于每个正样本,我们需要随机采样多少负样本用于训练,
#一般来说,negative_sample_num的值越大,训练效果越稳定,但是训练速度越慢。
def build_data(corpus, word2id_dict, word2id_freq, max_window_size = 3,
negative_sample_num = 4):
#使用一个list存储处理好的数据
dataset = []
center_word_idx=0
#从左到右,开始枚举每个中心点的位置
while center_word_idx < len(corpus):
#以max_window_size为上限,随机采样一个window_size,这样会使得训练更加稳定
window_size = random.randint(1, max_window_size)
#当前的中心词就是center_word_idx所指向的词,可以当作正样本
positive_word = corpus[center_word_idx]
#以当前中心词为中心,左右两侧在window_size内的词就是上下文
context_word_range = (max(0, center_word_idx - window_size), min(len(corpus) - 1, center_word_idx + window_size))
context_word_candidates = [corpus[idx] for idx in range(context_word_range[0], context_word_range[1]+1) if idx != center_word_idx]
#对于每个正样本来说,随机采样negative_sample_num个负样本,用于训练
for context_word in context_word_candidates:
#首先把(上下文,正样本,label=1)的三元组数据放入dataset中,
#这里label=1表示这个样本是个正样本
dataset.append((context_word, positive_word, 1))
#开始负采样
i = 0
while i < negative_sample_num:
negative_word_candidate = random.randint(0, vocab_size-1)
if negative_word_candidate is not positive_word:
#把(上下文,负样本,label=0)的三元组数据放入dataset中,
#这里label=0表示这个样本是个负样本
dataset.append((context_word, negative_word_candidate, 0))
i += 1
center_word_idx = min(len(corpus) - 1, center_word_idx + window_size)
if center_word_idx == (len(corpus) - 1):
center_word_idx += 1
if center_word_idx % 100000 == 0:
print(center_word_idx)
return dataset
dataset = build_data(corpus, word2id_dict, word2id_freq)
for _, (context_word, target_word, label) in zip(range(50), dataset):
print("center_word %s, target %s, label %d" % (id2word_dict[context_word],
id2word_dict[target_word], label))
训练数据准备好后,把训练数据都组装成mini-batch,并准备输入到网络中进行训练,代码如下:
In[ ]#构造mini-batch,准备对模型进行训练
#我们将不同类型的数据放到不同的tensor里,便于神经网络进行处理
#并通过numpy的array函数,构造出不同的tensor来,并把这些tensor送入神经网络中进行训练
def build_batch(dataset, batch_size, epoch_num):
#context_word_batch缓存batch_size个中心词
context_word_batch = []
#target_word_batch缓存batch_size个目标词(可以是正样本或者负样本)
target_word_batch = []
#label_batch缓存了batch_size个0或1的标签,用于模型训练
label_batch = []
#eval_word_batch每次随机生成几个样例,用于在运行阶段对模型做评估,以便更好地可视化训练效果。
eval_word_batch = []
for epoch in range(epoch_num):
#每次开启一个新epoch之前,都对数据进行一次随机打乱,提高训练效果
random.shuffle(dataset)
for context_word, target_word, label in dataset:
#遍历dataset中的每个样本,并将这些数据送到不同的tensor里
context_word_batch.append([context_word])
target_word_batch.append([target_word])
label_batch.append(label)
#构造训练中评估的样本,这里我们生成'one','king','chip'三个词的同义词,
#看模型认为的同义词有哪些
if len(eval_word_batch) == 0:
eval_word_batch.append([word2id_dict['one']])
elif len(eval_word_batch) == 1:
eval_word_batch.append([word2id_dict['king']])
elif len(eval_word_batch) ==2:
eval_word_batch.append([word2id_dict['who']])
# eval_word_batch.append([random.randint(0, 99)])
# elif len(eval_word_batch) < 10:
# eval_word_batch.append([random.randint(0, vocab_size-1)])
#当样本积攒到一个batch_size后,我们把数据都返回回来
#在这里我们使用numpy的array函数把list封装成tensor
#并使用python的迭代器机制,将数据yield出来
#使用迭代器的好处是可以节省内存
if len(context_word_batch) == batch_size:
yield epoch,\
np.array(context_word_batch).astype("int64"),\
np.array(target_word_batch).astype("int64"),\
np.array(label_batch).astype("float32"),\
np.array(eval_word_batch).astype("int64")
context_word_batch = []
target_word_batch = []
label_batch = []
eval_word_batch = []
if len(context_word_batch) > 0:
yield epoch,\
np.array(context_word_batch).astype("int64"),\
np.array(target_word_batch).astype("int64"),\
np.array(label_batch).astype("float32"),\
np.array(eval_word_batch).astype("int64")
for _, batch in zip(range(10), build_batch(dataset, 128, 3)):
print(batch)
网络定义
定义skip-gram的网络结构,用于模型训练。在飞桨动态图中,对于任意网络,都需要定义一个继承自fluid.dygraph.Layer的类来搭建网络结构、参数等数据的声明。同时需要在forward函数中定义网络的计算逻辑。值得注意的是,我们仅需要定义网络的前向计算逻辑,飞桨会自动完成神经网络的反向计算,代码如下:
In[ ]#定义skip-gram训练网络结构 #这里我们使用的是paddlepaddle的1.6.1版本 #一般来说,在使用fluid训练的时候,我们需要通过一个类来定义网络结构,这个类继承了fluid.dygraph.Layer class SkipGram(fluid.dygraph.Layer): def __init__(self, name_scope, vocab_size, embedding_size, init_scale=0.1): #name_scope定义了这个类某个具体实例的名字,以便于区分不同的实例(模型) #vocab_size定义了这个skipgram这个模型的词表大小 #embedding_size定义了词向量的维度是多少 #init_scale定义了词向量初始化的范围,一般来说,比较小的初始化范围有助于模型训练 super(SkipGram, self).__init__(name_scope) self.vocab_size = vocab_size self.embedding_size = embedding_size #使用paddle.fluid.dygraph提供的Embedding函数,构造一个词向量参数 #这个参数的大小为:[self.vocab_size, self.embedding_size] #数据类型为:float32 #这个参数的名称为:embedding_para #这个参数的初始化方式为在[-init_scale, init_scale]区间进行均匀采样 self.embedding = Embedding( self.full_name(), size=[self.vocab_size, self.embedding_size], dtype='float32', param_attr=fluid.ParamAttr( name='embedding_para', initializer=fluid.initializer.UniformInitializer( low=-0.5/embedding_size, high=0.5/embedding_size))) #使用paddle.fluid.dygraph提供的Embedding函数,构造另外一个词向量参数 #这个参数的大小为:[self.vocab_size, self.embedding_size] #数据类型为:float32 #这个参数的名称为:embedding_para #这个参数的初始化方式为在[-init_scale, init_scale]区间进行均匀采样 #跟上面不同的是,这个参数的名称跟上面不同,因此, #embedding_out_para和embedding_para虽然有相同的shape,但是权重不共享 self.embedding_out = Embedding( self.full_name(), size=[self.vocab_size, self.embedding_size], dtype='float32', param_attr=fluid.ParamAttr( name='embedding_out_para', initializer=fluid.initializer.UniformInitializer( low=-0.5/embedding_size, high=0.5/embedding_size))) #定义网络的前向计算逻辑 #context_words是一个tensor(mini-batch),表示中心词 #target_words是一个tensor(mini-batch),表示目标词 #label是一个tensor(mini-batch),表示这个词是正样本还是负样本(用0或1表示) #eval_words是一个tensor(mini-batch), #用于在训练中计算这个tensor中对应词的同义词,用于观察模型的训练效果 def forward(self, context_words, target_words, label, eval_words): #首先,通过embedding_para(self.embedding)参数,将mini-batch中的词转换为词向量 #这里context_words和eval_words_emb查询的是一个相同的参数 #而target_words_emb查询的是另一个参数 context_words_emb = self.embedding(context_words) target_words_emb = self.embedding_out(target_words) eval_words_emb = self.embedding(eval_words) #context_words_emb = [batch_size, embedding_size] #target_words_emb = [batch_size, embedding_size] #我们通过点乘的方式计算中心词到目标词的输出概率,并通过sigmoid函数估计这个词是正样本还是负样本的概率。 word_sim = fluid.layers.elementwise_mul(context_words_emb, target_words_emb) word_sim = fluid.layers.reduce_sum(word_sim, dim = -1) pred = fluid.layers.sigmoid(word_sim) #通过估计的输出概率定义损失函数 loss = fluid.layers.sigmoid_cross_entropy_with_logits(word_sim, label) loss = fluid.layers.reduce_mean(loss) #我们通过一个矩阵乘法,来对每个词计算他的同义词 #on_fly在机器学习或深度学习中往往指在在线计算中做什么, #比如我们需要在训练中做评估,就可以说evaluation_on_fly word_sim_on_fly = fluid.layers.matmul(eval_words_emb, self.embedding._w, transpose_y = True) #返回前向计算的结果,飞桨会通过backward函数自动计算出反向结果。 return pred, loss, word_sim_on_fly
网络训练
完成网络定义后,就可以启动模型训练。我们定义每隔100步打印一次loss,以确保当前的网络是正常收敛的。同时,我们每隔1000步观察一下计算出来的同义词,可视化网络训练效果,代码如下:
In[11]#开始训练,定义一些训练过程中需要使用的超参数
batch_size = 512
epoch_num = 3
embedding_size = 200
step = 0
learning_rate = 0.001
def get_similar_tokens(query_token, k, embed):
W = embed.numpy()
x = W[word2id_dict[query_token]]
cos = np.dot(W, x) / np.sqrt(np.sum(W * W, axis=1) * np.sum(x * x) + 1e-9)
flat = cos.flatten()
indices = np.argpartition(flat, -k)[-k:]
indices = indices[np.argsort(-flat[indices])]
for i in indices:
print('for word %s, the similar word is %s' % (query_token, str(id2word_dict[i])))
#将模型放到GPU上训练(fluid.CUDAPlace(0)),如果需要指定CPU,则需要改为fluid.CPUPlace()
with fluid.dygraph.guard(fluid.CUDAPlace(0)):
#通过我们定义的SkipGram类,来构造一个Skip-gram模型网络
skip_gram_model = SkipGram("skip_gram_model", vocab_size, embedding_size)
#构造训练这个网络的优化器
adam = fluid.optimizer.AdamOptimizer(learning_rate=learning_rate)
#使用build_batch函数,以mini-batch为单位,遍历训练数据,并训练网络
for epoch_num, context_words, target_words, label, eval_words in build_batch(
dataset, batch_size, epoch_num):
# print(eval_words.shape[0])
#使用fluid.dygraph.to_variable函数,将一个numpy的tensor,转换为飞桨可计算的tensor
context_words_var = fluid.dygraph.to_variable(context_words)
target_words_var = fluid.dygraph.to_variable(target_words)
label_var = fluid.dygraph.to_variable(label)
eval_words_var = fluid.dygraph.to_variable(eval_words)
#将转换后的tensor送入飞桨中,进行一次前向计算,并得到计算结果
pred, loss, word_sim_on_fly = skip_gram_model(
context_words_var, target_words_var, label_var, eval_words_var)
#通过backward函数,让程序自动完成反向计算
loss.backward()
#通过minimize函数,让程序根据loss,完成一步对参数的优化更新
adam.minimize(loss)
#使用clear_gradients函数清空模型中的梯度,以便于下一个mini-batch进行更新
skip_gram_model.clear_gradients()
#每经过100个mini-batch,打印一次当前的loss,看看loss是否在稳定下降
step += 1
if step % 100 == 0:
print("epoch num:%d, step %d, loss %.3f" % (epoch_num, step, loss.numpy()[0]))
#没经过1000个mini-batch,打印一次模型对eval_words中的10个词计算的同义词
#这里我们使用词和词之间的向量点积作为衡量相似度的方法
#我们只打印了5个最相似的词
if step % 1000 == 0:
# word_sim_on_fly = word_sim_on_fly.numpy()
# word_sim_on_fly = np.argsort(word_sim_on_fly)
# for _id in range(len(eval_words)):
# curr_eval_word = id2word_dict[eval_words[_id][0]]
# top_n_sim_words = []
# for j in range(1, 6):
# top_n_sim_words.append(id2word_dict[word_sim_on_fly[_id][-1 * j]])
# print("for word %s, the most similar word is: %s" %
# (curr_eval_word, ", ".join(top_n_sim_words)))
get_similar_tokens('one', 5, skip_gram_model.embedding._w)
get_similar_tokens('who', 5, skip_gram_model.embedding._w)
get_similar_tokens('king', 5, skip_gram_model.embedding._w)
训练结果与总结
从打印结果可以看到,经过一定步骤的训练,loss逐渐下降并趋于稳定。大概到55000步时,就能发现模型可以学习到一些有趣的语言现象。比如:

跟who比较接近的词有"who, he, his, whose"。
跟one比较接近的词是"one, five, four, two, nine"
跟king比较接近的词有"king, alfonso(葡萄牙的六位国王和西班牙几个古老地区的国王的名字), throne(王位), economist"
从结果可以看出来,对于出现频率最高的数字以及who, he等代词,模型可以很快地学习出它们之间的相似性,但对于king这类出现频率相对较低的词来说,模型很难学习出它们的相似性。这也是CBOW算法的局限性。
一般来说,CBOW比Skip-gram训练速度快,训练过程更加稳定,而在生僻字(出现频率低的字)处理上,skip-gram比CBOW效果更好。原因就是CBOW算法采用的是通过上下文预测中心词,即用多个词预测单个词的方法,每个训练step会学习很多样本,因此收敛速度更快。而skip-gram算法采用的是中心词预测上下文,即单个词预测多个词的方法,每个step只学习一个词(中心词),并不会刻意回避生僻字,致使每个词都能被学习到,因此收敛速度慢,但处理生僻字能力更高。
两个方法的原理决定了它们的优势及短板。
需要说明的是,在本例中并没有采用上下文average或者将上下文求和之后作为输入的方式,而是先遍历上下文,依次将每个单词作为输入,做这个尝试是为了提高CBOW算法对生僻字处理的能力。
结语
这是CBOW算法的一个简单实现,后面的版本会在网络模型、数据处理上进一步优化。
在使用word2vec模型的过程中,研究人员发现了一些有趣的现象。比如当得到整个词表的word embedding之后,对任意词都可以基于向量乘法计算跟这个词最接近的词。我们会发现,word2vec模型可以自动学习出一些同义词关系,如:
Top 5 words closest to "beijing" are: 1. newyork 2. paris 3. tokyo 4. berlin 5. soul ... Top 5 words closest to "apple" are: 1. banana 2. pineapple 3. huawei 4. peach 5. orange
除此以外,研究人员还发现可以使用加减法完成一些基于语言的逻辑推理,如:
Top 1 words closest to "king - man + women" are 1. queen ... Top 1 words closest to "captial - china + american" are 1. newyork
这些有趣的现象,来源于神经网络的强大能力。这表明:对于一个有着特定功能的神经网络,只要有大量的数据来训练它,就能在它的本职工作上,取得非常出色的成绩,除此之外,我们也能在其他方面,也获得意想不到的收获
(本文参考项目:《百度架构师手把手教深度学习》课程项目4-2:词向量word2rec)
点击链接,使用AI Studio一键上手实践项目吧:https://aistudio.baidu.com/aistudio/projectdetail/306925
下载安装命令 ## CPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/cpu paddlepaddle ## GPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/gpu paddlepaddle-gpu
>> 访问 PaddlePaddle 官网,了解更多相关内容。

- “《编程珠玑》(第2版)第2章”:B题(向量旋转)
- 向量偏移——由“食物链”引发的总结
- R语言(1)——向量
- 为向量法求组合问题
- 判断向量平行和垂直的条件
- Deep Learning in NLP (一)词向量和语言模型
- C/C++ 定义向量、赋值和使用
- 协方差矩阵特征向量的意义
- Deep Learning in NLP (一)词向量和语言模型
- 向量计算
- 找出数组中任何相邻子向量的最大和
- 有序向量Vector
- ARM7内核寄存器、中断向量控制器
- c++中的向量一般操作
- 支持向量分类机
- 分类问题 特征向量的归一化方法
- R语言笔记1--向量、数组、矩阵、数据框、列表
- 使用unlist将日期型数据的列表转换为向量时,出现的异常
- 【POJ1984】【二维加权并查集】【向量运算】【四边形法则】
- Java代码实现有序向量的二分查找