File、递归、IO流
1、File类
文件和目录路径名的抽象表示形式。 这个类与操作系统无关。
(1)分隔符:
Windows路径分隔符 ;
Windows名称分隔符 \ 反斜杠
Linux路径分隔符 :
Linux名称分隔符 / 正斜杠
所以路径不能写死。
路径不区分大小写,\ 反斜杠也是转义字符,要用两个反斜杠。
(2)构造方法
①File(String pathname)
路径可以文件 / 文件夹结尾,可以相对路径、绝对路径;路径存不存在都可,创建File对象,只是把字符串路径封装为File对象,不考虑路径真假。
②File(String parent, String child)
路径分为了父路径和子路径,使用更灵活
③File(File parent, String child)
在②的基础上,父路径是File类型,可以使用File的方法对路径进行操作,再使用路径创建对象。
(3)获取、判断、创建、删除方法
mkdir、mkdirs 的区别;后者可多级目录,不存在的也创建
createNewFile 抛出了IO异常,要处理异常,创建的路径必须存在,否则异常
delete:文件夹中有文件,不删除。
遍历:
String [] list() :返回String数组,表示File目录中所有子文件和目录。
File[] listFile() :返回File数组,表示File目录中所有子文件和目录(不包括子目录里面的)。把文件、文件夹封装为File对象,存到File数组中
注意:
①遍历的是构造方法中给出的目录;
②构造中的目录不存在、给的路径不是一个目录,则空指针异常;
递归:
调用方法时,主体不变,每次参数不同,可以使用递归;
构造方法不可递归;
递归遍历多级目录;
过滤器-遍历:
File[] listFiles(FilenameFilter filter)
File[] listFiles(FileFilter filter)
这两个过滤器接口的accept方法参数不一样
要搞清楚:
①过滤器的accept方法是谁调用的;
②accept方法的pathname是什么?
listFiles做的事情:
①对构造方法中传递的目录遍历,把文件、文件夹封装为File对象;
②listFiles方法调用 传过来的过滤器中的 accept 方法;
③把得到的File对象,传递给 accept 方法(返回布尔值) 的参数 pathname;
④返回true 的存到File数组中
过滤器可以用Lambda ,过滤器是一个接口,要自己定义实现类,这里用Lambda
2、IO流
输入输出是对内存来说的;1字符=2字节
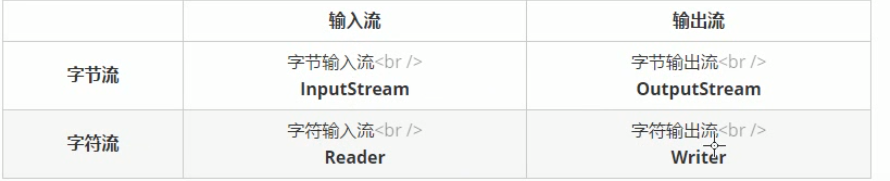
3、FileOutputStream
OutputStream 字节输出流,子类FileOutputStream文件字节输出流,作用是写入硬盘的文件中。
构造方法:两种参数,表示写入数据的目的地,一种路径,一种是new文件;
构造方法的作用:
①创建对象;
②会根据参数的文件/文件路径,创建一个空的文件;
③把FileOutputStream对象指向创建好的文件
写入数据(内存 >> 硬盘):
Java程序>>JVM>>OS>>OS调用写数据的方法>>把数据写到文件中
使用步骤:
①创建对象;
②调用对象的方法write,把数据写入到文件中;
③释放资源 close;
写数据时,10进制转换为2进制,文本编辑器打开文件时,会查询编码表,把字节转换为字符表示,0-127查询ASCII 表,其他值查系统默认码表(中文GBK)
续写和换行:
续写:构造的时候多一个参数append是否 true;
换行符号:
windows:\r\n
Linux:/n
mac:/r
4、FileInputStream 与Out相反、类似
构造方法的作用:
①创建对象;
②把FileInputStream对象指向要读取的文件。
read 读取完自动指向下一个,读到末尾是 -1
一次性读取多个字节:
从输入流中读取定量的字节,并将其存储在缓冲区数组 bytes 中;
明确两件事情:
①read的参数 byte[] bytes 的作用:起到缓冲作用,存储每次读取到的多个字节;数组的长度一般为1024的整数倍
② fis.read(bytes) 返回的是int类型,是每次读取的有效字节的个数;
可以通过new String(bytes)输出为字符串;也可以String(byte[] bytes, int offset, int length)字节数组的一部分转换为字符串。
一次读取写入多个字节,效率高很多!
.---------
5、字符输入流Reader 子类 FileReader
一次读取一个字符,中文也一样。其他与字节流类似
6、字符输出流Writer 子类 FileWriter
使用步骤不同的是:
①创建对象;
②调用write方法,把数据写入到内存缓冲区(字符转换为字节的过程)
③调用flush方法,把内存缓冲区的数据,刷新到文件中;
④释放资源(会先做flush)
可以直接写字符串
7、处理流中的异常
①fw.close 放在finally中
②所以 fw需要定义在 try 外边,以提高作用域;
③用 close 时需要 fw 有值,所以 fw 初始化为 null ;
④close 要处理异常,又要继续try……catch ;
⑤并且在close之前判断 fw 是否为null ,不是时才执行④。
JDK7:
try后面增加了(),在括号内可以定义流对象,那么这个流对象的作用域就在try中有效,try代码执行完之后,流对象也可释放,不用finally。
JDK9:
try前面定义流对象,在try后的()可直接引入流对象的名称(变量名);
try代码执行完之后,流对象也可释放,不用finally。
8、
java.util.Properties extends Hashtable<k,v> implements Map<k,v>
此类表示了一个持久的属性集,Properties 可保存在流中或从流中加载。
这个集合是唯一一个和IO流相结合的集合;
可以使用集合中的方法store ,把集合中的临时数据,持久化写入硬盘;
可以使用集合中的方法load ,把硬盘中保存的文件(键值对),读取到集合中使用;
属性列表中每个键及其对应值都是字符串类型;双列集合;
setProperties(String key,String value)调用Hashtable的方法put ;
getProperties(String key)相当于Map的get(key);
stringPropertiesNames()返回此属性列表中的键集,相当于Map中的keySet方法
9、Properties 和IO流
(1)
void store(OutputStream out,String comments)
void store(Writer writer,String comments)
字节流不能写入中文,字符流可以;comments 是注释,解释保存的文件是做什么的,不能使用中文,会有乱码,默认是Unicom编码,一般使用空字符串。
使用步骤:
①创建Properties集合对象,添加数据;
②创建流对象,构造中绑定要输出的文件;
③用store ,把集合中的临时数据,写到硬盘;
④释放资源。
(2)load 与store相反
注意:在存储键值对的文件中,
①键与值默认的连接符可以使用 = ,空格(其他符号)
②可以用#注释,被注释的键值对不会再被读取;
③键与值默认都是字符串,不用再加引号
10、缓冲流
基本原理:是在创建流对象时,创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,提高效率。
(1)BufferedOutputStream
继承父类OutputStream的共性成员方法:close、flush、write……
构造方法:
①BufferedOutputStream(OutputStream out)创建一个新的缓冲输出流,以将数据写入指定的底层输出流;
②BufferedOutputStream(OutputStream out,int size)可以指定缓冲区大小。
使用步骤:
①创建OutputStream对象;
②创建BufferedOutputStream;
③write方法,把数据写入内部缓冲区;
④flush方法,缓冲区的数据刷新到文件中;
⑤close(只关缓冲流即可)
(2)BufferedInputStream
有缓冲区,也还可以用read一次性读取多个字节(从输入流中读取定量的字节,并将其存储在缓冲区数组 bytes 中;)
复制文件效率对比(大概):
①无缓冲流,无缓冲数组6000+ms
②无缓冲流,有缓冲数组10ms
③有缓冲流,无缓冲数组32ms
④有缓冲流,有缓冲数组5ms
(3)BufferedWriter字符缓冲输出流 extends Writer
继承了父类的共性成员方法
特有的成员方法:
void newLine()写入一个行分隔符,根据不同的OS,获取不同的分隔符。
(4)BufferedReader字符缓冲输入流 extends Reader
特有方法:
String readLine()读取一行数据;行的终止符 \n \r \r\n
返回该行内容的字符串,不包含任何终止符,如果已经到末尾,返回null
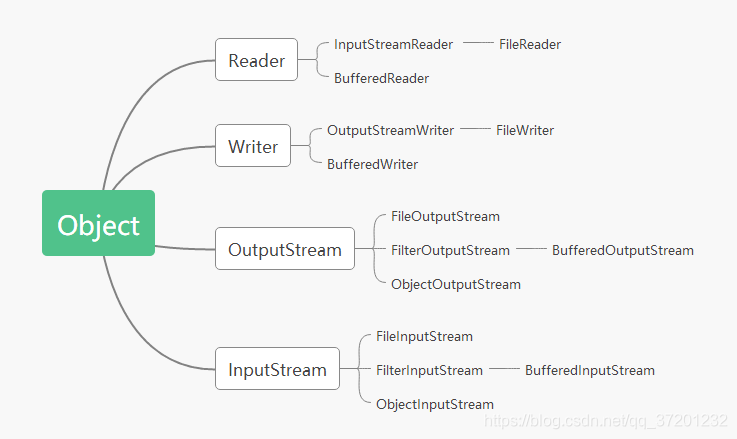
11、转换流InputStreamReader、OutputStreamWriter,可以指定解码编码格式。
FileReader 可以读取IDE默认编码格式(UTF-8)的文件;读取系统默认编码(GBK)会乱码。FileReader 底层也是用的字节输入流FileInputStream

(1)
OutputStreamWriter(OutputStream out, String charsetName) 第二个参数指定字符集,一般是FileOutputStream
使用步骤:
①创建OutputStreamWriter对象;
②创建(File)OutputStream;
③write方法,把字符转换为字节存储缓冲区;
④flush方法,内存缓冲区的字节刷新到文件中(使用字节流写字节的过程);
⑤close
(2)InputStreamReader 字节流通向字符流,解码的过程(文件->内存)
注意的是:构造方法中指定的编码表名称要和文件的编码相同,否则乱码。
12、序列化
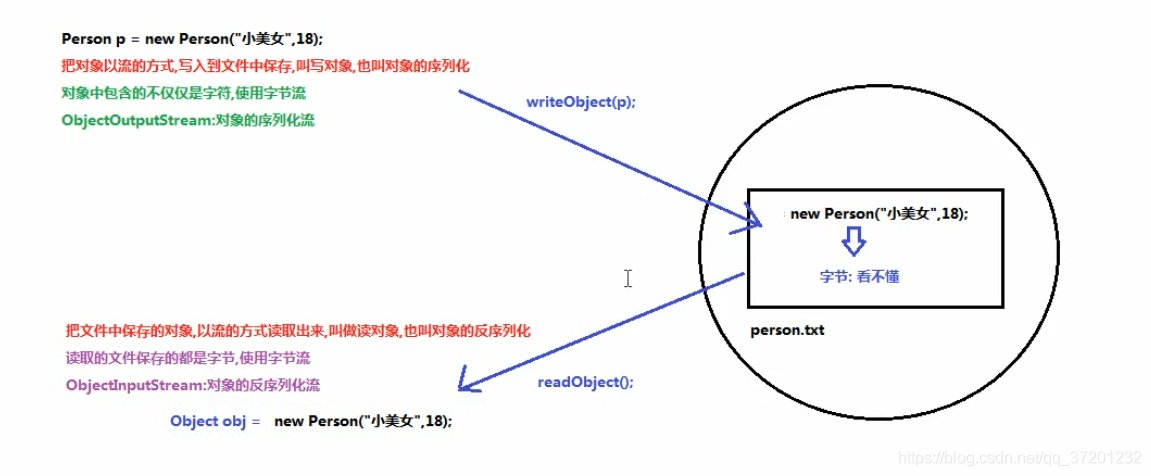
(1)ObjectOutputStream 对象的序列化流,把对象以流的方式写入到文件中保存。
使用方法跟其他流类似。
写的时候用的方法是:writeObject
要注意的是:要进行序列化的类必须实现Serializable 接口(标记型接口),否则异常。
(2)ObjectInputStream 对象的反序列化流,把文件中保存的对象,以流的方式读取出来使用。
特有的成员方法:readObject() 读取对象
使用步骤类似。
readObject 方法声明抛出了ClassNotFoundException(class文件找不到异常),当不存在对象的class文件时抛出此异常。
反序列化的前提:
①类必须实现Serializable 接口
②必须存在类对应的class文件
13、
transient 关键字,被修饰后不能被序列化;
static 修饰的也是不能被序列化。
14、实现Serializable 接口的类,会给.class文件添加一个序列号,若序列化之后修改了代码,.class会生成另一个序列号,反序列化的时候会对比 .class 和 txt中的序列号,不一致则会抛出序列号冲突异常(InvalidClassException)。
解决办法:
手动给类添加一个序列号,static final long类型的
static final long serialVersionUID = 42L;
15、PrintStream打印流:为其他输出流添加了功能,使它们能方便地打印各种数据值表示形式。
特点:
①只负责数据的输出,不负责数据的读取;
②不抛出 IO 异常;
③特有的方法print 、println
构造方法:
PrintStream(File file) 输出目的地是一个文件
PrintStream(OutputStream out) 输出目的地是一个字节输出流
PrintStream(String fileName) 输出目的地是文件路径
注意:
①使用继承父类的write方法写数据,查数据的时候会查编码表 97-> a
②用特有的print 、println方法写数据,原样输出
可以改变输出语句的目的地(打印流的流向);
默认输出在控制台;
使用System.setOut方法改变输出语句的目的地为参数中传递的打印流的目的地。
static void setOut(PrintStream out)
- 点赞
- 收藏
- 分享
- 文章举报
 蔴瓜
发布了13 篇原创文章 · 获赞 0 · 访问量 247
私信
关注
蔴瓜
发布了13 篇原创文章 · 获赞 0 · 访问量 247
私信
关注

- IO流——File类(利用递归列出所有文件)
- Java基础---Java---IO流-----File 类、递归、删除一个带内容的目录、列出指定目录下文件夹、FilenameFilte
- IO流-4.【File类】【递归】【属性类Properties】
- 黑马程序员——第十一篇:File类、方法递归、Io流
- JAVA File类、IO流体验与简介(字节流、字符流、序列流、打印流、编码、递归)
- IO流(二)之File,递归,Properties详解
- IO流(一):File和递归
- 黑马程序员——IO流之File类、递归、Properties类
- [javaSE] IO流(FIle对象递归文件列表)
- IO流-File对象-递归
- 【IO流】08 - file类中的方法 - 递归
- day21<IO流+&FIle递归>
- 23-IO流-40-IO流(File对象-练习-递归)
- 【java编程】IO流之File类列出所有文件和目录(递归例子)
- 黑马程序员_java_IO流_FileInputStream_FileOutputStream_File_递归_Properties_ByteArrayInputStream_ByteArrayOut
- 关于File类、递归、IO流与字节流,作为程序员必须要知道的几点!!!
- IO流3(File类、Properties、递归、打印流、序列流)
- 【IO流】08 - file类中的方法 - 递归
- 【IO流】09 - file类中的方法 - 文件队列(不用递归)
- Java基础---Java---IO流-----File 类、递归、删除一个带内容的目录、列出指定目录下文件夹、FilenameFilte