Redis从入门到实战:进阶篇
2020-04-05 12:02
337 查看
之前只是在项目简单使用了Redis(只是充当缓存层实现),对Redis的体系技术没深入了解,最近时间比较充裕,所以再次复习巩固Redis,然后打算写几篇博客记录以及分享所复习的Redis知识。
- Redis从入门到实战:入门篇
- Redis从入门到实战:实战篇
- Redis从入门到实战:进阶篇
- Redis从入门到实战:完结篇
Redis从入门到实战:进阶篇
- Redis事务
- Redis的发布与订阅
- Redis持久化机制(RDB+AOF)
- Redis明明是单线程,为什么性能还那么高(每秒读写10W次等特性)
- Redis流水线技术(管道)
Redis事务
事务这个词我们应该不陌生了,我们在使用MySQL或者Oracle过程中,都会开启事务,直到SQL执行完毕才会关掉事务。
可以说,事务是一种保证数据安全的机制。在关系型数据库中,事务是一组SQL的集合,要么全部执行成功,要么全部执行失败。
而在Redis中,事务是一组命令的集合,这一组命令会按照顺序在隔离的环境中执行,不受其他客户端发送来的命令打断。
下面给出官方解说
- 事务是一个单独的隔离操作,事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
- 事务是一个原子操作,事务中的命令要么全部被执行,要么全部都不执行。
- 事务可以一次执行多个命令。MULTI、EXEC、DISCARD和WATCH是Redis事务相关的命令。
- 可以把Redis事务看成四种阶段:开启事务,命令入队,执行事务,关闭事务。
- multi命令的执行标志着事务开启。
127.0.0.1:6379> multi OK
- multi命令可以将执行该命令的客户端从非事务状态切换至事务状态。
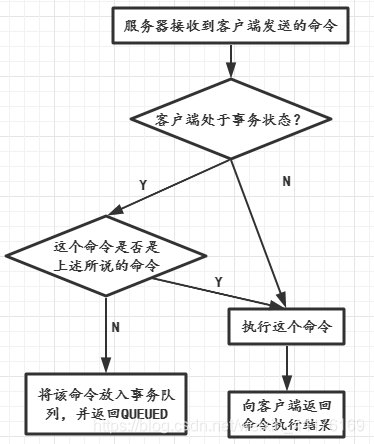
- 当Redis客户端处于非事务状态时,这个客户端的命令会立即被服务器执行。
- 当Redis客户端切换到事务状态之后,服务器会根据这个客户端发来的命令做出不同的响应。
如果客户端发送的命令是MULTI、EXEC、DISCARD和WATCH这四个命令中的一个,那么服务器会立即执行这个命令。
如果客户端发来的命令不是这四个命令,那么服务器不会立即执行这个命令,而是将这个命令放在一个事务队列中,然后向客户端返回QUEUED,表明这个命令被放入事务队列中了。127.0.0.1:6379> multi OK127.0.0.1:6379> set name xxxq QUEUED
- 事务队列是一个以先进先出(FIFO)的方式保存入队的命令,较先入队的命令放在队列的前面,较后入队的命令放在队列的后面。
127.0.0.1:6379> multi OK127.0.0.1:6379> set name xxxq QUEUED 127.0.0.1:6379> get name QUEUED 127.0.0.1:6379> set author zwq QUEUED 127.0.0.1:6379> get author QUEUED
- 服务器将会为上面所执行的命令创建一个队列,如下图所示:

- 当一个处于事务状态的客户端向服务器发送EXEC命令时,服务器会立即执行这个命令,然后执行事务队列中保存的所以命令,最后将执行命令的结果返回给客户端。当返回结果给客户端的时候,这个事务也就被关闭了。
127.0.0.1:6379> multi OK127.0.0.1:6379> set name xxxq QUEUED 127.0.0.1:6379> get name QUEUED 127.0.0.1:6379> set author zwq QUEUED 127.0.0.1:6379> get author QUEUED 127.0.0.1:6379> exec 1) OK 2) "xxxq" 3) OK 4) "zwq" 127.0.0.1:6379> get name "xxxq"
- watch命令是一个乐观锁。
- 它可以在EXEC命令执行前,监视任意数量的数据库键,并在EXEC命令执行时,检查监视的键是否至少有一个已经被修改过了,如果修改过了,服务器将拒绝执行事务,并向客户端返回代表事务执行失败的空回复。
- 下面举一个例子,我开启两个Redis客户端,第一个客户端使用Watch命令监听
name和author两个Key,随后使用multi命令开启事务,之后修改name的值。127.0.0.1:6379> watch name author OK 127.0.0.1:6379> multi OK127.0.0.1:6379> set name xq QUEUED
第二个客户端也执行修改name的值。127.0.0.1:6379> set name xxxxxq OK
然后在第一个客户端执行EXEC命令,发现此次事务执行失败。因为在执行EXEC命令的时候,Watch命令监听到name已经被修改了,Redis认为此次事务已经不安全了,所以就无效化事务队列中的所有命令。最后,name的值为第二个客户端修改的结果。

Redis的发布与订阅
- Redis的发布订阅主要有三个角色:发布者,订阅者,频道(消息的载体)。
- 频道是消息的载体,发布者可以往特定频道发送消息,订阅者可以订阅(也可以说是监听)特定频道的消息,一旦频道有了新的消息,就会推送给订阅者。
- 最经典的应用场景就是微博和公众号,任何粉丝只要关注(订阅)了某一个人的微博或者公众号,该微博或者公众号只有有状态更新,都会将消息推送(发布)到粉丝…
- 命令:
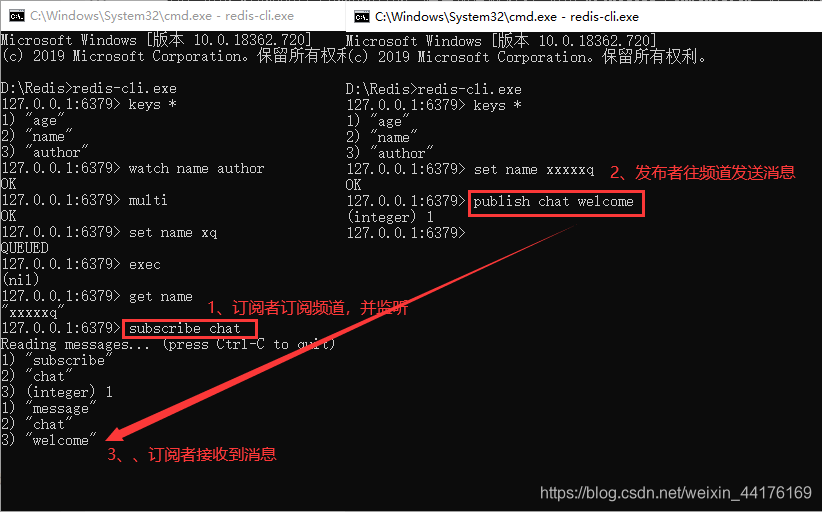
subscribe channel [channel..]:如subscribe “chat”表示订阅了"chat"频道。 - 这里还是打开两个客户端,第一个客户端(订阅者)订阅chat频道(当执行完上面命令的时候,第一个客户端处于监听状态),第二个客户端(发布者)往chat频道发送消息,然后第一个客户端就会立即收到消息。
Redis持久化机制(RDB+AOF)
为什么要将数据持久化?假如Redis服务器重启了一下,这时Redis之前缓存的数据都会消失,就得去MySQL等数据库查询数据,再备份到Redis中,这样会导致程序效率低下。而将Redis数据持久化之后,在重启Redis服务器的时候,只需要将持久化的数据拉取到内存中即可,这对于Redis每秒读写10次不算什么。Redis支持两种持久化方式:RDB,AOF。
RDB
- RDB(Redis Database)持久化是把当前进程数据生成快照保存在RDB文件的过程。
- RDB持久化生成的RDB文件是一个经过压缩的二进制文件。
- 触发RDB持久化过程分为手动触发和自动触发。
SAVE命令和BGSAVE命令都可以实现手动触发。
save命令
- 在客户端中执行save命令,就会触发Redis的持久化,但同时也是使Redis处于阻塞状态,直到RDB持久化完成,才会响应其他客户端发来的命令,所以在生产环境一定要慎用。

bgsave命令
- 执行bgsave命令,Redis父进程判断当前是否有正在执行的子进程,如RDB/AOF子进程,如果存在直接返回。
- 如果没有,父进程执行fork操作创建子进程,fork操作会阻塞父进程。父进程fork操作执行完成后,便不再阻塞父进程,可以继续响应其他命令。
- 子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换。
- 子进程发送信号给父进程表示完成,父进程更新统计信息。

- 自动触发的意思是Redis会判断是否满足持久化的条件,满足则自动执行bgsave命令进行持久化。是否满足则是通过Redis核心配置文件redis.conf来配置的。
- 接下来介绍有关RDB配置的内容:
# RDB 保存的条件 save 900 1 save 300 10 save 60 10000 # bgsave 失败之后,是否停止持久化数据到磁盘,yes 表示停止持久化,no 表示忽略错误继续写文件。 stop-writes-on-bgsave-error yes # RDB 文件压缩 rdbcompression yes # 写入文件和读取文件时是否开启 RDB 文件检查,检查是否有无损坏,如果在启动是检查发现损坏,则停止启动。 rdbchecksum yes # RDB 文件名 dbfilename dump.rdb # RDB 文件目录 dir ./
- save 参数:它是用来配置触发RDB持久化条件的参数,满足保存条件时将会把数据持久化到硬盘,使用的是bgsave命令。
save m n:是指在 m 秒内,如果有 n 个键发生改变,则自动触发持久化——bgsave命令。
save 900 1:表示 900 秒内如果至少有 1 个 key 值变化,则把数据持久化到硬盘。
save 300 10:表示 300 秒内如果至少有 10 个 key 值变化,则把数据持久化到硬盘。
save 60 10000:表示 60 秒内如果至少有 10000 个 key 值变化,则把数据持久化到硬盘。 - rdbcompression 参数
它的默认值是yes表示开启RDB文件压缩,Redis会采用LZF算法进行压缩。如果不想消耗CPU性能来进行文件压缩的话,可以设置为关闭此功能,这样的缺点是需要更多的磁盘空间来保存文件。 - rdbchecksum 参数
它的默认值为yes表示写入文件和读取文件时是否开启RDB文件检查,检查是否有无损坏,如果在启动是检查发现损坏,则停止启动。
- 如果Redis开启了AOF持久化功能,就会优先使用AOF文件来还原数据库状态,因为AOF文件的更新频率比RDB文件的更新频率高。
- 只有在AOF持久化关闭的状态时,服务器才会使用RDB文件来还原数据库状态。
- 服务器在载入RDB文件期间,会一直处于阻塞状态,直到载入工作完成为止。
- 优点:RDB文件时一个紧凑的二进制文件,适用备份、全量复制的场景。加载RDB文件恢复数据远远快于AOF文件。
- 缺点:不能实时持久化,数据丢失的风险高。每次BGSAVE创建子进程属于重量级操作,频繁执行成本高。
AOF
- AOF(Append Only File)持久化以独立日志方式记录每次写命令,重启时在重新执行AOF文件中的命令达到恢复数据的目的。
- AOF的主要作用就是解决了数据持久化的实时性。
- 被写入AOF文件的所有命令都是以Redis的命令请求协议格式保存的,因为Redis命令请求协议格式是纯文本格式,所以我们可以直接打开一个AOF文件观察里面的内容。
- 默认情况下AOF功能是关闭的。我们需要修改配置文件:
appendonly no改为appendonly yes。
- 命令追加:服务器执行完一个写命令后,会以协议格式将被执行的写命令追加到服务器状态的aof_buf缓冲区末尾。
- 文件同步:AOF缓冲区根据对应的策略向硬盘做同步操作。
- 文件重写:随着AOF越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
- 重启加载:当Redis重启时,可以加载AOF文件进行数据恢复。
- appendfsync always:每次写入都要同步AOF文件,从效率上看,是最慢的,从安全性上看,是最安全的。
- appendfsync everysec:每1秒钟同步一次,该策略为AOF的缺省策略。
- appendfsync no:从不同步。高效但是数据不会被持久化。
Redis明明是单线程,为什么性能还那么高?
- 纯内存访问,Redis将所有数据放在内存中,内存响应的速度非常快。
- 非阻塞I/O,Redis使用epoll作为I/O多路复用技术的实现的,再加上Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多事件。
- 单线程避免了线程切换和竞态产生的消耗。
- 单线程可以简化数据结构和算法的实现。
- 单线程可以避免竞态产生的消耗,锁和线程切换通常是性能杀手。
- 对于每个命令的执行时间有要求,如果某个命令执行过长,会造成其他命令阻塞,对于Redis这种高性能的服务来说是致命的。
Redis流水线(管道)
- 以前我们每向Redis服务器发送一个命令的时候,Redis服务器就会执行该命令,然后返回结果给客户端。每一次请求与响应都会消耗一些时间,由于Redis读写速度很快,所有一旦接收到客户端发来的命令,就会立即执行并返回结果。
- 如果在网络差的情况下,客户端发送命令给服务器需要一些时间,此时Redis服务器一直等待命令的到来,这个原因不是Redis的问题,而是网络差的问题,如果一次性需要发送上百条命令,都会出现上述原因,那么效率是非常差的,所有Redis提供了一个流水线技术,也叫管道,就是能在一次连接上,执行大量的命令,减少客户端与服务器的来回交互次数,大大提升效率。

- 使用Java Jedis模拟批量插入100W条数据时,不使用与使用流水线技术的差距。
@Test public void pipeline(){ Jedis jedis = new Jedis("localhost",6379); //获取流水线 Pipeline pipelined = jedis.pipelined(); //获取开始执行时间 long startTime = System.currentTimeMillis(); IntStream.range(0,1000000).forEach(it -> pipelined.set("batch"+it,it+"")); List<Object> list = pipelined.syncAndReturnAll(); //获取执行完毕时间 long endTime = System.currentTimeMillis(); System.out.println(endTime - startTime); } 耗时:3551毫秒,3秒多@Test public void set(){ Jedis jedis = new Jedis("localhost",6379); long startTime = System.currentTimeMillis(); IntStream.range(0,1000000).forEach(it -> jedis.set("setBatch"+it,it+"")); long endTime = System.currentTimeMillis(); System.out.println(endTime - startTime); } 耗时:71948毫秒,71秒多
流水线总结
从上面两个程序来看。使用流水线与不使用流水线的差距不是一般的大。
- 在一般情况下,用户每执行一个Redis命令,客户端和服务器都需要进行一次通信:客户端向服务器发送命令请求,而服务器则会将执行命令所得的结果返回给客户端。
- 在大多数情况下,执行命令时的绝大部分时间都耗费在发送命令和接收命令回复的过程上,因此减少客户端和服务器之间的通信次数,可以有效提高程序的执行效率。3. 流水线功能可以将多条命令打包一起发送,并且在一次命令恢复中包含所有被执行命令的结果,使用这个功能可以有效提升程序在执行多条命令时的效率。
总结
- Redis进阶篇就介绍完了,大家觉得OK的话,不妨来个👍或者关注也行。

相关文章推荐
- Redis入门、进阶、实战
- Redis 视频教程 大数据 高性能 集群 NoSQL 设计 实战 入门 命令
- Spring Cloud 微服务开发:入门、进阶与源码剖析 —— 11.2 Nacos 服务发现入门实战
- 进阶的Redis之哈希分片原理与集群实战
- Socket网络编程进阶与实战 - Socket TCP快速入门
- 2018年大神带你用Python零基础进阶课程入门爬虫flask实战
- Linux+Redis实战教程_day02_Jedis入门_Redis的数据结构
- Redis入门指南之进阶
- Flutter从入门到进阶实战携程网App
- JavaScript 进阶之 Vue.js + Node.js 入门实战开发
- 2019最新零基础21天搞定Python分布式爬虫(分布式网络爬虫入门进阶项目实战)
- Socket网络编程进阶与实战 - Socket UDP快速入门
- Linux+Redis实战教程_day01_Linux入门_安装jdk、tomcat、mysql
- kubernetes k8s 之入门实战-redis集群
- Spring Cloud 微服务开发:入门、进阶与源码剖析 —— 7.2 技术实战
- oracle dba入门线路图--记某培训公司的ORACLE DBA技能进阶实战大纲
- 云学堂Hadoop大数据工程师零基础入门进阶实战视频课程
- Socket网络编程进阶与实战 - Socket网络编程快速入门
- java入门进阶主流框架学习到架构与电商项目实战
- Flutter从入门到进阶-实战携程网App