牛客 数据库sql实战(每天写十道)
牛客的要比leetcode简单一点,就是题意很模糊,答案判定也感觉乱七八糟,而且没有结果对比,只能用sql写,而且应该从后往前写,后面都是基础知识,基础函数用法,前面是各种表的逻辑思考
很多函数参考:!! https://www.runoob.com/sqlite
q.查找描述信息中包括robot的电影对应的分类名称以及电影数目,而且还需要该分类对应电影数量>=5部
①题目分为两部分,先查出所包含电影数量多于5部的分类,再从这些分类里面查找包含root的电影
② having是先select 在筛选,where是先筛选在select,where中一般不能使用聚合函数,且where后面跟的是数据表中的字段。所以两处一处用了having,一处用了where
select ca.name,count(fc.film_id) from film fi join film_category fc on fi.film_id=fc.film_id join category ca on ca.category_id=fc.category_id join (select category_id from film_category group by category_id having count(film_id)>=5) cc on cc.category_id=fc.category_id where fi.description like '%robot%'
q.获取select * from employees对应的执行计划
explain select * from employees;
explain显示了mysql如何使用索引来处理select语句以及连接表。可以帮助选择更好的索引和写出更优化的查询语句。如果在SELECT语句前放上关键词EXPLAIN,MySQL将解释它如何处理SELECT,提供有关表如何联接和联接的次序。借助于EXPLAIN,可以知道什么时候必须为表加入索引以得到一个使用索引来寻找记录的更快的SELECT。
q.将employees表的所有员工的last_name和first_name拼接起来作为Name,中间以一个空格区分
select last_name||' '||first_name as Name from employees
MySQL、SQL Server、Oracle等数据库支持CONCAT方法,而本题所用的SQLite数据库只支持用连接符号"||"来连接字符串
select CONCAT(last_name," ",first_name) as name from employees
Q.创建表,插入数据
CREATE TABLE IF NOT EXISTS actor (
actor_id smallint(5) NOT NULL PRIMARY KEY,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
last_update timestamp NOT NULL DEFAULT (datetime('now','localtime')))
mysql可以不加as,sqlite3需要加
CREATE TABLE ACTOR_NAME AS SELECT FIRST_NAME,LAST_NAME FROM ACTOR
插入数据是遇到重复数据时忽略
INSERT OR IGNORE INTO ACTOR
VALUES ('3','ED','CHASE','2006-02-15 12:34:33')
Q创建索引
表名(column)中间不能有空格。。
创建唯一索引
CREATE UNIQUE INDEX uniq_idx_firstname ON actor(first_name);
创建普通索引
CREATE INDEX idx_lastname ON actor(last_name);
Q:创建视图
使用视图,可以定制用户数据,聚焦特定的数据,使用视图,基表中的数据就有了一定的安全性因为视图是虚拟的,物理上是不存在的,只是存储了数据的集合,我们可以将基表中重要的字段信息,可以不通过视图给用户,同时,用户对视图,不可以随意的更改和删除,可以保证数据的安全性。
sqlite对大小写敏感,视图列名大小写要和题目要求一致,反正视图列名我一改大写就凉凉
CREATE VIEW actor_name_view as SELECT first_name as first_name_v,last_name as last_name_v FROM actor;
CREATE VIEW <视图名称> (<视图列名1>,<视图列名2>…)
AS
<select 语句>;
CREATE VIEW actor_name_view(first_name_v,last_name_v) as SELECT first_name,last_name FROM actor;
Q:强制使用索引
sqlite: INDEXED BY
SELECT * FROM salaries INDEXED BY idx_emp_no WHERE emp_no=10005;
MYSQL: FORCE INDEX
select * from table_name force index (index_name) where conditions;
ORACLE:没有where 条件过滤是没必要也无法使用索引!
SELECT /*+index(t pk_emp)*/* FROM EMP T WHERE 条件 --强制索引,/*.....*/第一个星星后不能有空格,里边内容结构为:加号index(表名 空格 索引名)。 --如果表用了别名,注释里的表也要使用别名。
Q增加列名
DEFAULT:默认值
ALTER TABLE actor ADD create_date datetime NOT NULL DEFAULT '0000-00-00 00:00:00'
Q构造触发器trigger
https://www.runoob.com/sqlite/sqlite-trigger.html
触发器是自动的。当对表中的数据做了任何修改之后立即被激活.触发器可以通过数据库中的相关表进行层叠修改。触发器可以引用其他表中的列。
SqlServer包括三种常规类型的触发器:DML触发器、DDL触发器和登录触发器。
SqlServer中的DML触发器有三种:
- insert触发器:向表中插入数据时被触发;
- delete触发器:从表中删除数据时被触发;
- update触发器:修改表中数据时被触发。
使用DML触发器:通过数据库中的相关表实现级联更改
DDL触发器是当服务器或者数据库中发生数据定义语言(主要是以create,drop,alter开头的语句)事件时被激活使用,使用DDL触发器可以防止对数据架构进行的某些更改或记录数据中的更改或事件操作。
BEFORE 或 AFTER 关键字决定何时执行触发器动作,决定是在关联行的插入、修改或删除之前或者之后执行触发器动作。当触发器相关联的表删除时,自动删除触发器(Trigger)。要修改的表必须存在于同一数据库中,作为触发器被附加的表或视图,且必须只使用 tablename,而不是 database.tablename。
CREATE TRIGGER trigger_name [BEFORE|AFTER] event_name ON table_name BEGIN -- 触发器逻辑.... END;
WHEN 子句和触发器(Trigger)动作可能访问使用表单 NEW.column-name 和 OLD.column-name 的引用插入、删除或更新的行元素,其中 column-name 是从与触发器关联的表的列的名称。
event_name 可以是在所提到的表 table_name 上的 INSERT、DELETE 和 UPDATE 数据库操作。您可以在表名后选择指定 FOR EACH ROW。
这里的id,name是employees_test中的数据
注意INSERT 后面的ON,以及触发器逻辑最后的;
CREATE TRIGGER audit_log AFTER INSERT ON employees_test BEGIN INSERT INTO audit VALUES(new.ID,new.name); END;
for each row
CREATE TRIGGER trigger_name AFTER UPDATE OF id ON table_1 FOR EACH ROW WHEN new.id>30 BEGIN UPDATE table_2 SET id=new.id WHERE table_2.id=old.id; END;
上面的触发器在 table_1 改 id 的时候如果新的 id>30 就把 表table_2 中和表table_1 id 相等的行一起改为新的 id
列出当前触发器
SELECT name FROM sqlite_master WHERE type = 'trigger';
删除触发器:
DROP TRIGGER trigger_name;
Q:删除特定行
用带有WHERE 子句的 DELETE 查询来删除选定行,否则所有的记录都会被删除。
DELETE FROM table_name WHERE [condition];
DELETE FROM titles_test WHERE id not in (select min(id) from titles_test group by emp_no)
MySQL的UPDATE或DELETE中子查询不能为同一张表,可将查询结果再次SELECT。
DELETE FROM titles_test WHERE id NOT IN ( SELECT * FROM( SELECT MIN(id) FROM titles_test GROUP BY emp_no ) AS a);
mysql:每个派生出来的表都必须有一个自己的别名,t不可少
select * from (select * from list where name="xiao") as t;
Q更新
UPDATE table_name SET column1 = value1, column2 = value2...., columnN = valueN WHERE [condition];
UPDATE titles_test SET to_date=NULL,from_date='2001-01-01' WHERE to_date='9999-01-01'
Q 替换 REPLACE INTO
转自:https://blog.csdn.net/zhangjg_blog/article/details/23267761
replace语句会删除原有的一条记录, 并且插入一条新的记录来替换原记录。
一般用replace语句替换一条记录的所有列, 如果在replace语句中没有指定某列, 在replace之后这列的值被置空 。
replace根据主键确定被替换的是哪一条记录
replace语句不能根据where子句来定位要被替换的记录
如果执行replace语句时, 不存在要替换的记录, 那么就会插入一条新的记录。
如果新插入的或替换的记录中, 有字段和表中的其他记录冲突, 那么会删除那条其他记录。
对于update语句, 因为经常使用到,应该算比较熟悉。 下面对比一下update和replace语句的行为, 只是简单陈述, 不再以具体实例说明。
update语句使用where子句定位被更新的记录;
update语句可以一次更新一条记录, 也可以更新多条记录, 只要这多条记录都复合where子句的要求;
update只会在原记录上更新字段的值, 不会删除原有记录, 然后再插入新纪录;
如果在update语句中没有指定一些字段, 那么这些字段维持原有的值, 而不会被置空;
REPLACE INTO table_name(column_name1,column_name1...) VALUES()
REPLACE INTO titles_test VALUES(5, '10005','Senior Engineer', '1986-06-26', '9999-01-01')
update titles_test set emp_no=replace(emp_no,10001,10005) where id=5
Q:修改表名。列名
sqlite:
修改表名 ALTER TABLE titles_test RENAME TO titles_2017 增加一列 ALTER TABLE table_name ADD COLUMN 列名 数据类型
mysql:
修改表名 ALTER TABLE <旧表名> TO <新表名> 修改列名 ALTER TABLE 表名 CHANGE 列名 新列名 列数据类型
sql sever:
修改表名 EXEC SP_RENAME '原有表名' ,'新表名' 修改列名 EXEC SP_RENAME '表名.[原有列名]' ,'新列名', 'COLUMN'
Q 增加外键约束
两个表中的每一行都有对应,如果在一个表中插入一行另一个表没有显示,可能导致以后应用功能出错,所以为两个表之间增加一个强制约束。
SQL SEVER
给b表增加外键约束,在A B 表之间强制实行一个约束
ALTER TABLE b表名 ADD CONSTRAINT 外键约束名 FOREIGN KEY(b表列名) REFERENCES A(ID) (引用外键表列名)
sqlite:
不能使用alter,只能先删除该表,在重新创建带有外键的表
DROP TABLE audit; CREATE TABLE audit( EMP_no INT NOT NULL, create_date datetime NOT NULL, FOREIGN KEY(EMP_no) REFERENCES employees_test(id));
Q求交集
intersect
SELECT * FROM emp_v intersect select * from employees
Q.针对库中所有表生成select count(*)对应的SQL语句
看题解第一
在 SQLite 系统表 sqlite_master 中可以获得所有表的索引,其中字段 name 是所有表的名字,而且对于自己创建的表而言,字段 type 永远是 ‘table’,详情可参考:
http://blog.csdn.net/xingfeng0501/article/details/7804378
2、在 SQLite 中用 “||” 符号连接字符串
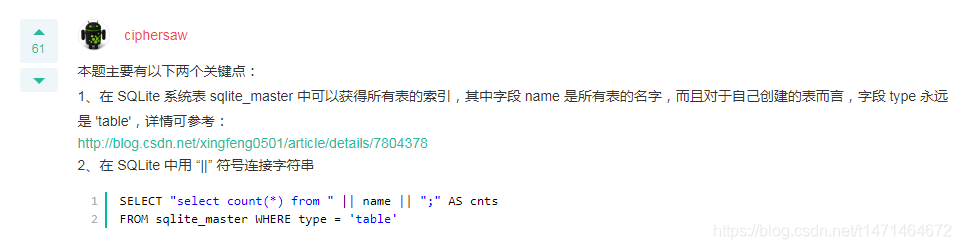
SELECT 'select count(*) from '|| NAME||';' FROM sqlite_master WHERE type='table'
mysql:获得指定数据库的所有表名,db_name是数据库名,information_schema这个是数据系统用来保存数据表的总表
select table_name from information_schema.TABLES where TABLE_SCHEMA='db_name'
Q计算逗号出现次数
看到这题,我的内心都是 小朋友你是否有很多问号
select length('10,A,B')-length(replace('10,A,B',',','')) as cnt
Q截取字符串的字符
substr(字符串,起始位置Y,长度Z)
起始位置:截取的子串的起始位置(注意:字符串的第一个字符的索引是1)。值为正时从字符串开始位置 开始计数,值为负时从字符串结尾位置开始计数。
长度:截取子串的长度
Y是字符串的起始位置(注意第一个字符的位置为1,而不为0),取值范围是±(1~length(X)),当Y等于length(X)时,则截取最后一个字符;当Y等于负整数-n时,则从倒数第n个字符处截取。
Z是要截取字符串的长度,取值范围是正整数,若Z省略,则从Y处一直截取到字符串末尾;若Z大于剩下的字符串长度,也是截取到字符串末尾为止。
select first_name from employees order by substr(first_name,length(first_name)-1)
Q按照dept_no进行汇总,属于同一个部门的emp_no按照逗号进行连接,结果给出dept_no以及连接出的结果employees
group_concat()函数要和group by语句同时使用才能产生效果
group_concat(x[,y])
该函数返回一个字符串,该字符串将会连接所有非NULL的x值。该函数的y参数将作为每个x值之间的分隔符,如果在调用时忽略该参数,在连接时将使用缺省分隔符","。再有就是各个字符串之间的连接顺序是不确定的。
SELECT dept_no, group_concat(emp_no,',') AS employees FROM dept_emp GROUP BY dept_no;
Q exists 用法
EXISTS在SQL中的作用是:检验查询是否返回数据。
select a.* from tb a where exists(select 1 from tb where name =a.name)返回真假,当 where 后面的条件成立,则列出数据,否则为空。
select * from employees e where not exists(select dept_no from dept_emp d where d.emp_no=e.emp_no)
Q对于employees表中,给出按first_name排名的奇数行的first_name
mysql 可以用窗口函数
select t.first_name from (select *,row_number() over(order by first_name) as rank from employees ) t where t.rank%2=1
sqlite(牛客用的)无法用窗口函数
计算在该条记录前面的记录数目,即为该条记录的排名,因为是按照first_name进行排序的,然后答案也没有字母按顺序,所以>=和<=一样通过
select b.first_name from employees b where (select count(*) from employees a where a.first_name <=b.first_name)%2=1
Q:倒数第二题
按照salary的累计和running_total,其中running_total为前两个员工的salary累计和,其他以此类推。当前工资,且按a.emp_no进行分组对salary求和
两种解法
select emp_no,a.salary,(select sum(b.salary) from salaries b where b.emp_no<=a.emp_no and b.to_date='9999-01-01') as running_total from salaries a where a.to_date='9999-01-01'
select a.emp_no,a.salary,sum(b.salary) as running_total from salaries a join salaries b on b.emp_no<=a.emp_no where a.to_date='9999-01-01' and b.to_date='9999-01-01' group by a.emp_no
- 点赞
- 收藏
- 分享
- 文章举报
 咩桃
发布了6 篇原创文章 · 获赞 1 · 访问量 266
私信
关注
咩桃
发布了6 篇原创文章 · 获赞 1 · 访问量 266
私信
关注

- 牛客:数据库SQL实战(一)查询入职最晚的员工的所有信息
- [牛客数据库SQL实战] 21~30题及个人解答
- [牛客数据库SQL实战] 41~50题及个人解答
- [牛客数据库SQL实战] 51~61题及个人解答
- sql 2005数据库加密实战
- 牛客:数据库实战---1---查找最晚入职员工的所有信息、查找入职员工时间排名倒数第三的员工所有信息
- 牛客:数据库实战—2—查找各个部门当前(to_date='9999-01-01')领导当前薪水详情以及其对应部门编号dept_no
- 数据库SQL实战
- 数据库SQL实战
- 实战SQL 2008 数据库镜像功能
- 第73课内幕资料详细版 Spark SQL Thrift Server 实战 每天晚上20:00YY频道现场授课频道68917580
- 数据库整合数据报表SQL实战
- 第76课:Spark SQL基于网站Log的综合案例实战之Hive数据导入、Spark SQL对数据操作每天晚上20:00YY频道现场授课频道68917580
- 数据库专题——SQL语句统计每天、每月、每年的数据
- 综合案例 第80课:Spark SQL网站搜索综合案例实战 以京东找出搜索平台上用户每天搜索排名5名的产品,The hottest!
- 牛客网:数据库sql实战
- 【数据库SQL实战】查找当前薪水详情以及部门编号dept_no
- 数据库SQL实战
- Gradle实战:执行sql操作hive数据库
- 数据库SQL实战