编码总结,以及对BOM的理解
一、前言
在跨平台、跨操作系统或者跨区域之间,经常会涉及到编码的问题,因为前段时间在项目中,遇到了因为编码而产生乱码的问题,以前对编码也是一知半解,所以决定对编码有一个更为深入的了解,因此才有了这篇自己对编码总结的文章。
二、常见编码
1.ASCII:American Standard Code for Information Interchange(美国信息交换标准代码)的缩写,表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符,这应该是我们最先接触的编码。ASCII中
使用一个字节7位二进制数来表示一个字符(最高位用来进行奇偶检验),因为来7个二进制来表示一个字符,最多也就能表示128个字符。其中0~32以及127位用来表示一些特殊的按键或者其他命令,例如回车键、换页键等等,33~47、123~126
和58~64表示一些标点等特殊符号,剩下的是表示26个字母的大小写和阿拉伯数字。这样的话明显不能满足其他不说英文的国家,例如我们中国,ASCII就无法表示汉字,因此就产生其他的编码。
2.gb2312:既然ASCII无法满足我们无法表示汉字,那么我们聪明的中国人就想出了新的方式来表示汉字,因此,gb2312就诞生了。gb2312中的gb是国标的缩写,由中国国家标准总局发布。gb2312中规定一个汉字由2个字节表示,字母、
数字等沿用ASCII中的表示方式,这样就会产生另外一个问题。例如,“希沃”的希对应的gb2312编码是11001111 10100011,假如最高位不为1的话,如01001111 10100011,则无法区分01001111 10100011是表示“希沃”的希还是O和
#,因此规定表示汉字的两个字节的最高位必须为1,“希沃”的希就表示为11001111 10100011,这样就英文和中文就可以统一进行编码了。同时gb2312对汉字进行了分区,统称为区位码。分区是按照汉字的拼音顺序来分区的,每个区包含
16*6,2个字,例如“希沃”的希位于47区第一行第三列,如下图,区位号4703,用二进制表示则为00101111 00000011,ISO2022规定每个汉字的区号和位号必须分别加上32得到交换码,则交换码为01001111 00100011,又根据前面所提
到的表示汉字的两个字节的最高位必须为1,所以最终得到的“希沃”的希的gb2312编码为11001111 10100011.
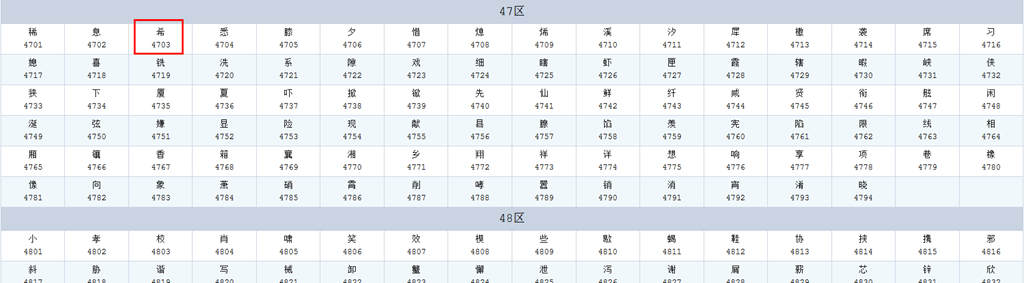
但是一些冷僻字等等没有包含在区位码中,例如“﨡 ”,gb2312无法表示。为了表示这些部分字,国人对交换码进行了扩充(不是区域码),因此,GBK编码诞生了.
3.GBK与GB18030:ASCII是gb2312的一字子集,gb2312是GBK的一个子集,它们是向下兼容的。GBK编码规范跟gb2312一样采用双字节编码,在gb2312的区位码上进行了扩充,gb2312的编码在GBK中还是保持不变。例如“希沃”的希
在gb2312中是11001111 10100011,在GBK中也是11001111 10100011。GBK与gb2312表现出来的最大的区别是它能表示的字符的范围更大,包含繁体字、特殊符号等等,这是因为在GBK中低字节最高位都可能不是1,而gb2312中的高字节与
低字节的最高位都必须为1。GB18030则是对GBK的进一步扩展,其中加入了韩语、蒙语等等。但是世界语言多种多样,GBK和GB18030的通用性范围受到了很大的限制。
4.Unicode:Unicode也是一种字符编码方法,不过它只与ASCII兼容。它是由国际组织设计,可以容纳全世界所有语言文字的编码方案。Unicode的学名是"Universal Multiple-Octet Coded Character Set",简称为UCS。CS只是规定如何
编码,并没有规定如何传输、保存这个编码。例如“希沃”的希字的UCS编码是5E0C,我可以用4个ASCII数字来传输、保存这个编码;也可以用utf-8编码:3个连续的字节E5 B8 8C来表示它。因此UTF家族就出现了,我们所熟悉的UTF-8、
UTF-16、UTF-32等等,其中UTF是“UCS Transformation Format”的缩写。UCS有两种格式UCS-4和UCS-2,顾名思义就是2个字节与4个字节表示,这里只讨论UCS-2(因为目前UCS-4中的前两个字节都为0,即传说中的BMP,去掉前面两个
为0的字节,则为UCS-2)。如下面的表格,UCS-2与UTF-8、UTF-32与UTF-8之间的对应关系。
| UCS-2编码(16进制) | UTF-8 字节流(二进制) |
| 0000 - 007F | 0xxxxxxx |
| 0080 - 07FF | 110xxxxx 10xxxxxx |
| 0800 - FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| UTF-32字节流(二进制) | UTF-8 字节流(二进制) |
| 0x00000000 - 0x0000007F | 0xxxxxxx |
| 0x00000080 - 0x000007FF | 110xxxxx 10xxxxxx |
| 0x00000800 - 0x0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0x00010000 - 0x001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 0x00200000 - 0x03FFFFFF | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 0x04000000 - 0x7FFFFFFF | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
我们可以发现这个IP得分址算法很相似。例如,“希沃”的希5E0C,处于0800 - FFFF之间,采用1110xxxx 10xxxxxx 10xxxxxx,三个字节表示,将0C5E改为二进制为: 1001 1110 0000 1100,将二进制插入模板中,得到11101001 1011
1000 10001100,即E5 B8 8C。UTF-32转换为UTF-8也是通过对应表,以同样的方式进行转换。
5.ANSI:在windows系统中,记事本保存时会默认选择ANSI编码,那ANSI是什么编码呢?ANSI为当前操作系统中的默认编码,例如简体中文操作系统中ANSI为gb2312或GBK,中文繁体操作系统下为big5,日文操作系统下为JIS等。
三、BOM
上面已经提到了gb2312、GBK、UTF-8、UTF-16等编码,那当我将文本选择不同的编码保存后,它们是怎么样进行保存的呢?首先,简单介绍下,big endian和little endian,例如“希沃”的希Unicode编码为5E0C,当我保存希字的时候,
若以5E0C保存,则为big endian,若以0C5E保存,则为little endian。
Unicode规范中推荐的标记字节顺序的方法是BOM(Byte Order Mark),在UCS编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的UTF-16编码是FEFF,UTF-8编码为EF BB BF。而FEFF和EF BB BF在对应的编码中是不存
在的字符,所以不应该出现。在windows中,用记事本保存文件时,可以选择四种编码:ANSI、UTF-8、UTF-16以及UTF-16 big endian,一段文字使用UTF-16编码进行保存时,windows会自动在文件头写入FF FE,若选择UTF-16 big
endian时,windows会自动在文件头写入FE FF,选择UTF-8时会自动写入EF BB BF,选择ANSI时不做任何处理,直接保存。因此,在读取文件时,若文件头出现FF FE时,则文件编码为UTF-16,为FE FF为UTF-16 big endian,为 EF BB BF时
为UTF-8,否则为ANSI,系统默认的编码。
下面我们来验证一下文件是不是这样保存的。


如上图,左图为记事本输入“希沃”两字,“希沃”对应的编码为0C5E,分别以ANSI、UTF-16、UTF-16 BIG ENDIAN、UTF-8进行保存,右图为保存之后对应的十六进制内容。
首先,我们来验证UTF-16编码进行保存时,windows会自动在文件头写入FF FE。在UltraEdit中输入“希沃”两个字,分别选择编码为UTF-16和UTF-16无BOM保存,然后打开文件进行比较,如下图左为内容比较,右图为十六进制比较,
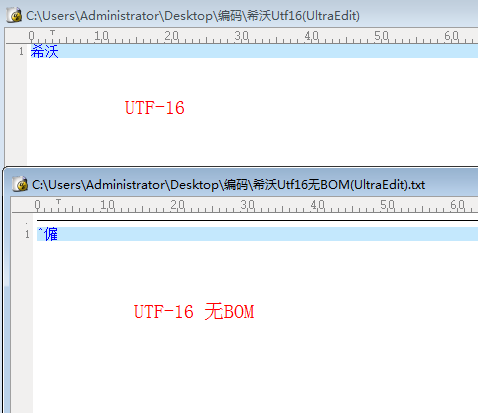
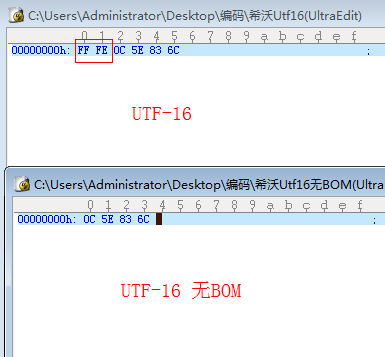
通过比较发现,当选择UTF-16无BOM编码与UTF-16时,在文件开头少了FF FE两个字节,当我们打开编码为UTF-16的文件时,因为文件开头有FF FE两个字节,因此将其当做是UTF-16编码,获取到正确的“希沃”两个字,而当打开文件
编码为UTF-16无BOM的文件时,由于文件开头没有FF FE两个字节以及其他特殊的字节,因此将其打开时,被认为是系统ANSI编码,因此显示为乱码。通过上面的比较我们可以得出:windows在选择UTF-16编码保存文件时,会在文件头写
入FF FE的两个字节。文件开头为FF FE 开头时,会被当做是UTF-16编码来解析。
接下来,我们来验证UTF-8、UTF-16 big endian、ANSI编码是怎样保存的。


从上面两图我们可以看出来,windows在选择UTF-8编码保存文件时,会在文件头写入EF BB BF的三个字节。UTF-16 BIG ENDIAN 会在文件头加入 FE FF两个字节。
综上所述,windows在保存文件时,默认会在文件头写入BOM,UTF-8在文件头写入EF BB BF,UTF-16在文件头写入FF FE,UTF-16 BIG ENDIAN在文件头写入FE FF,ANSI写入BOM。
总结
本章主要是讲述了常见的编码ASCII、gb2312、GBK、UTF-8、UTF-16等编码,以及怎样通过BOM来获取文件的编码。
转载于:https://www.cnblogs.com/ForOne/p/3585101.html
- 点赞
- 收藏
- 分享
- 文章举报
 anjingliao7256
发布了0 篇原创文章 · 获赞 0 · 访问量 105
私信
关注
anjingliao7256
发布了0 篇原创文章 · 获赞 0 · 访问量 105
私信
关注

- 深入理解SD卡基础原理以及内部结构的总结 (转)
- 面向对象的理解以及其原则的总结
- 深入理解ES6箭头函数的this以及各类this面试题总结
- 关于各种输入输出流的二次理解总结 ,以及输入的三种方法总结。
- 【Java基础】Java中的char是否可以存储一个中文字符之理解字符字节以及编码集
- PCA降维算法总结以及matlab实现PCA(个人的一点理解)
- JSP编码以及乱码解决总结
- 理解GC日志以及垃圾收集参数的总结
- PCA降维算法总结以及matlab实现PCA(个人的一点理解)
- 当JSP文件和JS文件编码不一致的问题,以及UTF-8的BOM问题
- 关于各种输入输出流的二次理解总结 ,以及输入的三种方法总结。
- 关于各种输入输出流的二次理解总结 ,以及输入的三种方法总结。
- JSP编码以及乱码解决总结
- 编码与解码的java展示以及乱码的原因总结
- 第十六周总结以及知识理解
- 关于各种输入输出流的二次理解总结 ,以及输入的三种方法总结。
- 关于各种输入输出流的二次理解总结 ,以及输入的三种方法总结。
- 关于UTF-8、GBK编码以及编译时charset的指定的一些总结
- 深入理解计算机系统(3.2)------程序编码以及数据格式
- JSP编码以及乱码解决总结