Docker 网络原理

https://www.cnblogs.com/gaofeng-henu/p/12312672.html
引言
学习docker网络,可以带着下面两个问题来探讨
- 容器之间可以相互访问的原理
- 容器暴露端口后,通过宿主机访问到容器内应用,并且对于访问端而言不用感知容器存在的原理
Docker 本身的技术依赖Linux的内核虚拟化技术,所以为了能够更好的理解Docker的网络实现,必须要对牵扯到的主要技术做些了解
用到的主要Linux技术点
- 网络命名空间(Network Namespace)
- veth设备对
- 网桥 bridge(docker0)
- iptables netfilter
- 路由
网络命名空间
- Linux中为了支持网络协议栈的多个实例,引入了网络命名空间,可以简单理解成相互不干扰、互相隔离的平行网络空间。通过创建不同的网络命名空间,就可以在一台机器上模拟多个不同的网络环境。每个网络命名空间中,都可以有自己独立的路由表,及独立的iptables来提供包转发、NAT等功能。Docker正是利用了网络空间的这个特性,实现容器之间的网络隔离(端口号相互不会冲突)。
网络命名空间的操作(以下命令需要root权限操作)
-
创建命名空间
- 在命名空间中执行命令
- 进入命名空间
- 查看命名空间
- 删除命名空间
ip netns add <name>
例:创建命名空间 netns1
ip netns add netns1
ip netns exec <name> <command>
例:配置netns1中的veth1的地址,并将设备启动
ip netns exec netns1 ip addr add 30.0.0.1/24 dev veth1 ip netns exec netns1 ip link set dev veth1 up
或者
ip netns exec netns1 ifconfig veth1 30.0.0.1/24 up
ip netns exec <name> bash
ip netns list
ip netns delete <name>
veth设备对
veth指虚拟以太网口对(virtual ethernet),只能成对出现,不能单个存在,在Linux术语中把其中一个称为另一个的peer。在Linux中所有的网络设备都只能存在于一个命名空间,物理设备通常只关联到root命名空间中。veth可以通过命令来任意创建和销毁,并可以关联到指定的某个命名空间中,还可以通过命令操作其在不同的命名空间中移动。
前面提到网络命名空间代表的是一个独立的协议栈,相互之间是隔离的,彼此无法直接通信,那如果想在不同的命名空间之间通信,就要用到veth设备对了。他的作用就像是一个管道,一端连着自己的命名空间协议栈,另一端连着另一个命名空间的peer,当veth设备在一端发送数据时,会直接将数据发送给自己的peer,并触发peer接收数据,然后peer把收到的数据再提交到自己的网络协议栈进行处理,从而实现不同协议栈之间的数据传输。Veth的示意图如下:
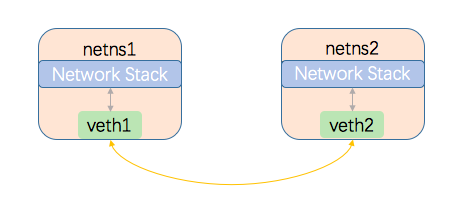
veth设备对的常用操作
-
创建veth设备对
- 查看创建的veth信息
- 将veth移动到特定的网络空间中
ip link add <name1> type veth peer name <name2>
例:创建name分别时veth1和veth2的设备对
ip link add veth1 type veth peer name veth2
ip link show
或者
ip addr
ip link set <vethName> netns <netnsName>
例:将veth1移动到netns1命名空间下
ip link set veth1 netns netns1
实验1
为了验证对网络命名空间和veth设备的理解,我们可以设计下面的场景,来加以证明
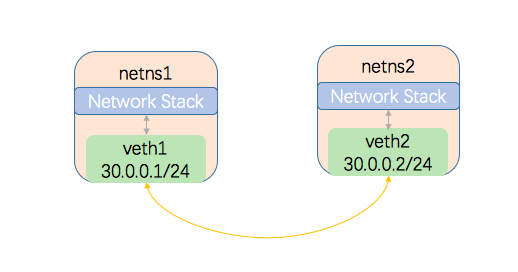
创建两个命名空间,创建一个veth设备对,将设备对分别放到两个命名空间中,给两个veth添加网络地址,从两个命名空间中分别ping对端,彼此能ping通,则说明veth对的确能打破不同命名空间的壁垒,实现通信
创建命名空间
root@chengf:~# ip netns add netns1 root@chengf:~# ip netns add netns2 root@chengf:~# ip netns list netns2 netns1
创建veth设备对
root@chengf:~# ip link add veth1 type veth peer name veth2root@chengf:~# ip link show ... 58: veth2@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether fe:62:b8:f5:4a:68 brd ff:ff:ff:ff:ff:ff 59: veth1@veth2: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 46:69:c0:3f:e2:27 brd ff:ff:ff:ff:ff:ff
将veth设备对分别移到不同的命名空间下,执行移动后,可以看到在root空间下已经没有了刚才创建的veth设备了
root@chengf:~# ip link set veth1 netns netns1 root@chengf:~# ip link set veth2 netns netns2
在对应的命名空间中查看,可以看到veth的确移动到对应的命名空间中
root@chengf:~# ip netns exec netns1 ip link show 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 59: veth1@if58: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 46:69:c0:3f:e2:27 brd ff:ff:ff:ff:ff:ff link-netnsid 1 root@chengf:~# ip netns exec netns2 ip link show 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 58: veth2@if59: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether fe:62:b8:f5:4a:68 brd ff:ff:ff:ff:ff:ff link-netnsid 0
给对应的veth设置网络地址,并且启动veth设备
root@chengf:~# ip netns exec netns1 ip addr add 30.0.0.1/24 dev veth1 root@chengf:~# ip netns exec netns1 ip link set dev veth1 up root@chengf:~# ip netns exec netns2 ip addr add 30.0.0.2/24 dev veth2 root@chengf:~# ip netns exec netns2 ip link set dev veth2 up
通过ip addr 命令产看启动后的设备情况
root@chengf:~# ip netns exec netns1 ip addr 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 59: veth1@if58: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 46:69:c0:3f:e2:27 brd ff:ff:ff:ff:ff:ff link-netnsid 1 inet 30.0.0.1/24 scope global veth1 valid_lft forever preferred_lft forever inet6 fe80::4469:c0ff:fe3f:e227/64 scope link valid_lft forever preferred_lft forever root@chengf:~# ip netns exec netns2 ip addr 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 58: veth2@if59: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether fe:62:b8:f5:4a:68 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 30.0.0.2/24 scope global veth2 valid_lft forever preferred_lft forever inet6 fe80::fc62:b8ff:fef5:4a68/64 scope link valid_lft forever preferred_lft forever
在两个命名空间中相互ping对方
root@chengf:~# ip netns exec netns1 ping -c 1 30.0.0.2 PING 30.0.0.2 (30.0.0.2) 56(84) bytes of data. 64 bytes from 30.0.0.2: icmp_seq=1 ttl=64 time=0.125 ms --- 30.0.0.2 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.125/0.125/0.125/0.000 ms root@chengf:~# ip netns exec netns2 ping -c 1 30.0.0.1 PING 30.0.0.1 (30.0.0.1) 56(84) bytes of data. 64 bytes from 30.0.0.1: icmp_seq=1 ttl=64 time=0.084 ms --- 30.0.0.1 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.084/0.084/0.084/0.000 ms
可以看到通过veth设备对,的确能够在不同的命名空间之间相互访问,由于veth只能是一对一的,那我们有多个命名空间时(两个以上docker容器),怎么相互访问呢,这就是网桥(bridge)的功能了,结下来再看bridge的基本介绍。
网桥
- Linux网桥的作用类似于物理网络设备中的交换机,是一个工作在二层的虚拟网络设备,有多个端口,数据从多个接口进,也可以从多个接口出,主要作用是把若干个网络接口打通,以使网络接口之间的报文能够相互转发。网桥能够通过MAC地址自动学习,获取到MAC地址和网络接口的关联关系。当受到报文时,首先会解析收到的报文,读取目标MAC地址,通过和自己的MAC记录表对比,来决定转发的目标网络接口。如果能找到MAC地址匹配的接口,就向特定的网络接口转发,否则就将报文广播到所有接口。
- 网桥是建立在从设备的基础上工作的,从设备可以是物理设备,也可以是虚拟设备。当一个设备attach到一个网桥时,就类似于物理交换机上插入了一根网线从而和一个终端设备相连,从而实现连接在bridge上的各个彼此隔离的网络空间相互访问。另外,因为bridge转发是基于目的MAC地址和接口的映射完成的,bridge只要知道attach到自己的设备连接的对端设备的MAC地址就可以了,所以attach到bridge上的设备对应的IP和MAC就没有作用了,实际上这些设备都被bridge一视同仁的当作接口对待,这些设备会被设置成接收任何数据包,最终数据包的处理:接收、转发、丢弃、广播等操作都由bridge来决定。
相比较于传统的交换机,对于接收到的报文要么转发,要么丢弃,运行于Linux内部网络栈里面的网桥,所在的机器本身就是一台主机,有可能就是网络报文的目的地,其收到的报文出了转发和丢弃外,有可能被送到网络协议栈的上层(网络层),从而被自己主机处理。如果给bridge分配一个IP,其他设备在访问bridge时,就可以通过bridge连接的宿主机的网络协议栈来对数据进行处理,所以从这个层面来讲,网桥也可以看作是一个三层设备,其工作示意图如下(图片来自网络):
网桥的常用操作
-
新增一个网桥
- 删除一个网桥(删除前需要先停掉对应的设备)
- 为网桥新加端口
- 给网桥配置IP地址
- 启动网桥设备
- 停止网桥设备
- 查看主机上的网桥
brctl addbr <name>
brctl delbr <name>
brctl addif <brname> <ifname>
例: 将eth0网卡追加到br001
brctl addif br001 eth0
ifconfig <name> <IP>
ifconfig <name> up
ifconfig <name> down
brctl show
实验2
了解过了bridge的基本知识后,我们可以尝试用下面的简单实验来测试bridge的功能
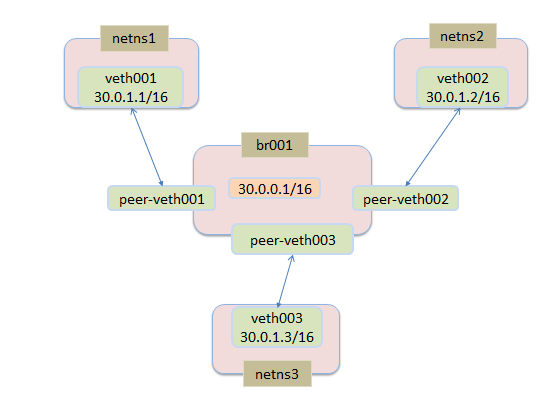
创建三个命名空间,创建三对veth,三对veth中的其中一端分别放在三个命名空间中,另一端都放到网桥br001中,分配好地址空间后,相互能ping通,则证明网桥的确可以实现将数据根据目的发送到不同网络。
创建命名空间
root@chengf:~# ip netns add netns1 root@chengf:~# ip netns add netns2 root@chengf:~# ip netns add netns3 root@chengf:~# ip netns list netns3 netns2 netns1
创建veth对
root@chengf:~# ip link add veth001 type veth peer name peer-veth001 root@chengf:~# ip link add veth002 type veth peer name peer-veth002 root@chengf:~# ip link add veth003 type veth peer name peer-veth003 root@chengf:~# ip link show ... 51: peer-veth001@veth001: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 2e:8b:9e:92:76:28 brd ff:ff:ff:ff:ff:ff 52: veth001@peer-veth001: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 6a:9e:04:44:30:a9 brd ff:ff:ff:ff:ff:ff 53: peer-veth002@veth002: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 56:1f:8e:f5:8b:8c brd ff:ff:ff:ff:ff:ff 54: veth002@peer-veth002: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether f2:1a:b4:54:94:3d brd ff:ff:ff:ff:ff:ff 55: peer-veth003@veth003: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 1a:b9:5f:ab:6a:d2 brd ff:ff:ff:ff:ff:ff 56: veth003@peer-veth003: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 0a:84:78:42:8f:77 brd ff:ff:ff:ff:ff:ff
将veth对中的一端移到对应命名空间中
root@chengf:~# ip link set veth001 netns netns1 root@chengf:~# ip link set veth002 netns netns2 root@chengf:~# ip link set veth003 netns netns3
创建bridge
root@chengf:~# brctl addbr br001 root@chengf:~# ip link show ... 57: br001: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 56:0b:ad:d5:fe:73 brd ff:ff:ff:ff:ff:ff
veth对的另一端attach到bridge
root@chengf:~# brctl addif br001 peer-veth001 root@chengf:~# brctl addif br001 peer-veth002 root@chengf:~# brctl addif br001 peer-veth003 root@chengf:~# ip link show ... 51: peer-veth001@if52: <BROADCAST,MULTICAST> mtu 1500 qdisc noop master br001 state DOWN mode DEFAULT group default qlen 1000 link/ether 2e:8b:9e:92:76:28 brd ff:ff:ff:ff:ff:ff link-netnsid 2 53: peer-veth002@if54: <BROADCAST,MULTICAST> mtu 1500 qdisc noop master br001 state DOWN mode DEFAULT group default qlen 1000 link/ether 56:1f:8e:f5:8b:8c brd ff:ff:ff:ff:ff:ff link-netnsid 3 55: peer-veth003@if56: <BROADCAST,MULTICAST> mtu 1500 qdisc noop master br001 state DOWN mode DEFAULT group default qlen 1000 link/ether 1a:b9:5f:ab:6a:d2 brd ff:ff:ff:ff:ff:ff link-netnsid 4 57: br001: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 1a:b9:5f:ab:6a:d2 brd ff:ff:ff:ff:ff:ff
-
可以看到 br001 对应的mac地址变成了peer-veth003的地址(peer-veth001、peer-veth002、peer-veth003三个中最小的一个)
分别设置netns中的veth设备的IP地址,并启动对应的设备
root@chengf:~# ip netns exec netns1 ifconfig veth001 30.0.1.1/16 up root@chengf:~# ip netns exec netns2 ifconfig veth002 30.0.1.2/16 up root@chengf:~# ip netns exec netns3 ifconfig veth003 30.0.1.3/16 up
-
此时br001还没有分配地址,所以相互是ping不通的
设置bridge的IP地址,并启动bridge
root@chengf:~# ifconfig br001 30.0.0.1/16 up
-
此时再去相互ping,发现还是不能访问,用tcpdump -n -i br001抓包也没有反应,因为我们只是把peer-veth001、peer-veth002、peer-veth003这几个设备attach到br001,但是还没有启动,所以veth设备对还不能正常工作
启动peer设备
root@chengf:~# ip link set dev peer-veth001 up root@chengf:~# ip link set dev peer-veth002 up root@chengf:~# ip link set dev peer-veth003 up
相互访问
root@chengf:~# ip netns exec netns1 ping -c 1 30.0.1.2 PING 30.0.1.2 (30.0.1.2) 56(84) bytes of data. 64 bytes from 30.0.1.2: icmp_seq=2 ttl=64 time=0.249 ms --- 30.0.1.2 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 1027ms rtt min/avg/max/mdev = 0.249/0.325/0.401/0.076 ms root@chengf:~# ip netns exec netns1 ping -c 1 30.0.1.3 PING 30.0.1.3 (30.0.1.3) 56(84) bytes of data. 64 bytes from 30.0.1.3: icmp_seq=1 ttl=64 time=0.472 ms --- 30.0.1.3 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.472/0.472/0.472/0.000 ms root@chengf:~# ip netns exec netns2 ping -c 1 30.0.1.1 PING 30.0.1.1 (30.0.1.1) 56(84) bytes of data. 64 bytes from 30.0.1.1: icmp_seq=1 ttl=64 time=0.219 ms --- 30.0.1.1 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.219/0.219/0.219/0.000 ms root@chengf:~# ip netns exec netns2 ping -c 1 30.0.1.3 PING 30.0.1.3 (30.0.1.3) 56(84) bytes of data. 64 bytes from 30.0.1.3: icmp_seq=1 ttl=64 time=0.389 ms --- 30.0.1.3 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.389/0.389/0.389/0.000 ms root@chengf:~# ip netns exec netns3 ping -c 1 30.0.1.1 PING 30.0.1.1 (30.0.1.1) 56(84) bytes of data. 64 bytes from 30.0.1.1: icmp_seq=1 ttl=64 time=0.194 ms --- 30.0.1.1 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.194/0.194/0.194/0.000 ms root@chengf:~# ip netns exec netns3 ping -c 1 30.0.1.2 PING 30.0.1.2 (30.0.1.2) 56(84) bytes of data. 64 bytes from 30.0.1.2: icmp_seq=1 ttl=64 time=0.216 ms --- 30.0.1.2 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.216/0.216/0.216/0.000 ms
br001上对应的tcpdump信息
21:49:59.741205 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 30.0.1.2 tell 30.0.1.1, length 28 21:49:59.741313 ARP, Ethernet (len 6), IPv4 (len 4), Reply 30.0.1.2 is-at f2:1a:b4:54:94:3d, length 28 21:49:59.741345 IP (tos 0x0, ttl 64, id 14004, offset 0, flags [DF], proto ICMP (1), length 84) 30.0.1.1 > 30.0.1.2: ICMP echo request, id 10633, seq 1, length 64 21:49:59.741526 IP (tos 0x0, ttl 64, id 3913, offset 0, flags [none], proto ICMP (1), length 84) 30.0.1.2 > 30.0.1.1: ICMP echo reply, id 10633, seq 1, length 64 21:50:00.768500 IP (tos 0x0, ttl 64, id 14060, offset 0, flags [DF], proto ICMP (1), length 84) 30.0.1.1 > 30.0.1.2: ICMP echo request, id 10633, seq 2, length 64 21:50:00.768646 IP (tos 0x0, ttl 64, id 3968, offset 0, flags [none], proto ICMP (1), length 84) 30.0.1.2 > 30.0.1.1: ICMP echo reply, id 10633, seq 2, length 64
-
可以看到br001在响应icmp请求前,会通过ARP请求,找到目的IP对应的Mac,之后才会把对应的icmp请求转发到具体地址
- 通过持续在netns3中对30.0.1.1进行ping操作,利用tcpcump持续对br001进行抓包,发现差不多30s,就会发同一个IP发一次ARP包
root@chengf:~# ip netns exec netns1 ping 30.0.1.2 PING 30.0.1.2 (30.0.1.2) 56(84) bytes of data. ^C --- 30.0.1.2 ping statistics --- 13 packets transmitted, 0 received, 100% packet loss, time 12285ms
root@chengf:~# ip netns exec netns1 ping -c 1 30.0.1.2 PING 30.0.1.2 (30.0.1.2) 56(84) bytes of data. --- 30.0.1.2 ping statistics --- 1 packets transmitted, 0 received, 100% packet loss, time 0ms
root@chengf:~# tcpdump -n -vv -i br001 | grep ARP tcpdump: listening on br001, link-type EN10MB (Ethernet), capture size 262144 bytes 22:36:54.364519 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 30.0.1.2 tell 30.0.1.3, length 28 22:36:54.364646 ARP, Ethernet (len 6), IPv4 (len 4), Reply 30.0.1.2 is-at f2:1a:b4:54:94:3d, length 28 22:37:04.604563 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 30.0.1.3 tell 30.0.1.2, length 28 22:37:04.604783 ARP, Ethernet (len 6), IPv4 (len 4), Reply 30.0.1.3 is-at 0a:84:78:42:8f:77, length 28 22:37:28.156545 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 30.0.1.2 tell 30.0.1.3, length 28 22:37:28.156703 ARP, Ethernet (len 6), IPv4 (len 4), Reply 30.0.1.2 is-at f2:1a:b4:54:94:3d, length 28 22:37:33.280248 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 30.0.1.3 tell 30.0.1.2, length 28 22:37:33.280383 ARP, Ethernet (len 6), IPv4 (len 4), Reply 30.0.1.3 is-at 0a:84:78:42:8f:77, length 28 22:37:54.780257 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 30.0.1.3 tell 30.0.1.2, length 28 22:37:54.780418 ARP, Ethernet (len 6), IPv4 (len 4), Reply 30.0.1.3 is-at 0a:84:78:42:8f:77, length 28 22:38:01.948258 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 30.0.1.2 tell 30.0.1.3, length 28 22:38:01.948414 ARP, Ethernet (len 6), IPv4 (len 4), Reply 30.0.1.2 is-at f2:1a:b4:54:94:3d, length 28
iptables 和 Netfilter
在Linux网络协议栈中,在数据包的处理过程中用来对数据包进行过滤、修改、丢弃的技术叫做netfilter和iptables,其中netfilter工作在系统内核中,是利用各种规则真正对数据进行处理的逻辑;而iptables工作在用户空间,提供了丰富的命令行参数,负责协助用户维护、修改netfilter要使用的各种规则表,二者相互配合共同完成Linux对于数据包的各种处理。
在Linux网络协议栈中Netfilter可以参与进去执行动作的点称为挂接点,每个挂接点可以有多个规则,形成链,成为规则链。其中挂接点共有5个(prerouting、input、output、forward、postrouting),相应的规则链也有5个,但是也允许用户建立自己的规则链,并通过在默认的规则链中执行跳转到自定义的规则链中对数据进行处理。
五种挂接点在数据处理过程中的位置如下图所示:
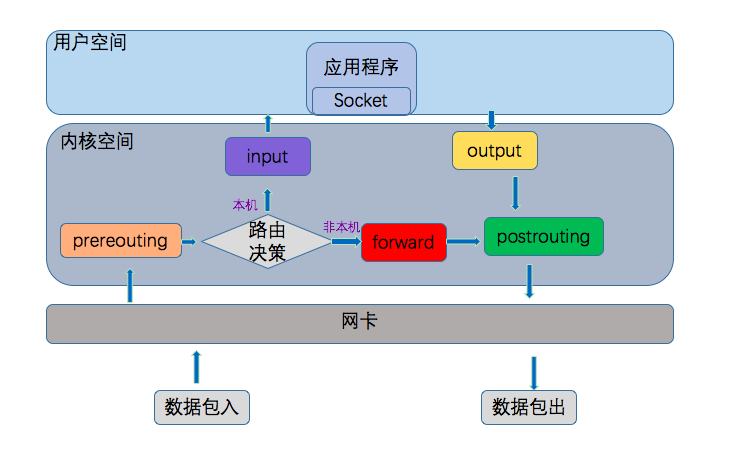
这五种规则链,按照作用分成了四类,存储在Linux的四张表中分别是
-
raw 用来决定是否对一条记录追踪
- mangle 为数据包设置标记(很少用到)
- nat 主要做网络地址转换
- filter 对一条记录进行具体的过滤操作
- 处理规则
规则链中的每一条记录,称为一条规则,每个规则都由如下几部分组成-
表类型 :代表干什么事情
- 什么挂接点 :什么时候起作用
- 匹配的参数是什么 :针对什么样的数据包
- 匹配后的动作 :匹配后具体的操作是什么
- 其中表类型和挂接点已说过,匹配参数主要有以下分类
-
流入、流出的网络接口 (-o -i 参数)
- 来源、目的地址 (-d -s 参数)
- 协议类型 (-p : udp、tcp 参数)
- 来源、目的端口 (--sport、--dport 参数)
- 匹配后的动作
-
ACCEPT(接收)
- DROP(丢弃)
- REJECT(丢弃,必要时会返回调用端一个信息)
- DNAT(目的地址转换,在prerouting阶段,进入路由决策之前,修改目标地址,在路由决策时参与判断的目的地址已经是我们改变后的了。此过程中,源地址不变,并在本机建立NAT表项,当数据返回时,根据NAT表将源地址修改为数据发送过来时的目标地址,并发给远程主机)
- SNAT(源地址转换,在postrouting阶段,经过路由决策之后,在通过本地网络协议栈发送出去之前,重新改写源地址,目标地址不变,并在本机建立NAT表项,当数据返回时,根据NAT表将目的地址数据改写为数据发送出去时候的源地址,并发送给主机)
MSQUERADE(SNAT的一种,但是地址是动态获取发送数据的网卡地址)
例:
下面的例子演示了如下场景,主机192.168.0.102和192.168.0.108在同一个局域网中,其中108机器上运行了一个docker容器,容器中是一个web应用,端口是80,并通过端口映射到108机器的1180机器上,当102机器访问这个web应用时的处理过程如下: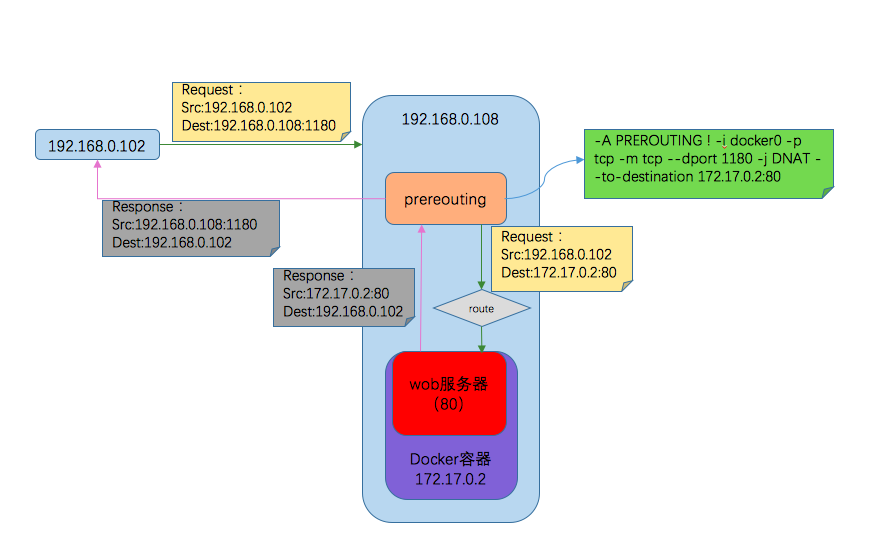
其中在prerouting中的规则:
-A PREROUTING ! -i docker0 -p tcp -m tcp --dport 1180 -j DNAT --to-destination 172.17.0.2:80
表示在prerouting阶段,对于不是从docker0进入的、协议类型是tcp、访问端口是1180的数据包,将目的地址转换成访问172.17.0.2:80。即访问本机1180的请求转换成访问172.17.0.2:80
常用命令
用户配置iptables规则主要用iptables,并且docker或者kubernets在安装和发布容器的过程中会自动帮我们创建很多规则,Linux提供了丰富的参数来控制iptables命令,从而追加不同的规则,可以通过iptables -h 来具体查看。
这里列举几条查看已创建的规则命令iptables-save iptables -n -v -L iptables -n -v -L -t nat
这四种表里面规则的优先级从高到低依次是 raw --> mangle --> nat --> filter
并且这四种表并非都对5个挂接点进行存储,其对应关系如下
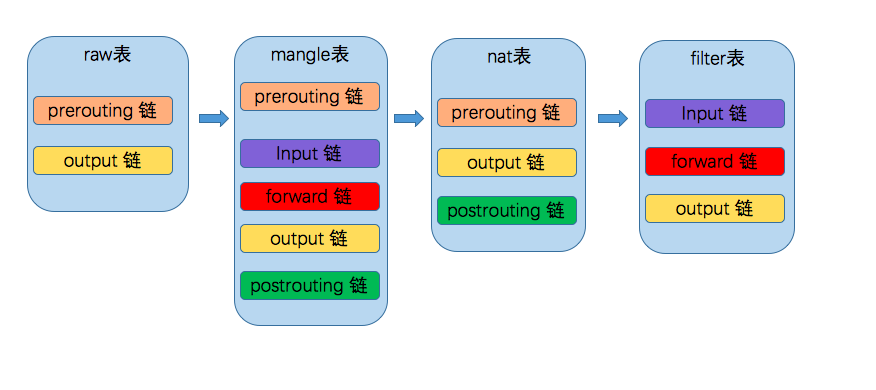
路由
基本概念
在上一章节中,我们知道Linux在收到数据包,执行prerouting后会利用路由决策机制来决定数据包具体是发送网本机或是forward,这时就需要使用到路由功能。
路由功能有IP层维护的路由表来实现,当收到网络侧接收到数据报文时,IP层首先会检查报文的IP地址是不是本机地址,如果时,那么报文会进入传输层相关协议中,如果不是本机的地址,主机将根据路由规则,将数据转发,如果没有匹配的路由规则,数据将会丢弃。
路由表中的数据是以条目形式存在的,一个典型的路由条目通常包含以下几个主要项目:-
目的IP地址:表示目标的IP地址,可以是一个主机的IP地址(标志为H),也可以是网络地址(标志为N)
- 下一个路由器的IP地址
- 标志 H(主机)、G(网关)等
- 网络接口规范:一些数据报文的网络接口规范,这个规范跟随报文一起传播
具体的路由过程如下
首先,路由表会在条目中查找第一个字段(IP地址)与数据报文中目的IP地址完全相同的条目。如果找到,则数据包被发送到条目相应设备或中间路由器。
如果没有找到一个完全的匹配IP,那么就接着搜索相匹配的网络ID,掩码从长到短匹配。如果找到,那么该数据报文会被转发到指定的路由器。这样可以实现这个网络上的所有主机都通过这个路由表中的单个(这个)条目来管理,从而减少路由表的条目数。
如果上述两个条件都不匹配,那么该数据报文将转发到一个“默认路由器”,Genmask(掩码对应的是0.0.0.0)。
如果上述步骤失败,即没有默认路由器,那么该数据报文最终无法被转发。任何无法投递的数据报文都将产生一个ICMP主机不可达或ICMP网络不可达的错误,并将此错误返回给生成此数据报文的应用程序
基本命令
-
查看路由列表
- 追加到特定主机的route
- 追加到某个网络的路由
route -n -v
查看ip v6
route -n -v-6
ip route list
ip route listtable all
route add -host 192.168.0.114 dev eth0
表示到 192.168.0.114主机的数据都经由eth0接口发送
route add -nat 192.168.0.0 netmask 255.255.255.0 dev eth0
Docker 网络
基本概念
标准的docker支持以下4类网络模型
-
host模式
- container模式
- none模式
- bridge模式
其中bridge是默认模式,我们创建容器时,默认不指定时就采用这种模式。所以我们也主要探讨bridge下的docker网络。
在bridge模式下,Docker Daemon第一次启动时会创建一个虚拟的网桥docker0,并从几个备选地址段里给他选择一个地址,一般是172开头,这个地址和主机地址不重叠。之后针对docker创建的每一个容器,都会利用网络命名空间技术,给容器创建一个独立的命名空间,接着会创建一对虚拟的以太设备(veth设备对),其中一端关联到网桥docker0上,另一端再使用Linux的网络命名技术,移动到容器内的网络空间,并修改名称为eth0,然后,从docker0网桥相同的地址段内给eth0接口分配一个IP地址。
bridge模式下的网络模型示意图如下
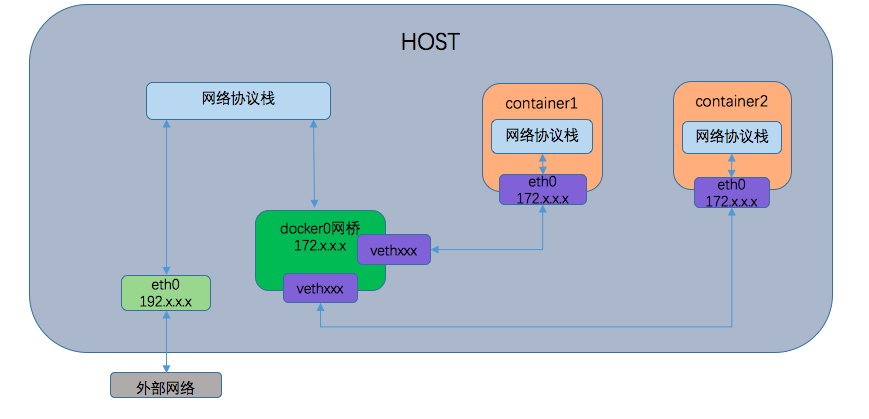
由上图可以看出,容器内的IP默认情况下是不对外部宿主机暴露的,在不通过宿主机影射出去的话,外部机器也无法访问到容器内的应用。
结下来我们通过三种场景下Linux的网络协议栈信息变化来进一步分析docker网络
docker 安装前后
docker 安装前
root@slave:~# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: enp8s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000 link/ether 48:0f:cf:6a:23:fc brd ff:ff:ff:ff:ff:ff 3: wlo1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether c4:8e:8f:d0:33:89 brd ff:ff:ff:ff:ff:ff inet 192.168.0.114/24 brd 192.168.0.255 scope global dynamic noprefixroute wlo1 valid_lft 6415sec preferred_lft 6415sec inet6 fe80::c25:3752:ea14:78dc/64 scope link noprefixroute valid_lft forever preferred_lft forever root@slave:~# iptables-save root@slave:~# route -v -n 内核 IP 路由表 目标 网关 子网掩码 标志 跃点 引用 使用 接口 0.0.0.0 192.168.0.1 0.0.0.0 UG 600 0 0 wlo1 169.254.0.0 0.0.0.0 255.255.0.0 U 1000 0 0 wlo1 192.168.0.0 0.0.0.0 255.255.255.0 U 600 0 0 wlo1
-
wlo1 是宿主机的物理网卡
- 默认情况下iptables中的规则是空的
docker 安装启动后
root@slave:~# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: enp8s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000 link/ether 48:0f:cf:6a:23:fc brd ff:ff:ff:ff:ff:ff 3: wlo1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether c4:8e:8f:d0:33:89 brd ff:ff:ff:ff:ff:ff inet 192.168.0.114/24 brd 192.168.0.255 scope global dynamic noprefixroute wlo1 valid_lft 5916sec preferred_lft 5916sec inet6 fe80::c25:3752:ea14:78dc/64 scope link noprefixroute valid_lft forever preferred_lft forever 4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default link/ether 02:42:8c:7a:a3:9d brd ff:ff:ff:ff:ff:ff inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0 valid_lft forever preferred_lft forever root@slave:~# iptables-save # Generated by iptables-save v1.6.1 on Sun Dec 22 12:18:01 2019 *filter :INPUT ACCEPT [124:8899] :FORWARD DROP [0:0] :OUTPUT ACCEPT [70:7745] :DOCKER - [0:0] :DOCKER-ISOLATION-STAGE-1 - [0:0] :DOCKER-ISOLATION-STAGE-2 - [0:0] :DOCKER-USER - [0:0] -A FORWARD -j DOCKER-USER -A FORWARD -j DOCKER-ISOLATION-STAGE-1 -A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT -A FORWARD -o docker0 -j DOCKER -A FORWARD -i docker0 ! -o docker0 -j ACCEPT -A FORWARD -i docker0 -o docker0 -j ACCEPT -A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2 -A DOCKER-ISOLATION-STAGE-1 -j RETURN -A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP -A DOCKER-ISOLATION-STAGE-2 -j RETURN -A DOCKER-USER -j RETURN COMMIT # Completed on Sun Dec 22 12:18:01 2019 # Generated by iptables-save v1.6.1 on Sun Dec 22 12:18:01 2019 *nat :PREROUTING ACCEPT [11:508] :INPUT ACCEPT [9:428] :OUTPUT ACCEPT [7:491] :POSTROUTING ACCEPT [7:491] :DOCKER - [0:0] -A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER -A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER -A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE -A DOCKER -i docker0 -j RETURN COMMIT # Completed on Sun Dec 22 12:18:01 2019 root@slave:~# route -v -n 内核 IP 路由表 目标 网关 子网掩码 标志 跃点 引用 使用 接口 0.0.0.0 192.168.0.1 0.0.0.0 UG 600 0 0 wlo1 169.254.0.0 0.0.0.0 255.255.0.0 U 1000 0 0 wlo1 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0 192.168.0.0 0.0.0.0 255.255.255.0 U 600 0 0 wlo1
-
docker 安装启动后默认给我们创建了一个docker0的网桥,并赋予了一个172.17.0.1的IP地址。
- 在iptables的filter表中中给我们追加了DOCKER-USER、DOCKER等几个规则链,并将这些规则链放入到默认的FORWARD中,并把FORWARD的默认动作设置成DROP
- 在iptables的nat表中也追加了DOCKER链,并加入到了PREROUTING和OUTPUT链中
在iptables的nat表中的POSTROUTING中追加了如下一条记录
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
表示如果源地址是172.17.0.0/16网段的数据,经过非docker0接口发出去的数据,要把数据包中的源地址修改成发送数据的网卡地址,即从容器中访问外部网络时应该做一次SNAT。路由表中追加了一项
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
当访问目标地址是172.17.0.0/16网段的请求时,使用docker0接口,根据之前讲的网桥的作用,这样,容器之间就可以相互访问了。
启动一个容器(容器无端口映射)
以一个简单的nginx容器为例
slave@slave:~$ docker run -d -it --name nginxfornet nginx:1.9.1 a3b1d91e31ea72420233a8a3bcd1ce0946cee60ce47f2f4004e74103a96098e5 slave@slave:~$ ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: enp8s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000 link/ether 48:0f:cf:6a:23:fc brd ff:ff:ff:ff:ff:ff 3: wlo1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether c4:8e:8f:d0:33:89 brd ff:ff:ff:ff:ff:ff inet 192.168.0.114/24 brd 192.168.0.255 scope global dynamic noprefixroute wlo1 valid_lft 6637sec preferred_lft 6637sec inet6 fe80::c25:3752:ea14:78dc/64 scope link noprefixroute valid_lft forever preferred_lft forever 4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:8c:7a:a3:9d brd ff:ff:ff:ff:ff:ff inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0 valid_lft forever preferred_lft forever inet6 fe80::42:8cff:fe7a:a39d/64 scope link valid_lft forever preferred_lft forever 6: vethf064714@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default link/ether 16:66:c2:9d:e5:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet6 fe80::1466:c2ff:fe9d:e503/64 scope link valid_lft forever preferred_lft forever slave@slave:~$ docker exec -it nginxfornet ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 5: eth0@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever slave@slave:~$ sudo iptables-save # Generated by iptables-save v1.6.1 on Sun Dec 22 21:39:14 2019 *filter :INPUT ACCEPT [40148:56446687] :FORWARD DROP [0:0] :OUTPUT ACCEPT [18377:800696] :DOCKER - [0:0] :DOCKER-ISOLATION-STAGE-1 - [0:0] :DOCKER-ISOLATION-STAGE-2 - [0:0] :DOCKER-USER - [0:0] -A FORWARD -j DOCKER-USER -A FORWARD -j DOCKER-ISOLATION-STAGE-1 -A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT -A FORWARD -o docker0 -j DOCKER -A FORWARD -i docker0 ! -o docker0 -j ACCEPT -A FORWARD -i docker0 -o docker0 -j ACCEPT -A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2 -A DOCKER-ISOLATION-STAGE-1 -j RETURN -A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP -A DOCKER-ISOLATION-STAGE-2 -j RETURN -A DOCKER-USER -j RETURN COMMIT # Completed on Sun Dec 22 21:39:14 2019 # Generated by iptables-save v1.6.1 on Sun Dec 22 21:39:14 2019 *nat :PREROUTING ACCEPT [38:2301] :INPUT ACCEPT [32:1417] :OUTPUT ACCEPT [62:4827] :POSTROUTING ACCEPT [62:4827] :DOCKER - [0:0] -A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER -A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER -A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE -A DOCKER -i docker0 -j RETURN COMMIT # Completed on Sun Dec 22 21:39:14 2019 slave@slave:~$ route -n -v 内核 IP 路由表 目标 网关 子网掩码 标志 跃点 引用 使用 接口 0.0.0.0 192.168.0.1 0.0.0.0 UG 600 0 0 wlo1 169.254.0.0 0.0.0.0 255.255.0.0 U 1000 0 0 wlo1 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0 192.168.0.0 0.0.0.0 255.255.255.0 U 600 0 0 wlo1
通过对比可以看到,启动前后iptables和路由都没有发生变化- 在设备里面追加了vethf064714,这个veth和nginx中的eth0是一对的,并且vethf064714 attach到了docker0这个网桥上
启动一个容器(有端口映射)
还是以nginx为例,把容器内部的80端口,暴露到宿主句的1180上
slave@slave:~$ docker rm -f nginxfornet nginxfornet slave@slave:~$ docker run -d -it --name nginxfornet -p 1180:80 nginx:1.9.1 93b58ae974017b63e6e344ec0f1c4f5e45bbf119146f97422ce04d8b60b68010 slave@slave:~$ ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: enp8s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000 link/ether 48:0f:cf:6a:23:fc brd ff:ff:ff:ff:ff:ff 3: wlo1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether c4:8e:8f:d0:33:89 brd ff:ff:ff:ff:ff:ff inet 192.168.0.114/24 brd 192.168.0.255 scope global dynamic noprefixroute wlo1 valid_lft 6488sec preferred_lft 6488sec inet6 fe80::c25:3752:ea14:78dc/64 scope link noprefixroute valid_lft forever preferred_lft forever 4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:8c:7a:a3:9d brd ff:ff:ff:ff:ff:ff inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0 valid_lft forever preferred_lft forever inet6 fe80::42:8cff:fe7a:a39d/64 scope link valid_lft forever preferred_lft forever 8: veth9e0cff3@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default link/ether 12:9c:31:7b:29:0c brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet6 fe80::109c:31ff:fe7b:290c/64 scope link valid_lft forever preferred_lft forever slave@slave:~$ sudo iptables-save # Generated by iptables-save v1.6.1 on Sun Dec 22 21:41:14 2019 *filter :INPUT ACCEPT [49:3352] :FORWARD DROP [0:0] :OUTPUT ACCEPT [38:5168] :DOCKER - [0:0] :DOCKER-ISOLATION-STAGE-1 - [0:0] :DOCKER-ISOLATION-STAGE-2 - [0:0] :DOCKER-USER - [0:0] -A FORWARD -j DOCKER-USER -A FORWARD -j DOCKER-ISOLATION-STAGE-1 -A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT -A FORWARD -o docker0 -j DOCKER -A FORWARD -i docker0 ! -o docker0 -j ACCEPT -A FORWARD -i docker0 -o docker0 -j ACCEPT -A DOCKER -d 172.17.0.2/32 ! -i docker0 -o docker0 -p tcp -m tcp --dport 80 -j ACCEPT -A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2 -A DOCKER-ISOLATION-STAGE-1 -j RETURN -A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP -A DOCKER-ISOLATION-STAGE-2 -j RETURN -A DOCKER-USER -j RETURN COMMIT # Completed on Sun Dec 22 21:41:14 2019 # Generated by iptables-save v1.6.1 on Sun Dec 22 21:41:14 2019 *nat :PREROUTING ACCEPT [6:216] :INPUT ACCEPT [6:216] :OUTPUT ACCEPT [3:219] :POSTROUTING ACCEPT [3:219] :DOCKER - [0:0] -A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER -A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER -A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE -A POSTROUTING -s 172.17.0.2/32 -d 172.17.0.2/32 -p tcp -m tcp --dport 80 -j MASQUERADE -A DOCKER -i docker0 -j RETURN -A DOCKER ! -i docker0 -p tcp -m tcp --dport 1180 -j DNAT --to-destination 172.17.0.2:80 COMMIT # Completed on Sun Dec 22 21:41:14 2019 slave@slave:~$ route -n -v 内核 IP 路由表 目标 网关 子网掩码 标志 跃点 引用 使用 接口 0.0.0.0 192.168.0.1 0.0.0.0 UG 600 0 0 wlo1 169.254.0.0 0.0.0.0 255.255.0.0 U 1000 0 0 wlo1 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0 192.168.0.0 0.0.0.0 255.255.255.0 U 600 0 0 wlo1
在ip addr和route的输出中和没有暴露端口的结果是一致的在iptables中追加了如下内容
*filter -A DOCKER -d 172.17.0.2/32 ! -i docker0 -o docker0 -p tcp -m tcp --dport 80 -j ACCEPT *nat -A POSTROUTING -s 172.17.0.2/32 -d 172.17.0.2/32 -p tcp -m tcp --dport 80 -j MASQUERADE ... -A DOCKER ! -i docker0 -p tcp -m tcp --dport 1180 -j DNAT --to-destination 172.17.0.2:80
第一条是说,从外部访问IP是172.17.0.2:80的请求是允许的- 第二条表示从172.17.0.2访问172.17.0.2:80的请求,在发出时会做SNAT,把源地址转化成docker0的地址(为啥还有转一次呢?)
- 第三条表示,访问宿主机1180端口的请求,会把目标地址转换成172.17.0.2:80,这样根据route里面的规则,此请求就会通过docker0发出,访问到具体的容器了
通过抓包观察具体的请求
通过在和宿主机(192.168.0.114)在一个局域网里面的另一台机器(192.168.0.109)对宿主机的1180进行访问,并使用tcpdumap工具对wlo1和docker0这两个设备进行抓包,看下请求过程
宿主机物理网卡wlo1
root@slave:~# tcpdump -n -vv -i wlo1 ... 21:46:02.990084 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 192.168.0.1 tell 192.168.0.114, length 28 21:46:02.990605 ARP, Ethernet (len 6), IPv4 (len 4), Reply 192.168.0.1 is-at 9c:21:6a:d7:91:28, length 28 ... 21:46:13.521957 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 192.168.0.114 (c4:8e:8f:d0:33:89) tell 192.168.0.109, length 28 21:46:13.521983 ARP, Ethernet (len 6), IPv4 (len 4), Reply 192.168.0.114 is-at c4:8e:8f:d0:33:89, length 28 ... 21:46:27.345491 IP (tos 0x0, ttl 128, id 4599, offset 0, flags [DF], proto TCP (6), length 60) 192.168.0.109.26999 > 192.168.0.114.1180: Flags [S], cksum 0xb9eb (correct), seq 4049181629, win 8192, options [mss 1460,nop,wscale 8,sackOK,TS val 2543868184 ecr 0], length 0 21:46:27.345597 IP (tos 0x0, ttl 128, id 4600, offset 0, flags [DF], proto TCP (6), length 60) 192.168.0.109.27000 > 192.168.0.114.1180: Flags [S], cksum 0x23d2 (correct), seq 3764470477, win 8192, options [mss 1460,nop,wscale 8,sackOK,TS val 2543868185 ecr 0], length 0 21:46:27.345789 IP (tos 0x0, ttl 63, id 0, offset 0, flags [DF], proto TCP (6), length 60) 192.168.0.114.1180 > 192.168.0.109.26999: Flags [S.], cksum 0x6121 (correct), seq 1260248266, ack 4049181630, win 65160, options [mss 1460,sackOK,TS val 4197603350 ecr 2543868184,nop,wscale 7], length 0 21:46:27.345863 IP (tos 0x0, ttl 63, id 0, offset 0, flags [DF], proto TCP (6), length 60) 192.168.0.114.1180 > 192.168.0.109.27000: Flags [S.], cksum 0x2595 (correct), seq 996708850, ack 3764470478, win 65160, options [mss 1460,sackOK,TS val 4197603350 ecr 2543868185,nop,wscale 7], length 0 ...
192.168.0.114主机会发ARP包查找默认网关的接口位置- 192.168.0.109通过ARP包查找192.168.0.114主机的接口位置
- 192.168.0.109和192.168.0.114建立通信连接,并发送请求
- 192.168.0.114向192.168.0.109返回请求内容
docker0网桥
root@slave:~# tcpdump -n -vv -i docker0 tcpdump: listening on docker0, link-type EN10MB (Ethernet), capture size 262144 bytes ... 21:46:27.345560 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 172.17.0.2 tell 172.17.0.1, length 28 21:46:27.345651 ARP, Ethernet (len 6), IPv4 (len 4), Reply 172.17.0.2 is-at 02:42:ac:11:00:02, length 28 ... 21:46:32.430063 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 172.17.0.1 tell 172.17.0.2, length 28 21:46:32.430161 ARP, Ethernet (len 6), IPv4 (len 4), Reply 172.17.0.1 is-at 02:42:8c:7a:a3:9d, length 28 21:46:27.345676 IP (tos 0x0, ttl 127, id 4599, offset 0, flags [DF], proto TCP (6), length 60) 192.168.0.109.26999 > 172.17.0.2.80: Flags [S], cksum 0xd33e (correct), seq 4049181629, win 8192, options [mss 1460,nop,wscale 8,sackOK,TS val 2543868184 ecr 0], length 0 21:46:27.345684 IP (tos 0x0, ttl 127, id 4600, offset 0, flags [DF], proto TCP (6), length 60) 192.168.0.109.27000 > 172.17.0.2.80: Flags [S], cksum 0x3d25 (correct), seq 3764470477, win 8192, options [mss 1460,nop,wscale 8,sackOK,TS val 2543868185 ecr 0], length 0 21:46:27.345731 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 60) 172.17.0.2.80 > 192.168.0.109.26999: Flags [S.], cksum 0x6d57 (incorrect -> 0x7a74), seq 1260248266, ack 4049181630, win 65160, options [mss 1460,sackOK,TS val 4197603350 ecr 2543868184,nop,wscale 7], length 0 21:46:27.345748 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 60) 172.17.0.2.80 > 192.168.0.109.27000: Flags [S.], cksum 0x6d57 (incorrect -> 0x3ee8), seq 996708850, ack 3764470478, win 65160, options [mss 1460,sackOK,TS val 4197603350 ecr 2543868185,nop,wscale 7], length 0
思考点
- 为什么docker创建的网络命名空间使用ip netns list不能查看到
- 为什么物理网卡没有attach到docker0这个bridge上,容器内部还是能访问宿主机所在的网络
总结
本文通过Linux基本组件veth设备对、bridge、route等几个组件开始,介绍了docker底层实现容器之间访问的实现原理,当然docker容器网络技术栈不仅仅只有bridge,并且在生产环境下也不赞成用bridge默认网桥docker0,通过docker自建网桥还具有服务发现的功能。另外docker swarm模式下还具有overlay、和macvlan等解决方案,功能更强大,当然也更复杂,等后续再进一步研究。文中有不对或理解不当的地方还望各位网友指正。

- “深入浅出”来解读Docker网络核心原理
- Docker 配置Flannel网络过程及原理
- Docker的原生overlay网络的实现原理
- “深入浅出”来解读Docker网络核心原理 推荐
- docker容器网络通信原理分析
- docker容器网络通信原理分析
- docker容器网络通信原理分析
- docker容器网络通信原理分析
- Docker四种网络模式的原理
- Docker 网络背后的原理探索
- docker容器网络通信原理分析
- Docker上的MySQL:MySQL容器的单主机网络
- 神经网络中的BP算法(原理和推导)
- Docker网络(五)--技术流ken
- 网络取证原理与实战
- docker网络链接——容器互联
- [置顶] Android 网络框架之Retrofit2使用详解及从源码中解析原理
- 网络爬虫原理二
- 魅族的手机联系人网络同步功能及原理
- Docker跨主机通信网络