linux搭建zookeeper分布式
一、搭建环境
1.CentOS6.10(最少三台主机,如果机器多,保证主机数量是奇数,我这里就是用三台给大家演示)
2.zookeeper-3.4.6.tar.gz
3.jdk1.8.0_144.tar.gz(zookeeper是运行在jvm虚拟机上的进程)
jdk的环境变量配置不熟悉,参考我搭建hadoop伪分布式里面的步骤
https://blog.csdn.net/qq_44719527/article/details/104560392
4.配置问题和解决方法在文章最后说明
二、搭建步骤
1.将jdk环境变量配置好
2.上传zookeeper压缩包
(1)这里有很多方法,比如建立物理机与虚拟机共享文件夹
或者直接
yum install -y lszrz,其中rz 回车是上传。也可以使用其他远程连接工具,比如 CRT,Xshell等。总之就是将压缩包在物理机导入Linux中放入/opt/software(我存所有tar.gz的目录)

3.解压
(1)
-Cc是大写代表解压到非当前目录,
(2)
/opt/module/是解压目标目录
tar zxvf zookeeper-3.4.6.tar.gz -C /opt/module/

4.更名,因为解压完的带着版本号,对以后操作不方便,所以改一下名称,然后进入zookeeper看一下里面的目录结构
mv zookeeper-3.4.6/ zookeeper

5.在zookeeper目录下创建一个data目录,用来保存zookeeper相关的数据
mkdir data
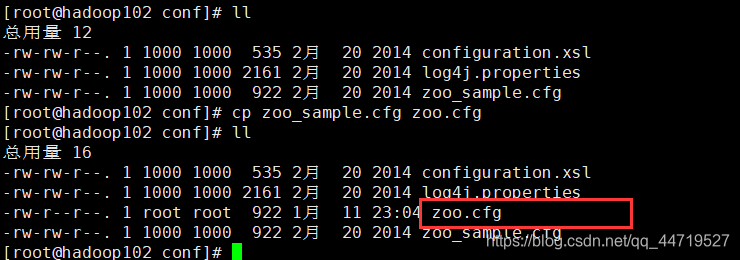
6.进入到zookeeper下的conf目录,将
zoo_sample.cfg文件拷贝一份改名为
zoo.cfg
7.配置
zoo.cfg文件
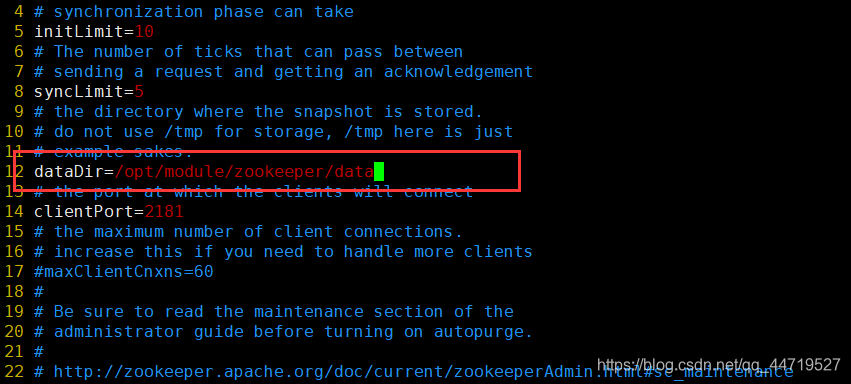
(1)修改dataDir,路径是刚才新建的data目录,不要写错。
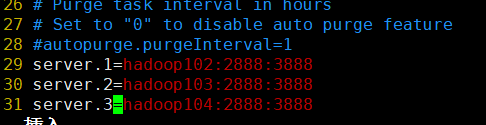
(2)在文件末尾处添加然后保存退出,因为我在/etc/hosts文件里做了主机名和IP映射。所以我这里直接写的主机名。你如果没有做映射,那就写主机的IP地址。
server.1=hadoop102:2888:3888 server.2=hadoop103:2888:3888 server.3=hadoop104:2888:3888
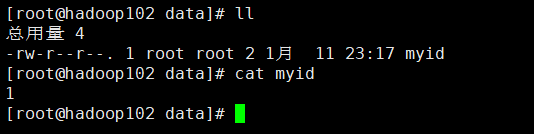
8.在新建的data目录下新建一个文件名为
myid,编辑一个数字1,这个1是与刚才
server.1相对应的,然后保存退出。最好是
cat查看一下,保证创建好。
vim myid
内容就写一个
1

9.将zookeeper这个整体目录拷贝到另外两台主机,两种方式,如果对shell脚本不熟悉的,可以使用第二种方式。但是无论哪种方式都需要输入密码,如果想要不多次输入密码,需要配置ssh免密登录,参考
https://blog.csdn.net/qq_44719527/article/details/104670797
(1)方式一:使用分发脚本,新建一个sync.sh的脚本文件
#!/bin/bash #1 获取输入参数个数,如果没有参数,直接退出 pcount=$# if((pcount==0)); then echo no args; exit; fi #2 获取文件名称 p1=$1 fname=`basename $p1` echo fname=$fname #3 获取上级目录到绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4 获取当前用户名称 user=`whoami` #5 循环 for((host=102; host<105; host++)); do #echo $pdir/$fname $user@hadoop$host:$pdir echo --------------- hadoop$host ---------------- rsync -rvl $pdir/$fname $user@hadoop$host:$pdir done
(2)方式二:使用scp拷贝。
scp -r zookeeper/ root@hadoop103:/opt/module/
10.到目标主机检查确认有没有拷贝或分发成功。
配置免密登录的直接切换
ssh hadoop103 ssh hadoop104

11.更改其他主机的zookeeper下的data目录里的myid文件。原因就是之前在
zoo.cfg里面配置的
server.1和server.2 和server.3每台主机具有唯一的id号而且要与刚才配置饿server后面的数字对应上。
第二台myid内容
2
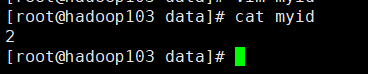 第三台myid内容
第三台myid内容3

三、启动zookeeper集群
1.进入zookeeper目录下,三台做同样操作
bin/zkServer.sh start 开启服务
bin/zkServer.sh status 查看服务状态
bin/zkServer.sh stop 停止服务
bin/zkServer.sh start
2.查看状态,三台状态其中两台是follower,只有一台是leader。
bin/zkServer.sh status



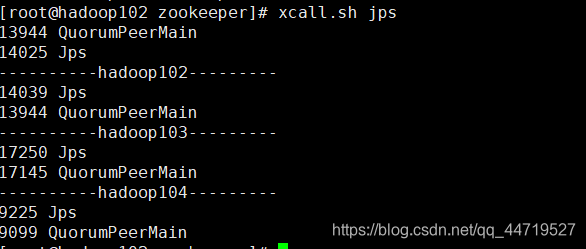
3.使用jps查看jvm虚拟机进程
4.单个启动比较麻烦,可以采用群起脚本,关闭脚本的方式
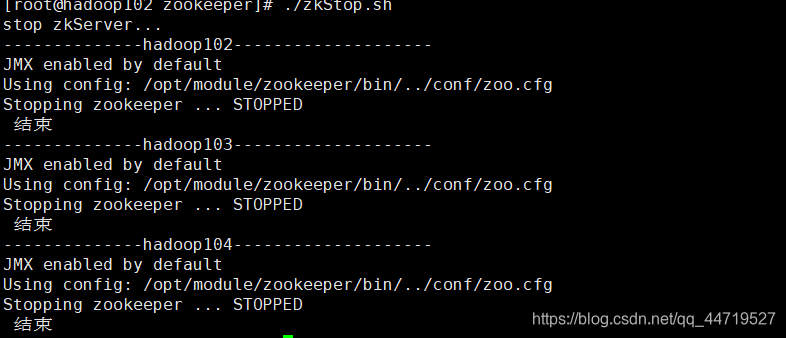
(1)演示一个关闭集群
#!/bin/bash echo "stop zkServer..." for host in 2 3 4 do echo "--------------hadoop10$host--------------------" ssh hadoop10$host "source /etc/profile;/opt/module/zookeeper/bin/zkServer.sh stop" echo "$1 结束" done
配置完成。
四、问题
1.data文件夹里的myid 里的id好一定要保证唯一且与zoo.cfg里的配置相对应上。
2.保证jdk已经配置好。
3.其他问题私信博主
写作不易,如果对您有所帮助,请给一个小小的赞,您的点赞是对我莫大的支持和鼓励,谢谢!!!
- 点赞
- 收藏
- 分享
- 文章举报
 北暖☀
发布了13 篇原创文章 · 获赞 6 · 访问量 639
私信
关注
北暖☀
发布了13 篇原创文章 · 获赞 6 · 访问量 639
私信
关注

- 微信房卡鱼虾蟹平台Linux系统zookeeper环境搭建(单机、伪分布式、分布式)
- 大数据环境完全分布式搭建linux(centos)中安装zookeeper
- linux下zookeeper的安装及dubbo分布式架构的搭建
- Linux下zookeeper单机、伪分布式、分布式环境搭建(本篇主要介绍分布式用于Hadoop高可用集群)
- Linux系统zookeeper环境搭建(单机、伪分布式、分布式)
- zookeeper完全分布式搭建---linux权限的问题
- 【Hadoop2.7.0、Zookeeper3.4.6、JDK1.7】搭建完全分布式的hadoop,HA部署安装,自动备援
- 01_linux下伪分布式环境搭建
- Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境
- windows下单机版的伪分布式solrCloud环境搭建Tomcat+solr+zookeeper
- 搭建3个节点的hadoop集群(完全分布式部署)--3 zookeeper与hbase安装
- linux -- 基于zookeeper搭建yarn的HA高可用集群
- Hadoop-2.7.2&Hbase-1.2.2&Hive1.2.1(远程模式)&zookeeper-3.4.8全分布式环境搭建
- 分布式架构中一致性解决方案——Zookeeper集群搭建
- 一脸懵逼搭建Zookeeper分布式集群
- solr与zookeeper搭建solrcloud分布式索引服务实例
- linux hadoop完全分布式集群搭建图文详解
- windows下单机版的伪分布式solrCloud环境搭建Tomcat+solr+zookeeper
- (3) linux下zookeeper伪集群搭建
- ZooKeeper完全分布式集群搭建