redis高级特性 (性能分析,持久化,主从,哨兵,集群)
文章目录
慢查询
Redis查询指令过程一般如下:

在Redis中当执行时间超过阀值,会将发生时间 耗时 命令记录,此时的慢查询指的是第三阶段执行命令时期。关于慢查询的配置记录可参考慢查询设置,
PS:项目部署前对服务器对redis性能测试很有必要,好好利用redis-benchmark
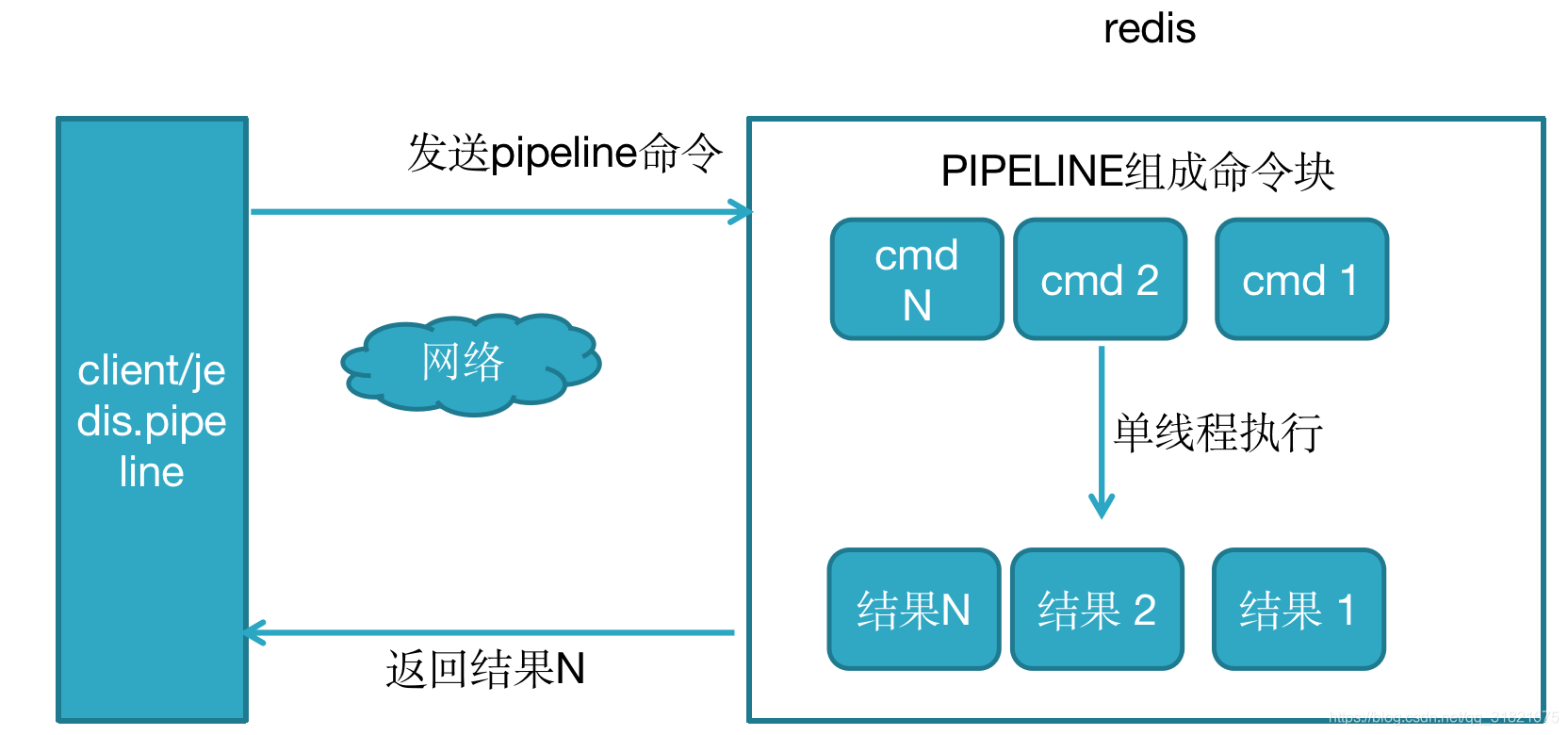
Pipeline
该指令出现的背景:redis客户端执行一条命令分4个过程:
发送命令-〉命令排队-〉命令执行-〉返回结果
这个过程称为Round trip time(简称RTT, 往返时间),mget mset有效节约了RTT,但大部分命令(如hgetall,并没有mhgetall)不支持批量操作,需要消耗N次RTT ,这个时候需要pipeline来解决这个问题
未使用pipeline执行N条指令

使用了pipeline执行N条命令 jedis.pipeline,此处可以懂了RESP手动实现执行流程就很简单了,
性能测试结果:

结论:使用Pipeline执行速度与逐条执行要快,特别是客户端与服务端的
网络延迟越大,性能体能越明显。但是使用pipeline组装的命令个数不能太多,不然数据量过大,增加客户端的等待时间,还可能造成网络阻塞,可以将大量命令的拆分多个小的pipeline命令完成。
mysql数据倒入到Redis
mysql -u用户 -p密码 stress --default-character-set=utf8 --skip-column-names --raw < order.sql |redis-cli -h IP -p 端口 -a 密码 --pipe
order.sql
SELECT CONCAT(
'10\r\n',
'$',LENGTH(redis_cmd),'\r\n',redis_cmd,'\r\n',
'$',LENGTH(redis_key),'\r\n',redis_key,'\r\n',
'$',LENGTH(hkey1),'\r\n',hkey1,'\r\n',
'$',LENGTH(hval1),'\r\n',hval1,'\r\n',
'$',LENGTH(hkey2),'\r\n',hkey2,'\r\n',
'$',LENGTH(hval2),'\r\n',hval2,'\r'
)
FROM(
SELCET
'HSET as redis_cmd,
CONCAT('order:info',orderid) as redis_key,
'ordertime' as hkey1,ordertime as hval1,
'ordermoney' as hkey2,ordermoney as hval2
from ``order
) as t
弱事务性
在Redis中要记住 Redis中原生批命令是原子性,pipeline是非原子性,
原生批命令是服务端实现,而pipeline需要服务端与客户端共同完成。
Redis简单事务:将一组需要一起执行的命令放到multi和exec两个命令之间,其中multi代表事务开始,exec代表事务结束。使用watch后, multi失效,事务失效。
弱事务性测试:



结论:Redis自带的事务性贼鸡肋,用好Redis必须用好Lua。
发布跟订阅
redis提供了“发布、订阅”模式的消息机制,其中消息订阅者与发布者不直
接通信,发布者向指定的频道(channel)发布消息,订阅该频道的每个客
户端都可以接收到消息。不过比专业的MQ(RabbitMQ RocketMQ ActiveMQ Kafka)相比不值一提,这个功能就别用了。。。

Redis持久化原理剖析
redis是一个支持持久化的内存数据库,也就是说redis需要经常将内存中的数据同步到磁盘来保证持久化,持久化可以避免因进程退出而造成数据丢失。
RBD持久化
RDB:把当前进程数据生成快照(.rdb)文件保存到硬盘的过程。
手动触发有save和bgsave两命令
- save命令:阻塞当前Redis,直到RDB持久化过程完成为止,若内存实例比较大会造成长时间阻塞,线上环境不建议用它
- bgsave命令:redis进程执行fork操作创建子线程,由子线程完成持久化,阻塞时间很短(微秒级),是save的优化,在执行redis-cli shutdown关闭redis服务时,如果没有开启AOF持久化,自动执行bgsave;

自动触发就是在redis配置文件中
save 900 1 save 300 10 save 60 10000
那么只要满足以下三个条件中的任意一个,BGSAVE 命令就会被执行:
- 服务器在 900 秒之内,对数据库进行了至少 1 次修改
- 服务器在 300 秒之内,对数据库进行了至少 10 次修改
- 服务器在 60 秒之内,对数据库进行了至少 10000 次修改
优点:
- 压缩后的二进制文,适用于备份、全量复制,用于灾难恢复
- 加载RDB恢复数据远快于AOF方式
缺点:
- 无法做到实时持久化,每次都要创建子进程,频繁操作成本过高
- 保存后的二进制文件,存在老版本不兼容新版本rdb文件的问题
AOF持久化
redis 针对RDB不适合实时持久化,redis提供了AOF持久化方式来解决,底层原理就是将所有涉及到增删到RESP指令全部写到
appendonly.aof文件中,恢复到时候将全部指令执行一遍。
开启:redis.conf设置:appendonly yes (默认不开启,为no)
默认文件名:appendfilename “appendonly.aof”
AOF流程:
- 所有的写入命令(set hset)会append追加到aof_buf缓冲区中
- AOF缓冲区向硬盘做sync同步
- 随着AOF文件越来越大,需定期对AOF文件rewrite重写,达到压
- 当redis服务重启,可load加载AOF文件进行恢复

重要指令详解
- appendonly yes //启用aof持久化方式
- appendfsync always //每收到写命令就立即强制写入磁盘,最慢的,但是保证完全的持久化,不推荐使用
- appendfsync everysec //每秒强制写入磁盘一次,性能和持久化方面做了折中,推荐
- appendfsync no //完全依赖os,性能最好,持久化没保证(操作系统自身的同步)
- no-appendfsync-on-rewrite yes //正在导出rdb快照的过程中,要不要停止同步aof
- auto-aof-rewrite-percentage 100 //aof文件大小比起上次重写时的大小,增长率100%时,重写
- auto-aof-rewrite-min-size 64mb //aof文件,至少超过64M时,重写
优点:
AOF持久化方式相比于RDB来说,可读性高(保存的是代码,可读性好),适合保存增量数据,数据不易丢失。
ps:为什么数据不容易丢失?因为数据被保存在内存中的AOF缓冲区中,数据不易丢失。
缺点:
保存基本上所有redis除读之外的代码,保存的文件大,恢复数据需要重写执行所有的代码,恢复的时间长
RDB和AOF恢复顺序
redis重启恢复数据时流程如下:
- 当AOF和RDB文件同时存在时,优先加载AOF
- 若关闭了AOF,加载RDB文件
- 加载AOF/RDB成功,redis重启成功
- AOF/RDB存在错误,启动失败打印错误信息

主从复制
和Mysql主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况。为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步,一般主节点负责写数据,从节点负责读数据。
整体图如下:

注意传输延迟性,主从一般部署在不同机器上,复制时存在网络延时问题,redis提供repl-disable-tcp-nodelay参数决定是否关闭TCP_NODELAY,默认为关闭
- 参数关闭时:无论大小都会及时发布到从节点,占带宽,适用于主从网络好的场景,
- 参数启用时:主节点合并所有数据成TCP包节省带宽,默认为40毫秒发一次,取决于内核,主从的同步延迟40毫秒,适用于网络环境复杂或带宽紧张,如跨机房
一主一从:
用于主节点故障转移从节点,当主节点的且需要持久化写命令并发高,可以只在从节点开启AOF(主节点不需要)

一主多从:
针对读较多的场景,“读”由多个从节点来分担,但节点越多,主节点同步到多节点的次数也越多,影响带宽,也加重主节点的稳定。

树状主从:
一主多从的缺点(主节点推送次数多压力大)可用些方案解决,主节点只推送一次数据到从节点B,再由从节点B推送到D和E,减轻主节点推送的压力

复制原理
先启动master然后启动若干slave,可以用info replication 查看主从及同步信息。
redis 2.8版本以上使用psync命令完成同步,过程分“全量”与“部分”复制
全量复制:
一般用于初次复制场景(第一次建立SLAVE后全量)
部分复制:
网络出现问题,从节点再次连主时,主节点补发缺少的数据,每次数据增加同步
心跳:
主从有长连接心跳,主节点默认每10S向从节点发ping命令,repl-ping-slave-period控制发送频率
后台同步原理:
- 保存主节点信息
- 主从建立socket连接
- 发送ping命令
- 权限验证
- 同步数据集
- 命令持续复制
哨兵机制
前面的主从复用配置文件启动很简单,问题是如何实现高可用,master 停止后可自动切换到slave节点。

Redis Sentinel
高可用:当主节点出现故障时,由Redis Sentinel自动完成故障发现和转移,并通知应用方,实现高可用性。

哨兵有三个定时监控任务完成对各节点的发现和监控,主要是循环性到监控master跟slave

下线的时候分为主观下线和客观下线。
主观下线:单独一个哨兵发现master故障了。
客观下线:多个哨兵进行抉择发现达到quorum数时候开始进行切换。
哨兵选举规则
大部分情况下都是那个哨兵发现master了就会成为领导者负责节点切换工作。

故障转移流程
故障转移流程A
sentinel会向master发送心跳PING来确认master是否存活,如果master在“一定时间范围”内不回应PONG 或者是回复了一个错误消息,那么这个sentinel会主观地(单方面地)认为这个master已经不可用了。

故障转移流程B
当主节点出现故障,此时假设3个Sentinel节点共同选举了Sentinel3节点为领导者sentinel,负载处理主节点的故障转移。

故障转移流程C
由Sentinel3领导者节点执行故障转移,过程和主从复制一样,但是自动执行。

故障转移后的拓扑结构图D

故障转移大致流程

部署建议
- sentinel节点应部署在多台物理机(线上环境)
- 至少三个且奇数个sentinel节点
- 三个sentinel可同时监控一个主节点或多个主节点,当监听N个主节点较多时,如果sentinel出现异常,会对多个主节点有影响,同时还会造成sentinel节点产生过多的网络连接,一般线上建议还是, 3个sentinel监听一个主节点
最后客户端通过JedisSentinelPool 来操作即可啦。。。
集群
RedisCluster是Redis的分布式解决方案,在3.0版本后推出的方案,有效地解决了Redis分布式的需求,当遇到单机内存、并发等瓶颈时,可使用此方案来解决这些问题,关于集群的搭建也推荐看下此文。
Redis分布式概念:
比如我们库有900条用户数据,有3个redis节点,将900条分成3份,分别存入到3个redis节点

分区规则
常见的分区规则
- 节点取余
hash(key) % N
- 一致性哈希
一致性哈希环
- 虚拟槽哈希
CRC16[key]&16383
RedisCluster采用了哈希分区的“虚拟槽分区”方式(哈希分区分节点取余、一致性哈希分区和虚拟槽分区)
虚拟槽分区
槽:slot,RedisCluster采用此分区,所有的键根据哈希函数(CRC16[key]&16383)映射到0-16383槽内,共16384个槽位,每个节点维护部分槽及槽所映射的键值数据。
哈希函数:
Hash()=CRC16[key]&16383

此时KV存储规则如下:

- 键的批量操作支持有限,比如mset, mget,如果多个键映射在不同的槽,就不支持了 mset name james age 19
- 键事务支持有限,当多个键分布在不同节点时无法使用事务,同一节点是支持事务
- 键是数据分区的最小粒度,不能将一个很大的键值对映射到不同的节点
- 不支持多数据库,只有0,select 0
- 复制结构只支持单层结构,不支持树型结构。
关于集群的创建 百度上搜索即可。按照教程来不难。
集群通讯Gossip协议
Gossip协议的主要职责就是信息交换,信息交换的载体就是节点之间彼此发送的Gossip消息,常用的Gossip消息有ping消息、pong消息、meet消息、fail消息
- meet消息:用于通知新节点加入,消息发送者通知接收者加入到当前集群,meet消息通信完后,接收节点会加入到集群中,并进行周期性ping pong交换
- ping消息:集群内交换最频繁的消息,集群内每个节点每秒向其它节点发ping消息,用于检测节点是在在线和状态信息,ping消息发送封装自身节点和其他节点的状态数据;
- pong消息,当接收到ping meet消息时,作为响应消息返回给发送方,用来确认正常通信,pong消息也封闭了自身状态数据;
- fail消息:当节点判定集群内的另一节点下线时,会向集群内广播一个fail消息
集群重定向

不难理解:redis通过集群的搭建实现了多个master 的共同工作,然后在不同的master 下面还创建了slave节点来实现集群的高可用,当有某个主节点故障后会有节点迅速补上来。并且可以实现动态的增删master。
最后 Java操作redis集群的时候通过JedisPool 来操作rediscluster池就OK咯哦!不过在SpringBoot中底层都已经帮我们封装好咯。我们简单设置几步就OK了,看参考文档即可。
参考
rdb持久化
主从笔记
主从,持久化,哨兵
java客户端Jedis操作Redis Sentinel 连接池
一致性哈希
rediscluster下集群应用-rediscluster连接池实现
springBoot整合redisCluster
windows上Redis集群搭建
- 点赞 13
- 收藏
- 分享
- 文章举报
 SoWhat1412
博客专家
发布了347 篇原创文章 · 获赞 1996 · 访问量 156万+
他的留言板
关注
SoWhat1412
博客专家
发布了347 篇原创文章 · 获赞 1996 · 访问量 156万+
他的留言板
关注

- Redis基础、高级特性与性能调优-redis的持久化
- Redis学习笔记(4)-持久化、主从配置、哨兵、集群配置
- redis主从集群搭建及容灾部署(哨兵sentinel)
- 分布式缓存技术redis学习系列(三)——redis高级应用(主从、事务与锁、持久化)
- redis学习系列(一)--redis主从,哨兵,集群
- redis源码分析(一)复习redis命令、持久化方案、主从同步原理、配置
- Redis实战《红丸出品》4.2 Redis高级实用特性之主从复制
- Redis学习记录2(消息队列,主从复制,哨兵,集群)
- Redis基础、高级特性与性能调优-pilelining,事务,scripting
- Redis进阶实践(三)——redis高级应用(主从、事务与锁、持久化)
- Redis基础、高级特性与性能调优
- Redis集群性能问题深度分析
- Redis基础、高级特性与性能调优-内存管理与数据淘汰机制
- Redis 基础、高级特性与性能调优
- 《MySQL技术精粹:架构、高级特性、性能优化与集群实战》目录
- Redis实战《红丸出品》4.4 Redis高级实用特性之持久化机制
- 分布式缓存技术redis学习系列(三)——redis高级应用(主从、事务与锁、持久化)
- Redis主从集群搭建及容灾部署(哨兵sentinel)
- Redis高级实用特性(安全性、主从复制、事务处理)
- redis高级特性之主从复制