Flume也扛不住的千亿级数据,OPPO如何靠自研提升 - 大数据
ESA DataFlow是由OPPO互联网自研的一款高性能的数据流采集、聚合和传输框架,单节点的日均处理数据量超过百亿条。相较Flume在运维可视化、路由、并行处理能力等方面有较大的提升。
二、基本概念
ESA DataFlow是一款高性能数据流处理框架,它具有:
-
消息路由:灵活的路由规则,把消息分发到不同的通道处理。
-
高性能:单节点具备日处理100亿以上条数据能力。易扩展:内置常用Source、Sink,Channel开发者可灵活自定义扩展Source、Channel、Sink,也可自定义序列化方式。
-
监控运维:内置管理控制台,能实时查看数据输入、缓冲以及消费速率等各项数据统计。
其内部结构如下:
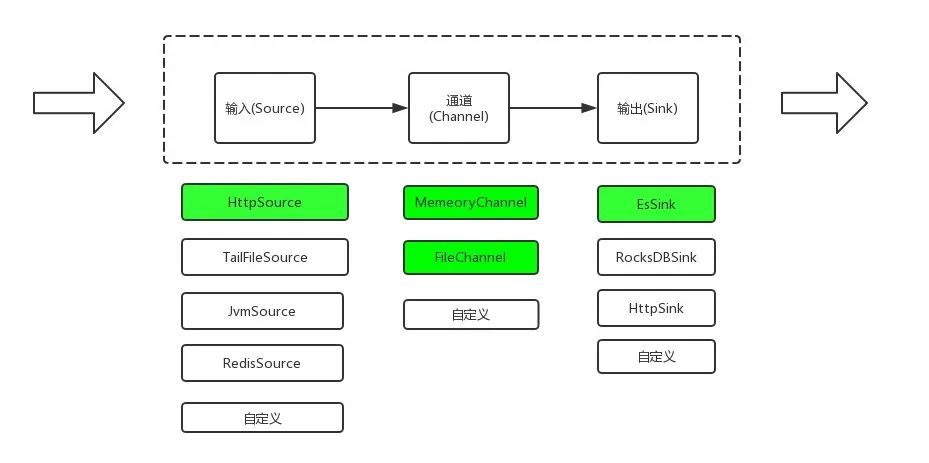
1、DataEvent
DataEvent是DataFlow端到端传输的基本单元,它由body和headers信息构成,由K-V构成的Map信息,主要用于数据信息的传递。
private Map<String, String> headers = new HashMap<>();
private List<T> body = new ArrayList<>();
Source
它是数据源,从特定通道(如Http)接受数据,把消息路由分发到Channel中。开发者通过继承SourceBase实现Source的功能。
2、Channel
它缓存接收到的DataEvent直到它们被所有Sink节点消费完成,Channel传输时需要序列化及反序列化,默认采用的是Kryo,开发者可以根据实际情况使用其它序列化方式,如protobuf。开发者通过继承ChannelBase实现Channel的功能以及序列化和反序列化。
3、Sink
它主要从Channel中获取数据,将数据传输到下一个目的地,如Elasticsearch、RocksDB。一个Sink有且只有一个Channel。开发者通过继承SinkBase实现Sink的功能。
三、框架的演进
我们最初的需求是能够接收大流量和高并发的数据采集框架,并且具有良好的扩展性。于是我们有了最初版本:
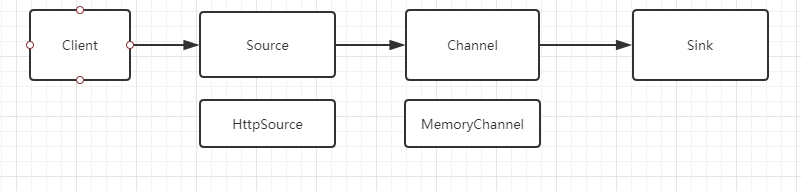
DataFlow框架分三层,类似Flume的Source、Channel和Sink概念。
我们开发了最初的扩展:HttpSource、MemoryChannel,Sink的扩展则由开发者根据业务需求定制。
1)Http Source
DataFlow内置HttpSource实现,它是基于Netty实现的高性能HttpServer。在500线程下(4c8g,cpuload 99%),请求数据大小为1kb,平均TPS达到13w/s。
2)Memory Channel
内存队列,基于Java内置的BlockingQueue实现。使用时需控制队列数量及对象大小,数据量过大时容易造成进程OOM,重启时则数据丢失。
HttpSource采用Netty实现的Http服务以及Memory Channel使用内存队列实现的Channel满足了高性能和高并发的要求,但是Memory Channel在进程重启时,如果数据没有被消费完,则Channel中的数据丢失,这又使得可靠性得不到很好的保证。于是我们有了FileQueue Channel:
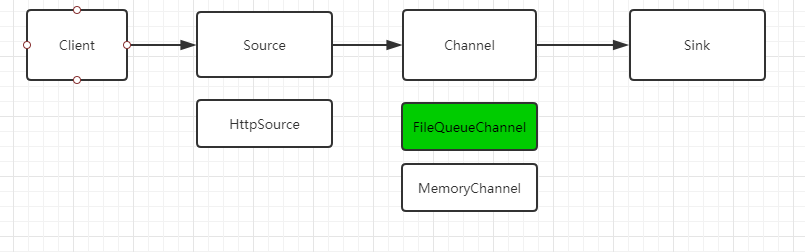
3)FileQueue Channel
文件队列,采用基于mmap实现的文件队列的方式 ,保证了数据的本地持久化,进程crash及重启时数据不丢失。但如所在服务器异常关机时,则可能丢失page-cache里面缓存的数据。相比传统的I/O读写,mmap大大提高了读写效率,从而保证了Channel数据传输极高的吞吐量。
特别是在日志采集和调用链采集业务的应用上,FileQueue的Channel扩展,在线上可靠性和吞吐量之间取得了平衡,业务的特殊性可以容忍在极端异常情况下,少量数据的丢失(服务器掉电、异常重启等)。当然mmap也支持强制刷盘的方式,但是读写效率也会因此大打折扣,没有充分利用mmap带来的好处。
1、并行处理
随着业务的深入迭代,FileQueueChannel 在大规模使用的同时,Channel与Sink一一对应的模式使得业务不能有更加灵活的扩展。比如日志告警和日志存储,如果都放到一个Sink中处理,使得业务逻辑变得耦合。
实际情况可能更加糟糕:在日志的后端存储异常时,日志告警的数据获取和发送告警依赖与整个Sink的消费,如果后端存储恢复时间在半小时后,那么日志告警发送时间也是半小时后,这对线上依赖日志告警的业务是不可接受的。
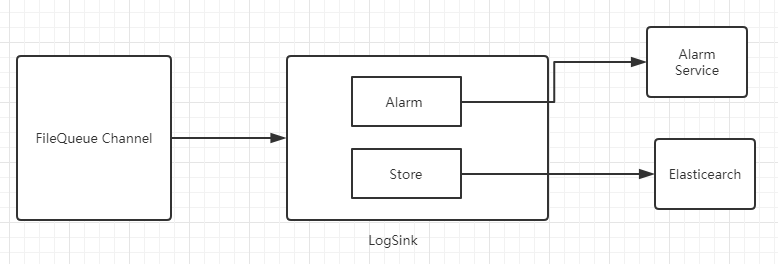
针对上述问题,我们针对FileQueueChannel 做了扩展,使得同一份数据,支持多个Sink并行消费,相互拥有独立线程池,互不干扰:
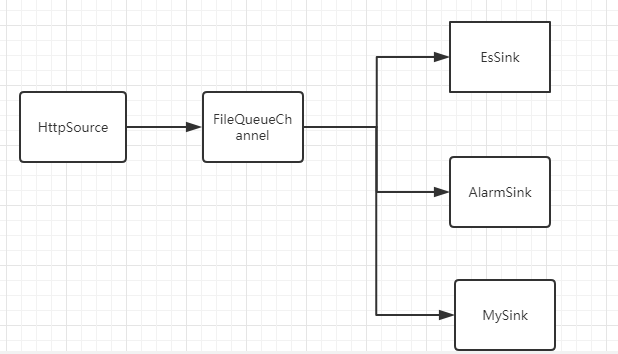
多个Sink维护自己的消费位点,彼此互不干扰。比如ES入库失败或延迟,并不会影响AlarmSink的执行。
我们最早服务成功率、耗时的告警是入库以后再实时计算,这个实时计算系统的延迟就会影响告警的及时性,所以改为不需要关联计算的指标,直接在接收器进行告警,从而大幅提高告警的及时性和可靠性。
2、数据整形
比如调用链系统,SDK每次上报的数据量条数不一,数据类型不同,通过数据分类并整形,从Channel消费的数据条数是固定的,大幅提升了数据写入的性能。
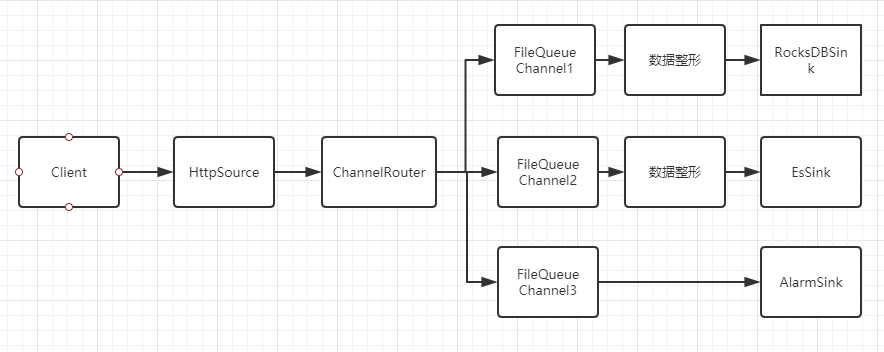
3、消息路由
SDK上报的消息类型有多种,我们需要对不同的消息分发到不同的通道去处理,比如将DataEvent对象logType Header值等于jvm的消息,路由到xxxChannel。
<route-rules>
<rule>
<expression>header.logType="jvm"</expression>
<targetChannel>xxxChannel</targetChannel>
</rule>
</route-rules>
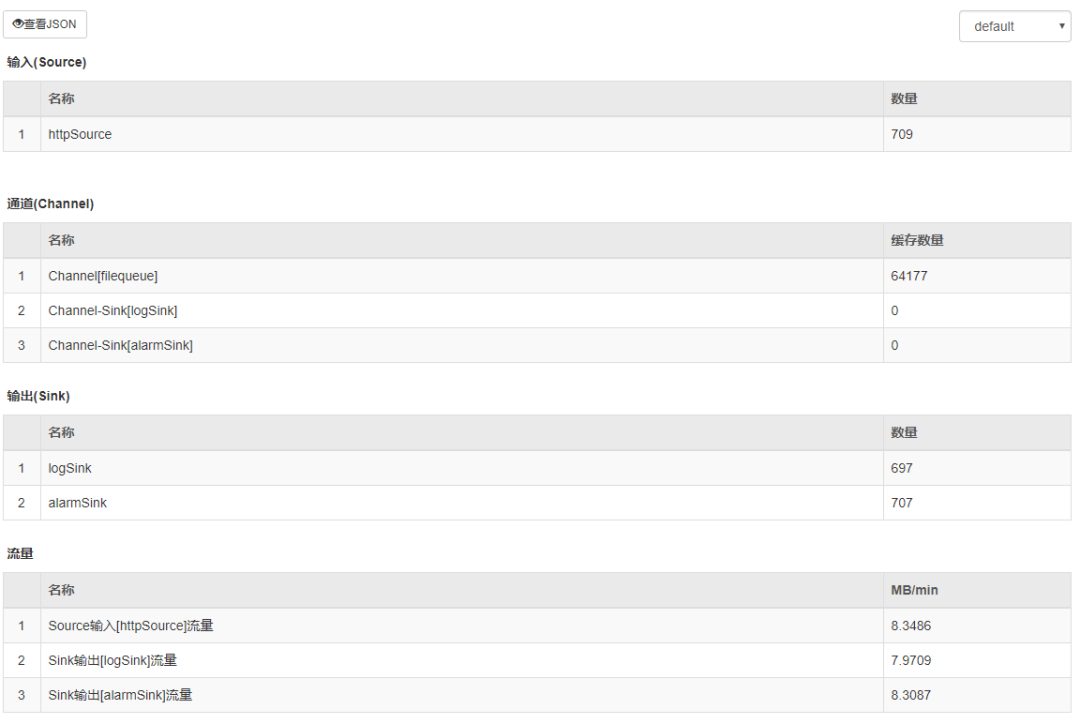
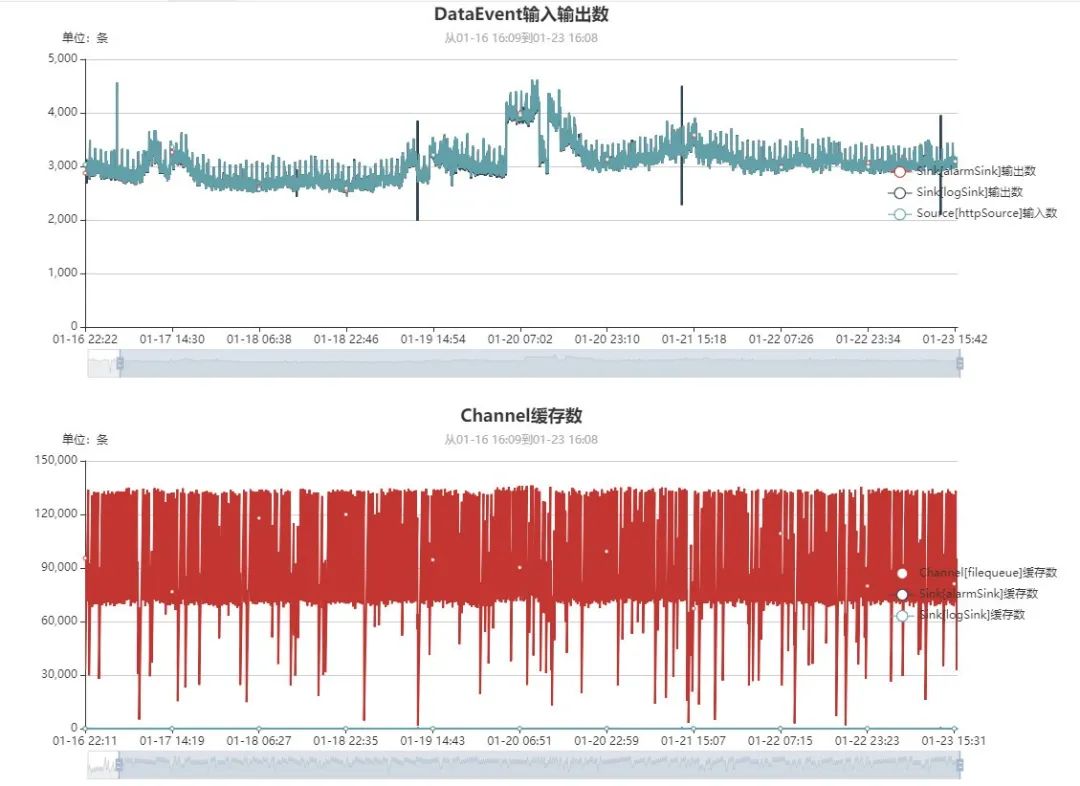
4、可视化
ESA DataFlow内置SQLite数据库,按分钟维度实时采集7天内的数据,并提供内置简单UI界面,当然DataFlow也提供Prometheus监控接口,方便集成到内部监控系统:
测试数据
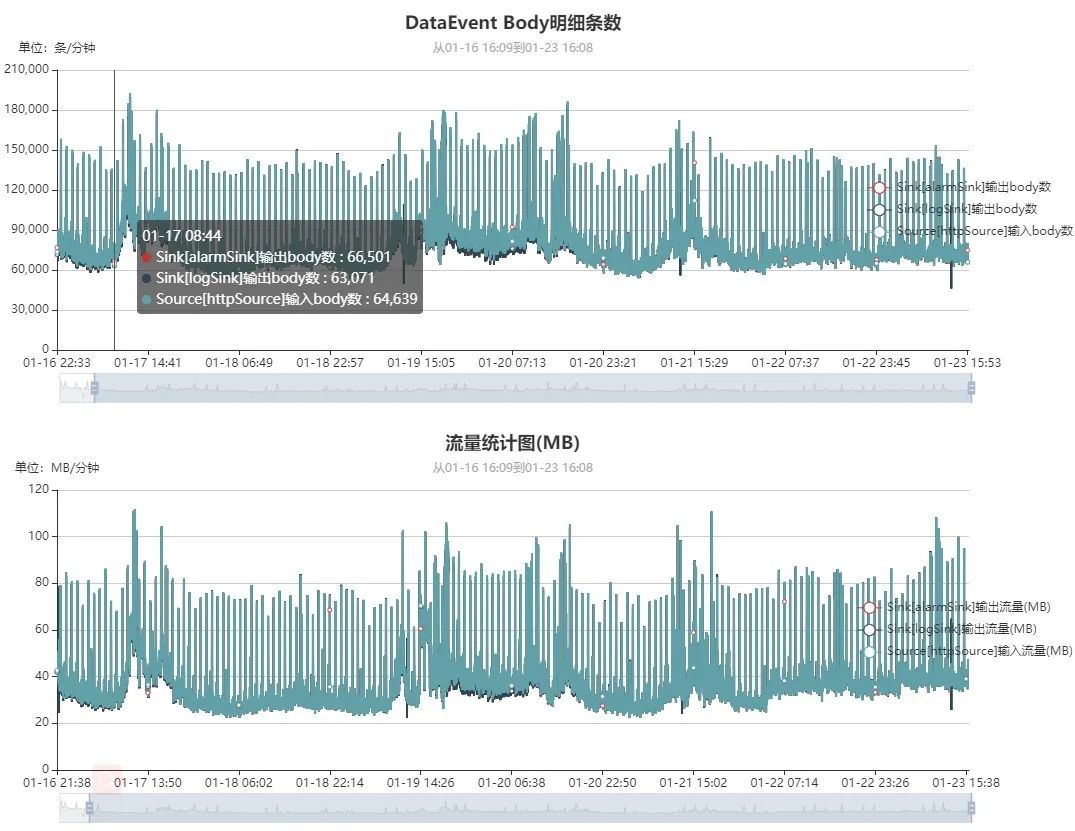
四、ESA DataFlow在OPPO的应用
ESA DataFlow已广泛应用在调用链采集,日志采集等业务。
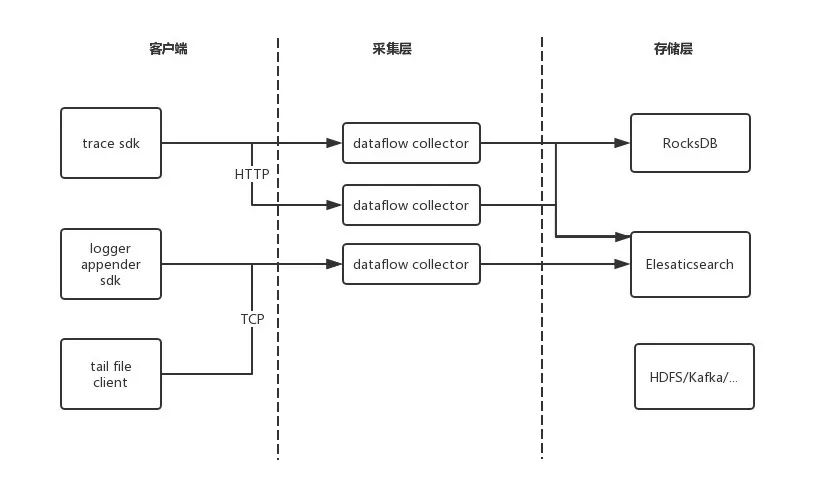
典型的采集服务的部署图如下:
以日志采集为例,基于DataFlow实现的类图如下:
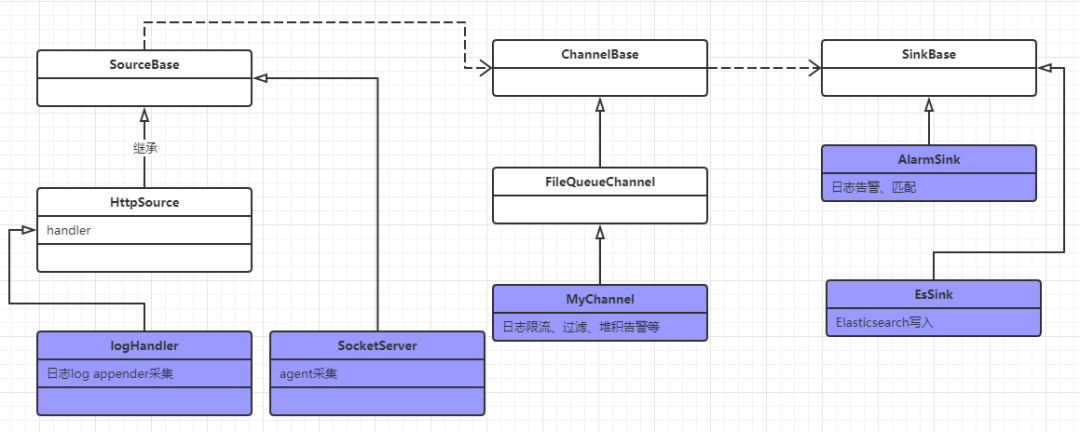
紫色部分为用户自定义扩展。
由上图可知,ESA DataFlow大大降低了开发者开发一个采集系统的难度。
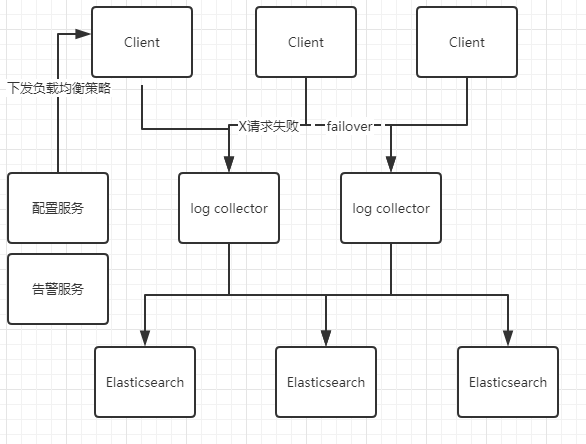
日志采集架构
客户端分LogAppender及agent采集2种方式。客户端采用权重轮询的调度算法,作为负载均策略。如果其中一个节点crash,客户端可以failover到其他节点,以此来保证数据可靠性。
开发者可以通过每个节点的内置控制台来查看统计数据,并以此调整权重策略。
五、结语
基于ESA DataFlow,开发者能很容易开发出高性能的数据采集服务:它内置的HttpSource、FileQueueChannel等组件,保证其高性能和高吞吐量。而轻量级和简单易学的架构能保证针对业务不同的数据处理需求,可以很容易扩展出不同的插件来满足。而通过内置的WEB界面,可以直观分析和跟踪一周内的数据流量情况。是一个面向开发者而生的轻量级、高性能的数据采集、传输和处理框架。
目前使用ESA DataFlow开发的调用链采集服务日均处理大约千亿以上级别的数据量,集群规模大约在10个节点左右。服务上线后,在稳定性、性能、吞吐等方面均达到了预期的效果。

- 测试数据准备难不难?你知道如何提升测试数据准备效率吗?
- 看似安全的系统背后隐藏危机?如何用数据驱动提升系统质量
- 如何提升sqlite中blob数据的查询性能
- 如何提升数据敏感度
- 横瓜先生如何用MDB和XLS等低性能数据库来处理千亿级数据量。
- 网站分析实战——如何以数据驱动决策,提升网站价值(大数据时代的分析利器)
- Java - 使用JDBC操作数据库时,如何提升读取数据的性能?如何提升更新数据的性能?
- 网站分析实战——如何以数据驱动决策,提升网站价值(大数据时代的分析利器)
- 微服务架构下,分布式数据库如何支撑千亿级数据?
- Python如何处理大数据?3个技巧效率提升攻略
- 人人在谈的数据驱动,到底如何提升系统质量?
- 技术文章 | 大数据时代_如何利用数据来提升设计?
- 如何提升服务器数据安全
- 移动应用数据计如何提升用户体验
- 网站分析实战——如何以数据驱动决策,提升网站价值(大数据时代的分析利器)
- 如何提升会员列表数据的质量
- 【MYSQL】批量数据插入mysql,如何提升性能
- Salesforce解密如何通过AI和数据提升销售业绩
- 资深程序员分享:如何用Flume+Kafka+Storm+Redis构建大数据实时处理系统
- MaxCompute分布式计算如何提升基因大数据处理速率?