布隆过滤器&Redis缓存&穿透&雪崩&击穿&热点key
布隆过滤器
1、布隆过滤器是什么?(判断某个key一定不存在)
1. 本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构
2. 特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
3. 相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
使用:
1. 布隆过滤器在NoSQL数据库领域中应用的非常广泛
2. 当用户来查询某一个row时,可以先通过内存中的布隆过滤器过滤掉大量不存在的row请求,然后去再磁盘进行查询
3. 布隆过滤器说某个值不存在时,那肯定就是不存在,可以显著降低数据库IO请求数量
2、应用场景
1)场景1(给用户推荐新闻)
1. 当用户看过的新闻,肯定会被过滤掉,对于没有看多的新闻,可能会过滤极少的一部分(误判)。
2. 这样可以完全保证推送给用户的新闻都是无重复的。
2)场景2(爬虫url去重)
1. 在爬虫系统中,我们需要对url去重,已经爬取的页面不再爬取
2. 当url高达几千万时,如果一个集合去装下这些URL地址非常浪费空间
3. 使用布隆过滤器可以大幅降低去重存储消耗,只不过也会使爬虫系统错过少量页面
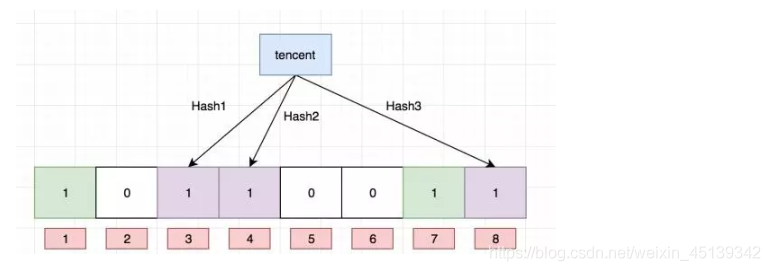
3、布隆过滤器原理
添加:值到布隆过滤器
1)向布隆过滤器添加key,会使用 f、g、h hash函数对key算出一个整数索引,然后对长度取余
2)每个hash函数都会算出一个不同的位置,把算出的位置都设置成1就完成了布隆过滤器添加过程
查询:布隆过滤器值
1)当查询某个key时,先用hash函数算出一个整数索引,然后对长度取余
2)当你有一个不为1时肯定不存在这个key,当全部都为1时可能有这个key
3)这样内存中的布隆过滤器过滤掉大量不存在的row请求,然后去再磁盘进行查询,减少IO操作
删除:不支持
1)目前我们知道布隆过滤器可以支持 add 和 isExist 操作
2)如何解决这个问题,答案是计数删除,但是计数删除需要存储一个数值,而不是原先的 bit 位,会增大占用的内存大小。
3)增加一个值就是将对应索引槽上存储的值加一,删除则是减一,判断是否存在则是看值是否大于0。
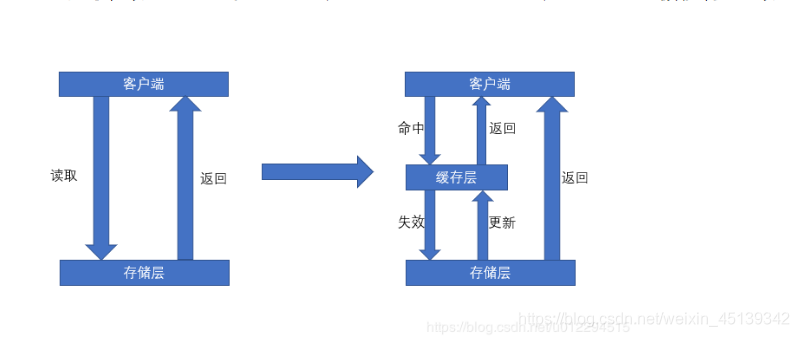
Redis 缓存场景
客户端请求在缓存层命中直接返回内容,如果Miss就去存储层读取,存储层读取到数据再写入缓存层,然后再返回客户端。
优点:
- 加速读写效率
- 降低后端负载
- 减少存储层压力
缺点:
- 数据不能保证一致性
- 代码维护成本和运维成本
主从复制
主节点数据更新后根据配置和策略,自动同步到备节点的master/slaver的机制,主节点负责写数据,从节点负责读数据,主节点定期把数据同步到从节点保证数据的一致性。
优点:
- 读写分离
- 容灾恢复
缺点:
- 主从复制,若主节点出现问题,则不能提供服务,需要人工修改配置将从变主
- 主从复制主节点的写能力单一,能力有限
- 单机节点的存储能力也有限
缓存穿透
1)定义
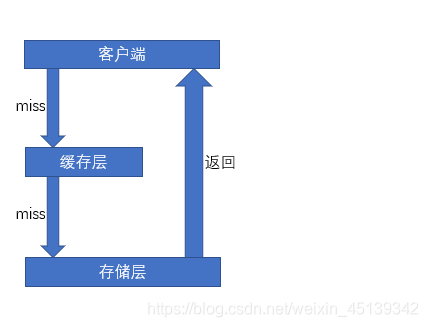
1. 缓存穿透是指查询一个一定不存在的数据,由于缓存不命中,接着查询数据库也无法查询出结果,
2. 虽然也不会写入到缓存中,但是这将会导致每个查询都会去请求数据库,造成缓存穿透;
3.在查询一个不存在的数据时,在缓存层查不到数据则会去访问存储层,且返回的空数据也不会写入缓存层。这将导致不存在的数据每次查询都必定会到存储层查询,缓存层失去了存在的意义。当大量恶意查询不存在数据时,可能因为频繁访问导致数据库宕机。
2)解决方法 :
布隆过滤
对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,将所有可能存在的数据哈希到一个足够发的 bigmap 中,一个一定不存在的数据会被该 bigmap 拦截掉,从而避免对底层存储系统造成查询压力。
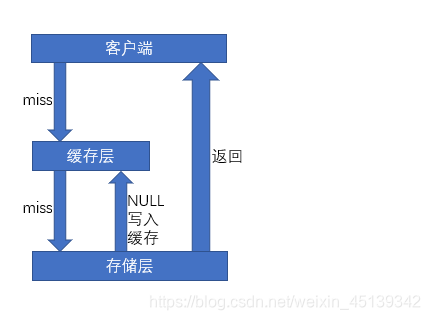
【推荐】如果一个查询返回的数据为空(无论数据为空,或是系统故障),将空结果进行缓存,设置一个最长不超过五分钟的过期时间。这样过期时间内查询的时候就会直接在缓存层获取,并直接返回null。
雪崩效应
1)定义
1. 缓存雪崩是指,由于缓存层承载着大量请求,有效的保护了存储层,但是如果缓存层由于某些原因整体不能提供服务
2. 于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
2)解决方法
1. 保证缓存层服务高可用性:比如 Redis Sentinel 和 Redis Cluster 都实现了高可用
2. 依赖隔离组件为后端限流并降级:比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
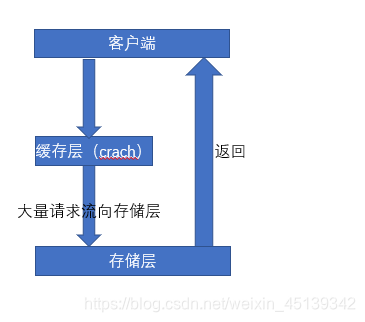
缓存击穿
1)定义:
1. 缓存击穿,就是说某个 key 非常热点,访问非常频繁,处于集中式高并发访问的情况
2. 当这个 key 在失效的瞬间,大量的请求就击穿了缓存,直接请求数据库,就像是在一道屏障上凿开了一个洞。
2)解决方法
1. 解决方式也很简单,可以将热点数据设置为永远不过期;
2. 或者基于 redis or zookeeper 实现互斥锁,等待第一个请求构建完缓存之后,再释放锁,进而其它请求才能通过该 key 访问数据
热点KEY
热点问题产生原因
热点问题产生的原因大致有以下两种:
1.1 用户消费的数据远大于生产的数据(热卖商品、热点新闻、热点评论、明星直播)。
在日常工作生活中一些突发的的事件,例如:
双十一期间某些热门商品的降价促销,当这其中的某一件商品被数万次点击浏览或者购买时,会形成一个较大的需求量,这种情况下就会造成热点问题。
同理,被大量刊发、浏览的热点新闻、热点评论、明星直播等,这些典型的读多写少的场景也会产生热点问题。
1.2 请求分片集中,超过单 Server 的性能极限。
在服务端读数据进行访问时,往往会对数据进行分片切分。
此过程中会在某一主机 Server 上对相应的 Key 进行访问,当访问超过 Server 极限时,就会导致热点 Key 问题的产生。
热点问题的危害
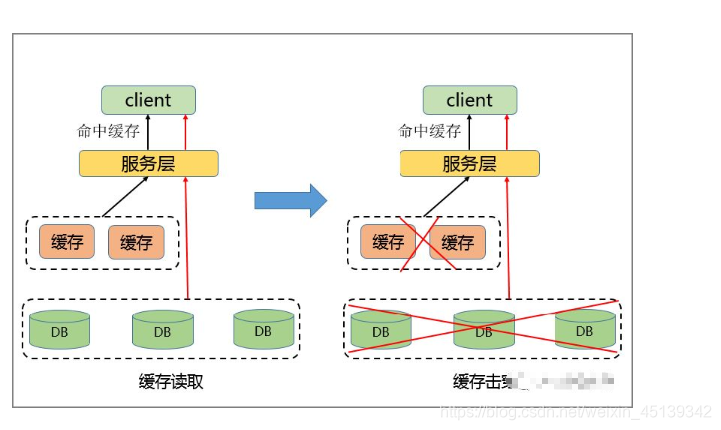
• 流量集中,达到物理网卡上限。
• 请求过多,缓存分片服务被打垮。
• DB 击穿,引起业务雪崩。
如何解决热点key的问题
目前业内的方案有两种
(1)利用二级缓存
比如利用 ehcache ,或者一个 HashMap 都可以。在你发现热key以后,把热key加载到系统的JVM中。
针对这种热key请求,会直接从jvm中取,而不会走到redis层。
假设此时有十万个针对同一个key的请求过来,如果没有本地缓存,这十万个请求就直接怼到同一台redis上了。
现在假设,你的应用层有50台机器,OK,你也有jvm缓存了。这十万个请求平均分散开来,每个机器有2000个请求,会从JVM中取到value值,然后返回数据。避免了十万个请求怼到同一台redis上的情形。
(2)备份热key
这个方案也很简单。不要让key走到同一台redis上不就行了。我们把这个key,在多个redis上都存一份不就好了。接下来,有热key请求进来的时候,我们就在有备份的redis上随机选取一台,进行访问取值,返回数据。
- 点赞
- 收藏
- 分享
- 文章举报
 代码搬运小能手
发布了42 篇原创文章 · 获赞 33 · 访问量 2715
私信
关注
代码搬运小能手
发布了42 篇原创文章 · 获赞 33 · 访问量 2715
私信
关注

- redis缓存穿透、缓存雪崩、缓存击穿(热点Key)解决方案
- 缓存击穿、失效及热点key问题
- 缓存击穿、失效以及热点key问题
- 热点key问题(mutex key)
- 缓存热点key问题
- 缓存系列文章--8.热点key问题(mutex key)
- 关于【缓存穿透,缓存击穿,缓存雪崩,热点数据丢失】问题的解决方案
- 缓存穿透、缓存击穿、缓存雪崩、热点数据失效
- Redis缓存雪崩、缓存穿透、热点Key解决方案和分析
- 如何发现 Redis 热点 Key ,解决方案有哪些?
- 云数据库memcached之热点key问题解决方案
- Redis 热点key
- spark 通过打散热点key解决数据倾斜问题
- REDIS (13) 缓存的穿透,雪崩和热点key
- 生产环境Redis中的热点key如何发现并优化?
- 基于redis(key分段,避免一个key过大) 和db实现的 布隆过滤器(解决hash碰撞问题)
- 基于redis(key分段,避免一个key过大) 和db实现的 布隆过滤器(解决hash碰撞问题)
- redis 缓存失效与热点key解决方案
- Redis 缓存穿透、缓存雪崩、热点Key问题分析和解决方案
- 缓存热点key问题(mutex key)