文本预处理、语言模型、循环神经网络基础
文本预处理
读入文本
import collections
import re
def read_time_machine():
with open('/Users/apple/Desktop/YZ Programming/The_Time_Machine.txt', 'r') as f:
lines = [re.sub('[^a-z]+', ' ', line.strip().lower()) for line in f]
return lines
lines = read_time_machine()
print('sentences %d' % len(lines))
sentences 3583
读入一个英文小说的txt文本。lines = [re.sub(’[^a-z]+’, ’ ', line.strip().lower()) for line in f]的作用是去掉每一行前后的空白字符,大写转换成小写,非英文字符构成的子串替换成空格。
文本的原格式是这样的:

经过处理后如下:
print(lines[:10])
[’’, ‘the project gutenberg ebook of the time machine by h g wells’, ‘’, ‘this ebook is for the use of anyone anywhere at no cost and with’, ‘almost no restrictions whatsoever you may copy it give it away or’, ‘re use it under the terms of the project gutenberg license included’, ‘with this ebook or online at www gutenberg net’, ‘’, ‘’, ‘title the time machine’]
分词
def tokenize(sentences, token='word'):
"""Split sentences into word or char tokens"""
if token == 'word':
return [sentence.split(' ') for sentence in sentences]elif token == 'char':
return [list(sentence) for sentence in sentences]else:
print('ERROR: unkown token type '+token)
tokens = tokenize(lines)
tokens[1:4]
[[‘the’,
‘project’,
‘gutenberg’,
‘ebook’,
‘of’,
‘the’,
‘time’,
‘machine’,
‘by’,
‘h’,
‘g’,
‘wells’],
[’’],
[‘this’,
‘ebook’,
‘is’,
‘for’,
‘the’,
‘use’,
‘of’,
‘anyone’,
‘anywhere’,
‘at’,
‘no’,
‘cost’,
‘and’,
‘with’]]
tokenize函数有两个参数:sentences是一个列表,列表里的元素是字符串。token是个标志,表示要做哪一个级别的分词。
if token == 'word':
return [sentence.split(' ') for sentence in sentences]
如果是token等于 ‘word’,做单词级别的分词。用空格来分割句子。
elif token == 'char': return [list(sentence) for sentence in sentences]
如果token等于 ‘char’,做字符级别的分词。直接把字符串转换成列表。
建立字典
class Vocab(object): def __init__(self, tokens, min_freq=0, use_special_tokens=False): counter = count_corpus(tokens) # : self.token_freqs = list(counter.items()) self.idx_to_token = [] if use_special_tokens: # padding, begin of sentence, end of sentence, unknown self.pad, self.bos, self.eos, self.unk = (0, 1, 2, 3) self.idx_to_token += ['', '', '', ''] else: self.unk = 0 self.idx_to_token += [''] self.idx_to_token += [token for token, freq in self.token_freqs if freq >= min_freq and token not in self.idx_to_token]self.token_to_idx = dict() for idx, token in enumerate(self.idx_to_token): self.token_to_idx[token] = idx def __len__(self): return len(self.idx_to_token) def __getitem__(self, tokens): if not isinstance(tokens, (list, tuple)): return self.token_to_idx.get(tokens, self.unk) return [self.__getitem__(token) for token in tokens] def to_tokens(self, indices): if not isinstance(indices, (list, tuple)): return self.idx_to_token[indices] return [self.idx_to_token[index] for index in indices] def count_corpus(sentences): tokens = [tk for st in sentences for tk in st] return collections.Counter(tokens) # 返回一个字典,记录每个词的出现次数
Vocab的作用是把语料库里的每个词都映射到唯一的一个索引编号。当向Vocab查询一个词,它能提供这个词对应的索引编号。查询一个索引,能得到对应的词。
Vocab有三个参数:tokens是一个二维列表,包含了所有的token。min_freq是一个阈值,如果某些词的出现次数低于这个阈值,就把这些词忽略掉。use_special_tokens是一个符号,表示是否需要使用特殊的token。
Vocab的构建思路:
去重
清除低频词
添加特殊token
把每一个token映射到唯一的索引,把索引映射到token
具体步骤:
1 去重和统计词频
(1)定义count_corpus(sentences)函数
把二维的列表变成一维的词的列表,用collections.Counter建立词频字典。

(2)counter = count_corpus(tokens)
self.token_freqs = list(counter.items())
self.token_freqs是由词和词频键值对组成的列表。
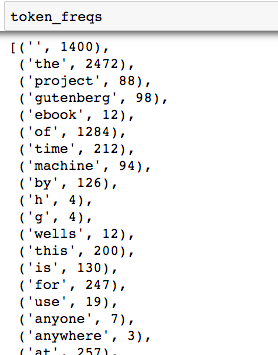
2 增删和特殊处理
(1)建一个存储所有需要维护的token的列表。
self.idx_to_token = []
(2)给列表里添加一些特殊的token。
if use_special_tokens: self.pad, self.bos, self.eos, self.unk = (0, 1, 2, 3) self.idx_to_token += ['', '', '', ''] else: self.unk = 0 self.idx_to_token += ['']
pad、bos、eos、unk分别代表padding, begin of sentence, end of sentence, unknown。如果一个batch里的句子不一样长,在短的句子后面补上若干个pad,就使它和最长的句子一样长。bos和eos是在句子开始和结尾增加的特殊token,表示句子的开始和结束。没在语料库中出现过的词叫未登录词,对未登录词的处理方法是把它们当做unk。
当use_special_tokens为真,就引入以上四个特殊token。如果为假,则只引入unk。
(3)把语料库中的token加入self.idx_to_token列表。
self.idx_to_token += [token for token, freq in self.token_freqs if freq >= min_freq and token not in self.idx_to_token]
因为self.idx_to_token是列表,所以它天然就是一个从索引到token的映射。
(4)从token到索引的映射。
self.token_to_idx = dict() for idx, token in enumerate(self.idx_to_token): self.token_to_idx[token] = idx
vocab = Vocab(tokens) print(list(vocab.token_to_idx.items())[:30])
[(’’, 0), (‘the’, 1), (‘project’, 2), (‘gutenberg’, 3), (‘ebook’, 4), (‘of’, 5), (‘time’, 6), (‘machine’, 7), (‘by’, 8), (‘h’, 9), (‘g’, 10), (‘wells’, 11), (‘this’, 12), (‘is’, 13), (‘for’, 14), (‘use’, 15), (‘anyone’, 16), (‘anywhere’, 17), (‘at’, 18), (‘no’, 19), (‘cost’, 20), (‘and’, 21), (‘with’, 22), (‘almost’, 23), (‘restrictions’, 24), (‘whatsoever’, 25), (‘you’, 26), (‘may’, 27), (‘copy’, 28), (‘it’, 29)]
vocab['the']
1
可以查到某个词的索引。
for i in range(5, 7):
print('words:', tokens[i])
print('indices:', vocab[tokens[i]])
words: [‘re’, ‘use’, ‘it’, ‘under’, ‘the’, ‘terms’, ‘of’, ‘the’, ‘project’, ‘gutenberg’, ‘license’, ‘included’]
indices: [33, 15, 29, 34, 1, 35, 5, 1, 2, 3, 36, 37]
words: [‘with’, ‘this’, ‘ebook’, ‘or’, ‘online’, ‘at’, ‘www’, ‘gutenberg’, ‘net’]
indices: [22, 12, 4, 32, 38, 18, 39, 3, 40]
可以查到语料中某一行的词的索引。
语言模型
题目
1

答案:选项3。
由22阶马尔科夫链,从第三个词开始每个词只与其前两个词有关。
2 下列关于随机采样的描述中错误的是:
A 训练数据中的每个字符最多可以出现在一个样本中
B 每个小批量包含的样本数是batch_size,每个样本的长度为num_steps
C 在一个样本中,前后字符是连续的
D 前一个小批量数据和后一个小批量数据是连续的
答案:D。
随机采样中前后批量中的数据是不连续的。
循环神经网络基础
题目
1 关于循环神经网络描述错误的是:
A 在同一个批量中,处理不同语句用到的模型参数Wh和bh是一样的
B 循环神经网络处理一个长度为TT的输入序列,需要维护TT组模型参数
C 各个时间步的隐藏状态Ht不能并行计算
D 可以认为第t个时间步的隐藏状态Ht包含截止到第t个时间步的序列的历史信息
答案:B。
循环神经网络通过不断循环使用同样一组参数来应对不同长度的序列,故网络的参数数量与输入序列长度无关。
2 关于梯度裁剪描述错误的是:
A 梯度裁剪之后的梯度小于或者等于原梯度
B 梯度裁剪是应对梯度爆炸的一种方法
C 裁剪之后的梯度L2范数小于阈值θ
D 梯度裁剪也是应对梯度消失的一种方法
答案:D。
梯度裁剪只能应对梯度爆炸。
3 关于困惑度的描述错误的是:
A 困惑度用来评价语言模型的好坏
B 困惑度越低语言模型越好
C 有效模型的困惑度应该大于类别个数
答案:C。
一个随机分类模型(基线模型)的困惑度等于分类问题的类别个数,有效模型的困惑度应小于类别个数。
4 关于采样方法和隐藏状态初始化的描述错误的是:
A 采用的采样方法不同会导致隐藏状态初始化方式发生变化
B 采用相邻采样仅在每个训练周期开始的时候初始化隐藏状态是因为相邻的两个批量在原始数据上是连续的
C 采用随机采样需要在每个小批量更新前初始化隐藏状态是因为每个样本包含完整的时间序列信息
答案:C。
随机采样中每个样本只包含局部的时间序列信息,因为样本不完整所以每个批量需要重新初始化隐藏状态。
资料来源:
伯禹学习平台-ElitesAI·动手学深度学习PyTorch版-文本预处理
https://www.boyuai.com/elites/course/cZu18YmweLv10OeV/jupyter/tLxtAC0ZUmyrqaYmSJwWu
伯禹学习平台-ElitesAI·动手学深度学习PyTorch版-语言模型
https://www.boyuai.com/elites/course/cZu18YmweLv10OeV/jupyter/UMWZaZZQHRm8vhvwVKagt
伯禹学习平台-ElitesAI·动手学深度学习PyTorch版-循环神经网络基础
https://www.boyuai.com/elites/course/cZu18YmweLv10OeV/jupyter/74GLt4f6G9GgtnuK_Y7SJ
- 点赞
- 收藏
- 分享
- 文章举报
 weixin_46123847
发布了8 篇原创文章 · 获赞 0 · 访问量 154
私信
关注
weixin_46123847
发布了8 篇原创文章 · 获赞 0 · 访问量 154
私信
关注

- ElitesAI·动手学深度学习PyTorch版学习笔记-文本预处理;语言模型;循环神经网络基础
- 2.文本预处理、语言模型与循环神经网络基础
- 深度学习d2:文本预处理、语言模型、循环神经网络基础
- 02深度学习_文本预处理/语言模型/循环神经网络基础
- 第二次打卡,文本预处理,语言模型,循环神经网络基础
- Task02:文本预处理;语言模型;循环神经网络基础
- 文本预处理、语言模型、循环神经网络基础
- 文本预处理&&语言模型&&循环神经网络基础
- 动手学深度学习(文本预处理+语言模型+循环神经网络基础)
- DL-Pytorch Task02:文本预处理;语言模型;循环神经网络基础
- Task2:文本预处理;语言模型;循环神经网络基础(RNN)
- 伯禹教育AI训练营 Task02:文本预处理;语言模型;循环神经网络基础
- 《动手学深度学习》笔记 Task02:文本预处理;语言模型;循环神经网络基础
- 文本预处理、语言模型、循环神经网络基础 #d2l#
- 动手学深度学习 Task02:文本预处理;语言模型;循环神经网络基础
- TASK2:文本预处理、语言模型、循环神经网络基础
- Task02:文本预处理;语言模型;循环神经网络基础;
- 动手学深度学习PyTorch版 | (2)文本预处理;语言模型;循环神经网络基础
- Task02:学习笔记文本预处理;语言模型;循环神经网络基础
- 《动手学深度学习》笔记 Task02:文本预处理;语言模型;循环神经网络基础