信息标记的三种形式:XML,JSON,YAML
信息标记的三种形式:XML,JSON,YAML
1.标记后的信息可以形成信息组织结构,增加了信息的难度
2,标记后的信息可用来通信、存储或展示
3.标记的结构与信息一样具有重要价值
4.标记后的信息有利于程序理解和运用,更有利于人对信息的利用和深度理解
HTML:hyper text markup language,超文本标记语言,是www信息组织的主要形式,能将声音、图像、视频等超文本的信息嵌入到文本中HTML通过预定义的<>…</>标签形式组织不同类型的信息
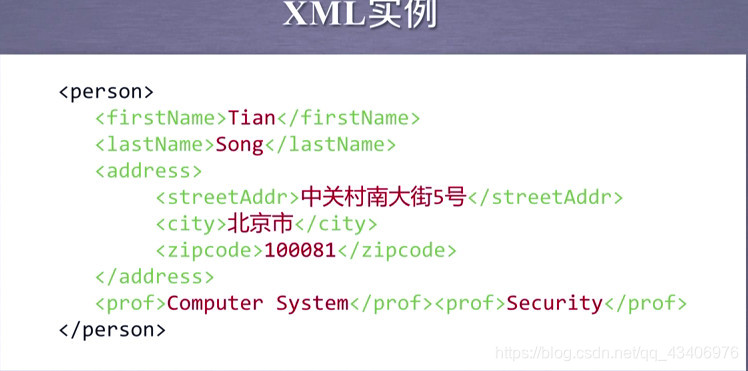
XML:扩展标记语言,采用以标签为主来构建信息、表达信息的方式
JSON:JavaScript语言,面向对象信息的一种表达方式,是有类型的键值对key:value构建的信息表达方式,对信息的定义叫键,如name,对值的描述叫value在
JSON类型中,键和值都需要通过增加双引号来表达它是字符串的形式,如果值不是字符串,而是像123,2020这样的数字,则不用使用双引号,直接写数字即可,一个键有多个值的时候采用[,]的形式,键值对可以嵌套,如:
‘key’:‘value’
‘key’:[1,2,3]
‘key’:{‘subkey’:‘subvalue’}
‘key’:[‘value1’,‘value2’]

YAML:无类型键值对key:value来表达信息,用缩进表示所属
如:
name:beijing
name:
subname:…
用-表示并列关系:name: -beijing -shanghai
用|表示整块数据,用#表示注释


三种标记信息的比较:


数据的爬取:针对给定的url进行爬取,并不爬取其他的url,叫定向爬取
爬取信息时:(1)首先要确定可行性,即提取返回的信息是否写在了html页面的代码中(因为有些数据是通过javascript脚本语言生成的)(2)要爬取的网站是否提供了robots协议,如在网站根目录下的robots.txt,如https://www.baidu.com/robots.txt,若是robots.txt为空,则表示允许所有爬虫无限制爬取
一些常见的网站的robots地址:

http采用url作为网络定位资源的标识,格式:http://host[:post][path]
host:合法的Internet主机域名或IP地址post:端口号,可省略,默认为80,path:请求资源的路径
HTTP协议对资源的操作:

url是通过http协议存取资源的Internet路径,一个url对应一个数据资源
- 点赞
- 收藏
- 分享
- 文章举报
 h...h...
发布了17 篇原创文章 · 获赞 0 · 访问量 244
私信
关注
h...h...
发布了17 篇原创文章 · 获赞 0 · 访问量 244
私信
关注

- 三种不同的标记信息表达方式(XML,JSON,YAML)
- 信息标记的三种形式
- 将从数据库得到的信息分别以HTML,XML,Json的形式输出
- 信息标记的三种形式
- (三)三种信息标记的形式
- 信息标记的三种形式(爬虫基础)
- Tp3.2 RESTFul 根据地区查询生成xml、html、json的Api接口的天气信息
- Comet4J(Comet for Java)是一个纯粹基于AJAX(XMLHTTPRequest)的服务器推送框架,消息以JSON方式传递,具备长轮询、长连接、自动选择三种工作模式。
- 利用AJAX,得到XML和JSON信息,不用JQuery等UI框架,兼容 IE、Firefox、Chrome、Safari、Opera 等浏览器。
- unity中三种数据存储方式ScriptableObject,Json,Xml和Dictionary的序列化
- 战速决Flash ActionScript 3.0 - 以文本形式、XML形式和JSON形式与ASP.NET通信续
- 网站给出的api接口都是xml或json形式的,在j2me中怎么连接?
- python——使用yaml数据格式,PK --> XML,JSON
- YAML 类XML的标记语言
- C/C++使用libcurl库发送http请求(get和post可以用于请求html信息,也可以请求xml和json等串)
- PHP下处理HTTP--json--xml信息
- 将XML形式的数据转换成Json格式
- golang几种常用配置文件使用方法总结(yaml、toml、json、xml、ini)
- 我的Android进阶之旅------>Android获取服务器上格式为JSON和XML两种格式的信息的小程序
- XML数据的三种解析(JSON方式 , DOM方式 , Sax方式)