数据结构与算法-栈和队列
本文部分内容来自网络和博主「宜春」的原创文章
原文链接:https://blog.csdn.net/qq_44543508/article/details/100515630
我jio得博主讲的已经非常通俗易懂了!
本文仅供笔者复习使用
从数据结构角度看,栈和队列也是线性表,其特殊性在于栈和队列的基本操作也是线性表操作的子集,他们是操作受限的线性表,英词可以称作限定的数据结构。但从数据类型角度来看,他们是和线性表不相同的两类重要的抽象数据类型。
栈的定义和特点
如何理解“栈”?用现实一个通俗贴切的例子,我们平时放盘子的时候,都是从下往上一个一个放;取的时候,我们是从上往下一个一个地依次取,不能从中间任意抽出,先进后出,这就是典型的“栈”结构,当某个数据集合只涉及在一端插入和删除数据,并且满足后进先出、先进后出的特性,我们就应该首选“栈”这种数据结构。
队列的定义和特点
和栈相反,队列是一种先进先出的线性表,他只允许在表的一一端插入,在表的另一端删除。其实说白了就和咱们平时在食堂打饭排队一个道理。这个线性表有一个表头和表尾分别提供删除和插入的操作。在程序设计设计中也经常出现队列,一个典型的例子就是操作系统的作业排队,在允许多道程序运行的计算机系统中,同时偶几个程序在运行。如果运行的结果需要通过管道输出,那么就要按照请求输入的先后次序排队,每当通道传输完毕可以接受新的输出任务时,对头的作业先从队列中推出做输出操作,凡是申请输出的作业都是从队尾进入队列。
栈的表示和操作的实现
实际上,栈既可以用数组来实现,也可以用链表来实现。用数组实现的栈,我们叫作顺序栈,用链表实现的栈,我们叫作链式栈。不管是顺序栈还是链式栈,我们存储数据只需要一个大小为n的数组就够了。在入栈和出栈过程中,只需要一两个临时变量存储空间,所以空间复杂度是O(1)。
注意,这里存储数据需要一个大小为n的数组,并不是说空间复杂度就是O(n)。因为,这n个空间是必须的,无法省掉。所以我们说空间复杂度的时候,是指除了原本的数据存储空间外,算法运行还需要额外的存储空间。
空间复杂度分析是不是很简单?时间复杂度也不难。不管是顺序栈还是链式栈,入栈、出栈只涉及栈顶个别数据的操作,所以时间复杂度都是O(1)。
一、顺序栈的表示和实现

#define MAXSIZE 100
typedef struct {
SElemType *base; //栈底指针
SELemType *top; //栈顶指针
int stackSize; //栈的最大容量
}SqStack;
顺序栈的初始化
Status InitStack (SqStack $S) {
if (!S.base) {
exit (OVERFLOW) //申请内存失败退出
}
S.base = S.top; //空栈
S.stackSize = MAXSIZE;
return OK;
}
入栈
Status Push (SqStack &S,ELemType e) {
if (S.top-S.base == MAXSIZE) {
return ERROR; //栈满
}
S.top++;
*S.top = e; //元素e压入栈
return OK;
}
取栈顶元素
Status Pop (SqStack &S,ElemType e) {
if (S.base ==S.top) {
return ERROR; //空栈没有元素
}
e =(*S.top-1); //取得栈顶元素,栈的顶指针不变
return OK;
}
JAVA使用数组实现栈
public class MyStack {
//栈的底层我们使用数组来存储数据
int[] elements;
public MyStack() {
elements = new int[0];
}
//压入元素
public void push(int element) {
// 创建一个新的数组
int[] newArr = new int[elements.length + 1];
// 把原数组中的元素复制到新数组中
for (int i = 0; i < elements.length; i++) {
newArr[i] = elements[i];
}
// 把添加的元素放入新数组中
newArr[elements.length] = element;
// 使用新数组替换旧数组
elements = newArr;
}
//取出栈顶元素
public int pop() {
//栈中没有元素
if(elements.length==0) {
throw new RuntimeException("stack is empty");
}
//取出数组的最后一个元素
int element = elements[elements.length-1];
//创建一个新的数组
int[] newArr = new int[elements.length-1];
//原数组中除了最后一个元素的其它元素都放入新的数组中
for(int i=0;i<elements.length-1;i++) {
newArr[i]=elements[i];
}
//替换数组
elements=newArr;
//返回栈顶元素
return element;
}
//查看栈顶元素
public int peek() {
//栈中没有元素
if(elements.length==0) {
throw new RuntimeException("stack is empty");
}
return elements[elements.length-1];
}
//判断栈是否为空
public boolean isEmpty() {
return elements.length==0;
}
}
2、链栈的表示和实现
链栈是指采用链式存储结构实现的栈,通常链栈用单链表来表示。
typedef struct stackNode {
ElemType data;
struct StackNode *next;
}StackNode,. LinkStack;
链栈的初始化
Status InitStack (LinkStack &S) {
S = NULL;
return OK; //构造一个空栈,栈顶指针指向NULL;
}
链栈的入栈
Status Push (LinkStack &S, ElemType e) {
p = new StackNode; //生成一个新的结点
p ->data = e;
p ->next = S;
S = p; //重置新的顶指针
return OK;
}
链栈取顶元素
Status Pop (LinkStack &S) {
if (S=NULL;) {
return ERROR; //空栈错误
}
return S->data;
}
JAVA使用链表实现栈
package stack;
/**
* 基于链表实现的栈。
*/
public class StackBasedOnLinkedList {
private Node top = null;
public void push(int value) {
Node newNode = new Node(value, null);
// 判断是否栈空
if (top == null) {
top = newNode;
} else {
newNode.next = top;
top = newNode;
}
}
/**
* 我用-1表示栈中没有数据。
*/
public int pop() {
if (top == null) return -1;
int value = top.data;
top = top.next;
return value;
}
public void printAll() {
Node p = top;
while (p != null) {
System.out.print(p.data + " ");
p = p.next;
}
System.out.println();
}
private static class Node {
private int data;
private Node next;
public Node(int data, Node next) {
this.data = data;
this.next = next;
}
public int getData() {
return data;
}
}
}
二、队列的表示和操作的实现
栈只支持两个基本操作:入栈push()和出栈pop()。队列跟栈非常相似,支持的操作也很有限,最基本的操作也是两个:入队enqueue(),放一个数据到队列尾部;出队dequeue(),从队列头部取一个元素。所以,队列跟栈一样,也是一种操作受限的线性表数据结构。队列的概念很好理解,基本操作也很容易掌握。作为一种非常基础的数据结构,队列的应用也非常广泛,特别是一些具有某些额外特性的队列,比如循环队列、阻塞队列、并发队列。它们在很多偏底层系统、框架、中间件的开发中,起着关键性的作用。比如高性能队列Disruptor、Linux环形缓存,都用到了循环并发队列;Java concurrent并发包利用ArrayBlockingQueue来实现公平锁等。
跟栈一样,队列可以用数组来实现,也可以用链表来实现。用数组实现的栈叫作顺序栈,用链表实现的栈叫作链式栈。同样,用数组实现的队列叫作顺序队列,用链表实现的队列叫作链式队列。
1、循环队列:用数组实现队列
和顺序栈相类似,在队列的顺序存储结构中,除了用一组地址连续的存储单元依次放入从队头到队尾的元素以外,还需要设置两个整型变量front和rear分别指示队列头元素和队列为元素的位置(后面分别称为头指针和尾指针)。
队列的表示
#define MAXQSIZE 100
typedef struct {
QElemType *base ; //存储空间的基地址
int front ; //头指针
int rear; //尾指针
}SqQueue;
在创建空队列时,令front = rear=0,每当插入新的队尾元素时,尾指针rear增加1;每当删除对头元素时,头指针front加1.因此,在非空队列中,头指针始终指向队列头元素,尾指针始终指向队列尾元素的下一个位置。
那么这里当然也会有一个问题,这个添加元素的时候尾指针移动到了最右边的时候,就不能在朝里面添加数据了?
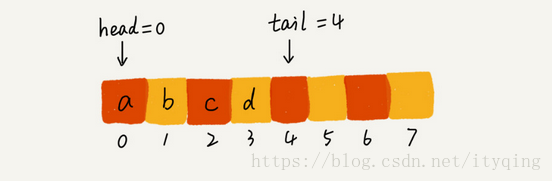
我们可以直观的看到当我们去除和添加一定的元素的时候,队列的位置未必被占满。
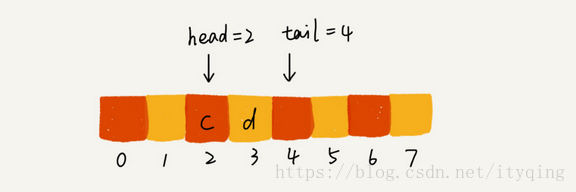
在出队时可以不用搬移数据。如果没有空闲空间了,我们只需要在入队时,再触 发一次数据的搬移操作。
当队列的tail指针移动到数组的最右边后,如果有新的数据入队,我们可以将 head到tail之间的数据,整体搬移到数组中0到tail-head的位置。
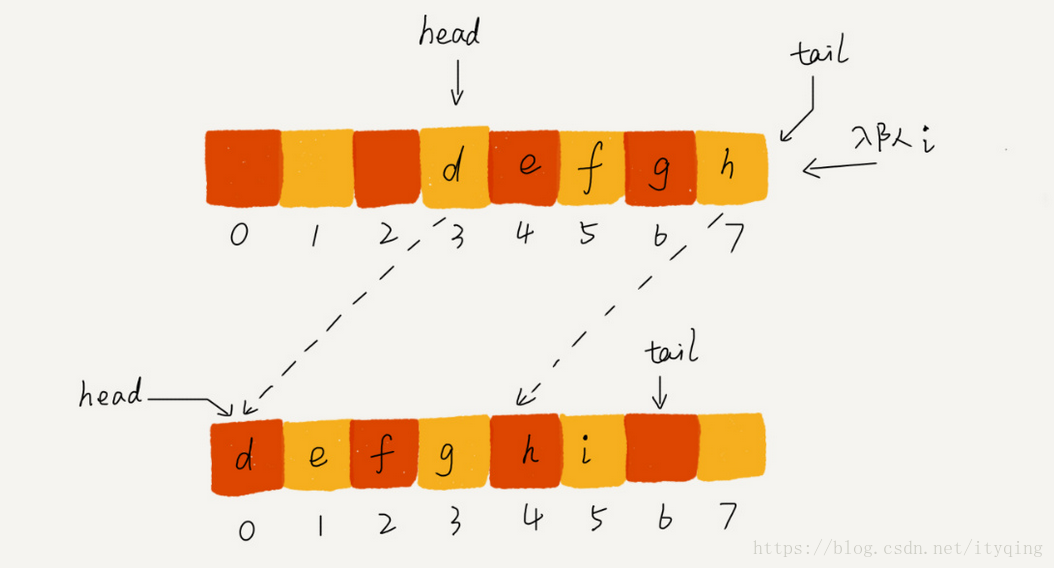
教材上把上述问题称作“假溢出触发的数据搬移”,当然也就有了循环队列这种解决方式。
用数组来实现队列的时候会有数据搬移操作,这样入队操作性能就会受到影响。那有没有办法能够避免数据搬移呢?我们来看看循环队列的解决思路。
循环队列,顾名思义,它长得像一个环。原本数组是有头有尾的,是一条直线。现在我们把首尾相连,扳成了一个环。
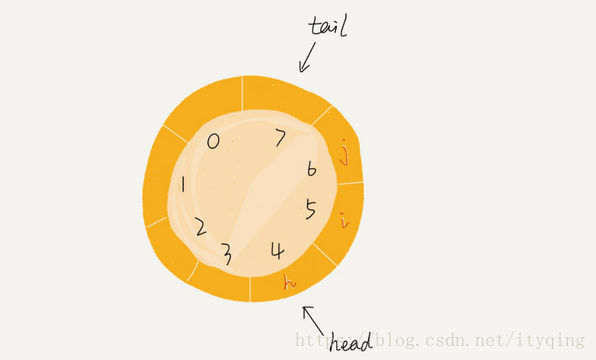
如图这就是一个循环队列,队列长度为8,头指针head指向4,尾指针指向7。此时若是再向队列中入队新元素,那么元素将放入7的位置,但是tail的值并不是像前面一样+1,而是变成了0。当再有一个元素b入队时,我们将b放入下标为0的位置,然后tail加1更新为1,所以,在a, b依次入队之后,循环队列中的元素就变成了下面的样子:
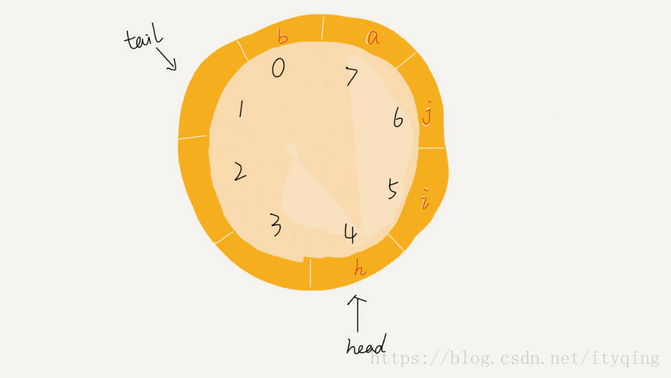
由图不难看到判断队列是否为空的条件是head==tail;
那么如何判断队列是否满员的条件是啥?这就是前面我们要解决的“假溢出”问题。
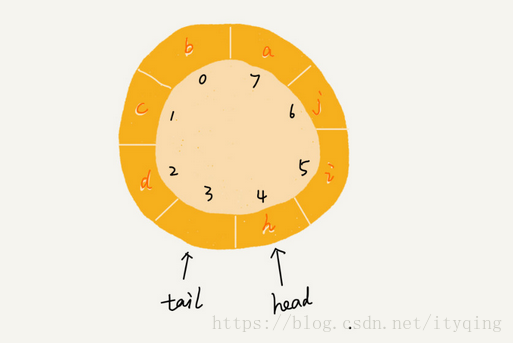
如图要是再入队一个新元素后队列就满了,那么那时候tail指向哪里去了?
仔细想想好像是不能在朝里面入队新元素了为什么呢?你不会让我的tail指向head的位置吧!所以当队列满的时候tail的位置是没有元素的,循环队列会浪费一个存储空间。
上图队满的状态是:
tail=3, head=4, n=8,
多画几个总结出来队满条件:
(tail+1)%n=head
到这里算是对这个循环队列有了初步的认识,那么接下来就要上代码来实现和操作他了不是?
循环队列的实现和操作
1、循环队列初始化
Status InitQueue (SqQueue &Q) {
Q.base = new QElemType [MAXQSIZE]; //为队列分配一个最大容量为MAXQSIZE的数组空间,注意这里并不是循环队列的长度。
if (!Q.base) {
exit (OVERFLOW); //存储分配失败
}
Q.front = Q.rear = 0; //头指针和尾指针为零,空队列
return OK;
}
2、求循环队列长度
int QueueLength (SqQueue &Q) {
int n = (Q.rear-Q.front+MAXQSIZE)%MAXQSIZE;
return n;
}
既然是循环队列嘛,那么肯定有rear-front为负值的时候啊。
(Q.rear-Q.front+MAXQSIZE)%MAXQSIZE
对于循环队列,差值为负的时候,把差值加上MAXQSIZE在与MAXSIZE求余就是解决之道。
3、循环队列的入队
Status EnQueue (SqQueue &Q ,ElemType e) {
if ((Q.rear+1)%MAXQSIZE ==Q.front) {
return ERROR; //队列已满
}
Q.base[Q.rear] = e; //新元素入队
Q.rear = (Q.rear+1)%MAXQSIZE; //队尾指针移动一位
/**注意不是rear直接加一*/
}
4、循环队列的出队
Status DeQueue (SqQueue &Q, ElemType &e) {
if (Q.rear ==Q.front) {
return ERROR ; //空队列
}
e = Q.base [Q.front];
Q.front =(Q.front+1)%MAXQSIZE; //对头指针移动一位
return OK;
}
5、取队头元素
SElemType GetHead(SqQueue &Q, ElemType &e) {
if (Q.rear ==Q.front) {
return ERROR ; //空队列
}
e = Q.base [Q.front];
return e;
6、JAVA使用数组实现队列
package queue;
// 用数组实现的队列
public class ArrayQueue {
// 数组:items,数组大小:n
private String[] items;
private int n = 0;
// head表示队头下标,tail表示队尾下标
private int head = 0;
private int tail = 0;
// 申请一个大小为capacity的数组
public ArrayQueue(int capacity) {
items = new String[capacity];
n = capacity;
}
// 入队
public boolean enqueue(String item) {
// 如果tail == n 表示队列已经满了
if (tail == n) return false;
items[tail] = item;
++tail;
return true;
}
// 出队
public String dequeue() {
// 如果head == tail 表示队列为空
if (head == tail) return null;
// 为了让其他语言的同学看的更加明确,把--操作放到单独一行来写了
String ret = items[head];
++head;
return ret;
}
public void printAll() {
for (int i = head; i < tail; ++i) {
System.out.print(items[i] + " ");
}
System.out.println();
}
}
2、链队:用链表实现队列
基于链表的实现:
需要两个指针: head指针和tail指针,它们分别指向链表的第一个结,点和最后一个结点。
如图所示,入队时, tail->next= new node, tail = tail->next:出队时, head = head->next.
链队的存储结构:
typedef struct QNode {
QElemType data; //单链表的数据域
struct QNode *next; //单链表的指针域
}QNode ,*QueuePtr;
typedef struct { //结构体嵌套
QueuePtr front; //对头指针
QueuePtr rear; //队尾指针
}LinkQueue; //结构体变量的无名构造
}LinkQueue;
链队操作的实现
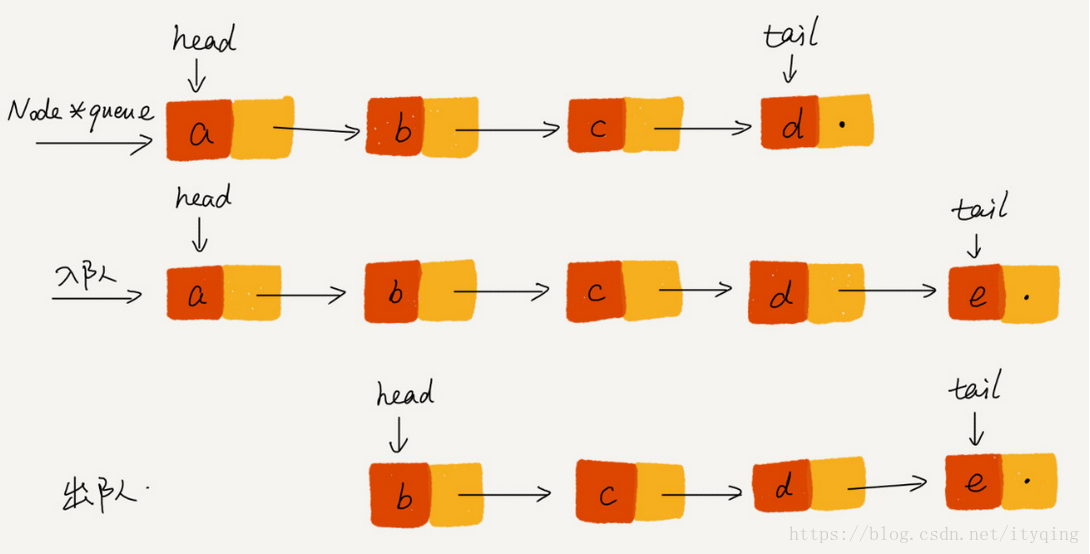
链队的操作即为单链表的删除和插入操作的特殊情况,注释进一步修改尾指针和头指针。
1、链队的初始化
Staus InitQueue (LinkQueue &Q) {
Q.front =Q.rear = new QNode; //生成头结点,队头队尾指针都指向此结点
Q.front ->next = NULL; //头指针置空
return OK;
2、链队的入队
Status EnQueue (LinkQueue &Q ,ElemType e) {
p = new QNode; //先new出一个新结点
p ->data = e; //新结点数据域放上数据
p ->next = NULL; //新结点指针域指向NULL
Q.rear ->next = p; //原来指向NULL的尾指针指向p结点
Q.rear = p; //把p结点设为下次要用的rear指针
return OK;
3、链队的出队
Status DeleQueue (LinkQueue &Q,QElemType &e) {
p = new QNode;
if (Q.rear = Q.front) {
return ERROR; //空链队
}
p = Q.front->next; //p指向对头结点
e = p ->data; //e保存对头结点的值
Q.front ->next = p ->next; //修改头结点的指针域
if (p==Q.rear) {
Q.rear = Q.front;
}
delete p;
return OK;
4、链队取对头元素
SElemType GetHead (SQueue Q) {
if (Q.rear ==Q.front) {
return ERROR;
}
return Q.front->next ->data;
}
5、JAVA使用单链表实现队列
package queue;
/**
* 基于链表实现的队列
*/
public class QueueBasedOnLinkedList {
// 队列的队首和队尾
private Node head = null;
private Node tail = null;
// 入队
public void enqueue(String value) {
if (tail == null) {
Node newNode = new Node(value, null);
head = newNode;
tail = newNode;
} else {
tail.next = new Node(value, null);
tail = tail.next;
}
}
// 出队
public String dequeue() {
if (head == null) return null;
String value = head.data;
head = head.next;
if (head == null) {
tail = null;
}
return value;
}
public void printAll() {
Node p = head;
while (p != null) {
System.out.print(p.data + " ");
p = p.next;
}
System.out.println();
}
private static class Node {
private String data;
private Node next;
public Node(String data, Node next) {
this.data = data;
this.next = next;
}
public String getData() {
return data;
}
}
}
小结:
- 栈和队列都是动态集合,且在其上进行DELETE操作所移除的元素都是预先设定的。
- 在栈stack中,被删除的是最近插入的元素:栈实现的是一种后进先出(last-in, first-out, LIFO)策略。
- 在队列(queue)中,被删去的总是在集合中存在时间最长的那个元素:队列实现的是一种先进先出(first-in, first-out,FIFO)策略。
- 在数组实现队列的时候,会有数据搬移操作,要想解决数据搬移的问题,我们就,需要像环一样的循环队列。要想写出没有bug的循环队列实现代码,关键要确定好队空和队满的,判定条件。
- 栈是先入后出,队列是先入先出,各有特点!
- 点赞 1
- 收藏
- 分享
- 文章举报
 Erase Me
发布了13 篇原创文章 · 获赞 4 · 访问量 284
私信
关注
Erase Me
发布了13 篇原创文章 · 获赞 4 · 访问量 284
私信
关注

- 数据结构与算法 - 栈和队列
- 数据结构与算法-----队列-使用数组(顺序结构)实现
- 数据结构与算法之栈和队列
- javascript数据结构与算法---队列
- 【数据结构与算法】基本数据结构——队列的链式表示
- 【数据结构与算法】第二章 数组、链表、栈和队列(基础)
- 数据结构与算法JavaScript - 队列
- 数据结构与算法——循环队列链式队列
- 第七周【项目1】数据结构之自建算法库——顺序环形队列
- PTA 数据结构与算法 7-22 堆栈模拟队列
- 数据结构-单链队列相关操作算法
- 【数据结构与算法基础】以数组实现的循环队列 / Circular Queue implemented by array
- Java数据结构与算法解析(十三)——优先级队列
- 【数据结构与算法】十七 栈 队列
- 五、数据结构与算法--栈及队列
- 数据结构与算法---栈和队列
- 数据结构与算法 JavaScript实现 —— 队列(模拟发票,按票价排队)
- 【数据结构与算法】基本数据结构——队列的顺序表示
- 再回首,数据结构——链队列上的其它一些算法
- 数据结构与算法之栈和队列小结