scrapy完成爬取内容的入库操作(mongodb数据库)(windows下)
2020-03-05 11:32
856 查看
一.下载并安装mongodb
详情见其他帖子这里就不加以叙述
二.在settings中打开PIPELINES并把数据库相应配置写入
ITEM_PIPELINES = {
'<spider_name>.pipelines.DouluodaluPipeline': 300,
}
MONGODB_HOST = '127.0.0.1'
# 端口号,默认27017
MONGODB_PORT = 27017
# 设置数据库名称
MONGODB_DBNAME = 'douluodalu'
# 存放本数据的表名称
MONGODB_DOCNAME = 'douluodalu'
三.修改pipelines文件
import pymongo from scrapy.utils.project import get_project_settings settings = get_project_settings() class DouluodaluPipeline(object): def __init__(self): # 获取setting主机名、端口号和数据库名称 host = settings['MONGODB_HOST'] port = settings['MONGODB_PORT'] dbname = settings['MONGODB_DBNAME'] # 创建数据库连接 client = pymongo.MongoClient(host=host,port=port) # 指向指定数据库 mdb = client[dbname] # 获取数据库里面存放数据的表名 self.post = mdb[settings['MONGODB_DOCNAME']] def process_item(self, item, spider): data = dict(item) # 向指定的表里添加数据 self.post.insert(data) return item
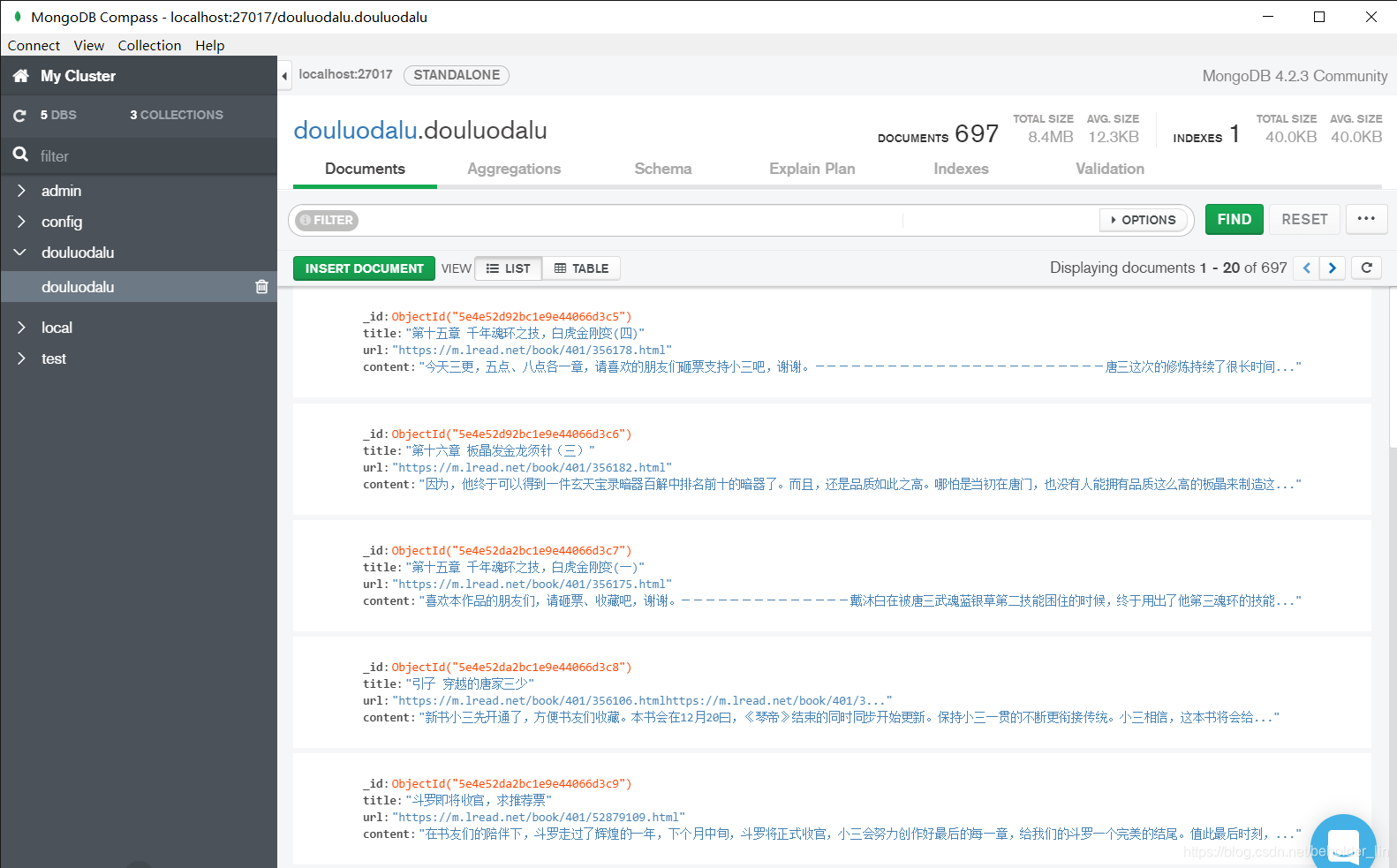
之后运行爬虫,在命令行中或其他 MongoDB GUI中查看数据是否入库
- 点赞
- 收藏
- 分享
- 文章举报
 beholder_lin
发布了2 篇原创文章 · 获赞 0 · 访问量 75
私信
关注
beholder_lin
发布了2 篇原创文章 · 获赞 0 · 访问量 75
私信
关注

相关文章推荐
- scrapy完成爬取内容的入库操作(mongodb数据库)。(windows下)
- 如何在Linux下操作Windows分区内容
- python爬虫-利用scrapy框架完成天天书屋内容爬取,并保存本地txt
- windows下使用python的scrapy爬虫框架,爬取个人博客文章内容信息
- 7、使用IO流读取指定文件内容,并完成相关操作
- windows磁盘上没有足够空间完成此操作
- 磁盘上没有足够的空间完成此操作的解决办法_Windows小知识
- win10总是自动删除Windows和Office激活工具KMSELDI.exe,提示无法成功完成操作,因为文件包含病毒或潜在的垃圾软件
- Windows上php5.6操作mongodb数据库示例【配置、连接、获取实例】
- ContentProvider学习心得(中)--通过单元测试的方式完成对通讯录内容的操作
- Windows_Postgresql相关操作内容
- 在Windows 8.1下 安装基于Python 3.5.2的 Scrapy 框架 !已安装完成
- windows搜索时提示“意外错误 操作无法完成”的解决方法(利用注册表)
- Scrapy的安装--------Windows、linux、mac等操作平台
- windows 2003安装完成后必须操作!
- python scrapy 在pipeline 把爬取内容写入MongoDB数据库
- Python网络爬虫(八):Scrapy中MongoDB数据库的简单使用(windows)
- Windows系统搜索功能提示"意外错误,操作无法完成"解决办法
- 5步轻松搞定windows系统下mysql命令行操作,完成简单mysql配置
- windows完成端口 等待客户端发送一次消息才能完成AcceptEx操作的解决方法