XDL: An Industrial Deep Learning Framework for High-dimensional Sparse Data 论文笔记
本文的github地址: https://github.com/alibaba/x-deeplearning
X-Deep Learning(简称XDL)于2018年12月由阿里巴巴开源,是面向高维稀疏数据场景(如广告/推荐/搜索等)深度优化的一整套解决方案。以填补 TensorFlow、PyTorch 等现有开源深度学习框架主要面向图像、语音等低维稠密数据的不足。目前只支持ubuntu系统
摘要:
随着数据和计算能力的快速增长,基于深度学习的方法已成为许多人工智能问题(例如图像分类,语音识别和计算机视觉)的主要解决方案。包括Tensorflow,MxNet和PyTorch在内的几个的深度学习(DL)框架已开源。但是,现有的DL框架不是为涉及高维稀疏数据的应用程序而设计的,在许多成功的在线业务(例如搜索引擎,推荐系统和在线广告)中,这类数据广泛存在。在这些工业场景中,通常在具有多达数十亿个稀疏特征和数千亿个样本的大规模数据集上训练深度模型,这给DL框架带来了巨大挑战。在本文中,我们介绍了一个名为XDL的高性能,大规模和分布式DL框架,该框架提供了一种优秀的解决方案,可以填补现有DL框架的一般设计与高维稀疏数据引起的工业需求之间的差距。自2016年以来,XDL已成功部署在阿里巴巴,服务于许多产品,例如在线广告和推荐系统。XDL可以并行运行在数百个GPU卡上,可以在几个小时内训练具有数百亿个参数的深度模型。除了出色的性能和灵活性外,XDL还对开发人员友好。 阿里巴巴的算法科学家仅需几行简单代码即可开发和部署新的深度模型。
引言:
尽管现有的深度学习框架在许多领域都取得了巨大的成功,但它们并不是为涉及高维稀疏数据的应用而设计的。高维稀疏数据广泛存在于许多Internet规模的应用程序中,例如搜索引擎,推荐系统和在线广告。从该数据中提取的训练样本包含数十亿个特征,而对于每个样本,这些维度中只有少数是非零的。
XDL,它是一种高性能,大规模,分布式的深度学习框架,旨在用于学习涉及高维稀疏数据的任务。在稀疏的功能学习部分,XDL提供了精心设计的分布式系统,并对I / O,数据管道,通信和GPU进行了深度优化,从而提供了极高的效率和可扩展性。用户可以使用嵌入词典(embedding dictionary)或深层模型(例如CNN / RNN)将稀疏特征或图像/文本特征映射为密集(dense)表示。在密集模型学习(dense model learning)部分,XDL通过名为桥接(bridging)的全新技术无缝地采用任何开源深度学习框架作为其后端。在实际数据集上评估XDL时,我们发现它的运行速度比Tensorflow / MxNet的本机分布式版本至少快5倍。XDL运行在数百台服务器上,仅几个小时即可训练出数多个参数达数百亿的模型。除了性能和灵活性外,XDL还致力于向用户隐藏复杂的工程细节。使用XDL,算法科学家仅需几行简单代码即可开发和部署新模型。这样的系统设计带来了灵活性,并解锁了许多算法创新。
相关工作:
TensorFlow,MxNet和Caffe等传统解决方案通常在单台机器上运行,为分布式训练提供有限的支持。即使有多个GPU,那些单机解决方案很难处理模型训练具有1011个样本和10 10个参数。
3、XDL结构:
3.1 具有高维稀疏数据的深度模型的网络特性
Embedding & MLP架构激发了以下大部分工作来设计深度模型,这些模型具有来自各种应用程序的高维稀疏输入,例如视频推荐,Web搜索和电子商务网站中的广告。Embedding & MLP从稀疏数据中学习通常分成两个步骤:1)表示学习,可从高维稀疏输入中捕获信息并将其嵌入到低维空间中。2)函数拟合。为简单起见,在本文的其余部分中,我们将第一步的网络称为SparseNet,将第二步的网络称为DenseNet。 下图进行了说明。
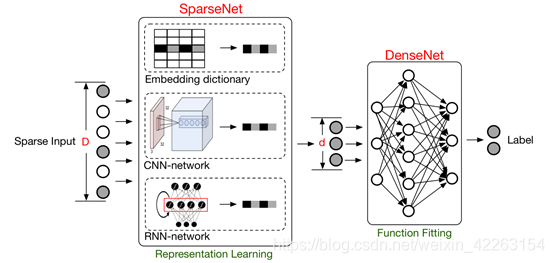
3.2 XDL的设计理念与桥接方法
DenseNet由几个dense层组成,需要本地计算机上较高的计算密度。 包括Tensorflow,MxNet和Pytorch在内的多个DL框架具有开源,这样的密集网络可以在这些框架中很好地处理。但是,SparseNet包含从原始样本生成的数千亿个特征。因此,一个成功的可以处理这种情况的DL框架必须具有出色的分布特性和足够的稀疏数据计算能力。现有DL框架并不是针对涉及高维稀疏数据的网络而精心设计的。表1显示了我们的展示广告系统在一天中使用的典型生产数据量。

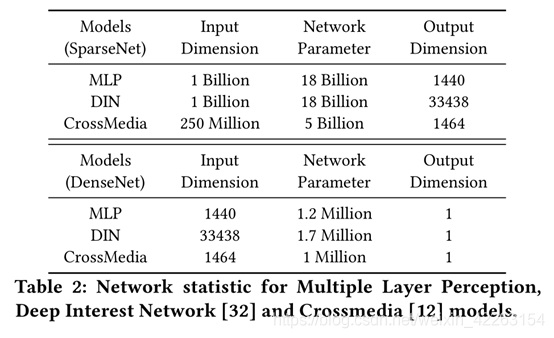
表2显示了我们日常任务中使用的某些模型的网络参数统计信息。显然,正是SparseNet导致了这些模型的大部分困难。SparseNet需要处理兆兆字节的输入数据的实际I / O问题以及复杂而繁重的并行性问题。这些挑战使SparseNet的训练与DenseNet的训练截然不同且同样关键。
XDL体系结构如图2所示。我们提出了一种全新的桥接体系结构,其中,训练系统与两个主要子系统桥接:
Advanced Model Server (AMS)。AMS提供了精心设计的分布式系统,该系统为训练SparseNet提供了极高的效率和可扩展性。 AMS可处理大规模稀疏输入的快速发展的表示学习算法。 支持嵌入字典和模型(例如CNN / RNN),以将大型稀疏输入映射为密集向量。
Backend Worker (BW) . BW遵循通用的深度学习设置,以从低维输入中学习,并允许采用任何开源DL框架作为其后端。 有了这种灵活性,我们的算法科学家就可以轻松地尝试涉及DNN,注意力机制或门控循环单元(GRU)的新模型结构,以对复杂且不断发展的用户行为进行建模。

评估:
在以下评估中,我们选择Tensorflow作为XDL的计算后端。
可扩展性:
我们还测试了XDL的可伸缩性,并将其与使用80个AMS的各种数量的工作器上的本机TensorFlow进行比较。 同样,每个进程使用8个CPU内核,每个AMS使用96个CPU内核。XDL和Tensorflow均使用无锁样式异步更新。 结果如图8所示。由于XDL对通讯和重复功能进行了优化,因此XDL始终能够保持更好的性能。由于我们确定了AMS的数量,因此在异步模式下运行时,我们几乎实现了线性扩展。
- 点赞
- 收藏
- 分享
- 文章举报
 夜月魂whysky
发布了5 篇原创文章 · 获赞 1 · 访问量 63
私信
关注
夜月魂whysky
发布了5 篇原创文章 · 获赞 1 · 访问量 63
私信
关注

- [论文笔记]Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
- 【论文笔记】Deep High-Resolution Representation Learning for Human Pose Estimation
- DeepSense: a Unified Learning Framework for Time-Series Mobile Sensing Data Processing 论文笔记
- [论文阅读笔记] DeepNeuron: An Open Deep Learning Toolbox for Neuron Tracing
- An Entropy Weighting k-Means Algorithm for Subspace Clustering of High-Dimensional Sparse Data
- 论文笔记——Deep Residual Learning for Image Recognition
- 论文笔记 A Large Contextual Dataset for Classification,Detection and Counting of Cars with Deep Learning
- 论文笔记——Data-free Parameter Pruning for Deep Neural Networks
- 论文笔记 Ensemble of Deep Convolutional Neural Networks for Learning to Detect Retinal Vessels in Fundus
- 论文阅读:Deep High-Resolution Representation Learning for Human Pose Estimation
- 论文笔记:Parallel Tracking and Verifying: A Framework for Real-Time and High Accuracy Visual Tracking
- 论文笔记:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
- cuDNN: efficient Primitives for Deep Learning 论文阅读笔记
- 【论文笔记】Margin Sample Mining Loss: A Deep Learning Based Method for Person Re-identification
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
- 论文笔记:Personalized Tag Recommendation for Images Using Deep Transfer Learning
- 论文笔记 | Learning Deep Features for Discriminative Localization
- 论文笔记之---Learning Deep Feature Representations with Domain Guided Dropout for Person Re-identificatio
- 多任务学习-An Overview of Multi-Task Learning in Deep Neural Networks论文笔记
- 论文笔记之Learning Deep Representations for Graph Clustering