机器学习中的距离/散度/熵
2020-02-03 04:52
330 查看
一、信息量
- 定义:用一个信息的编码长度。
- 性质:编码长度与出现的概率成负相关。(如:哈夫曼编码)
- 公式(0/1编码)
I=log2(1p(x))=−log2(p(x))I=\log_2(\frac{1}{p(x)})=-\log_2(p(x))I=log2(p(x)1)=−log2(p(x))
二、信息熵
- 定义:一个分布的信息量。(编码的平均长度/信息量的均值)
- 公式
H(p)=∑xp(x)log2(1p(x))=−∑xp(x)log2(p(x))H(p)=\sum_x{p(x)log_2(\frac{1}{p(x)})}=-\sum_x{p(x)\log_2(p(x))}H(p)=x∑p(x)log2(p(x)1)=−x∑p(x)log2(p(x))
三、交叉熵 cross-entropy
- 定义:用猜测的分布(p)(p)(p)的编码方式 编码 真实的分布(q)(q)(q),得到的平均编码长度/信息量均值。
因为参考的博客公式推导有冲突,有人认为p为真实分布,我暂且认为q为真实分布。\color{red}{因为参考的博客公式推导有冲突,有人认为p为真实分布,我暂且认为q为真实分布。}因为参考的博客公式推导有冲突,有人认为p为真实分布,我暂且认为q为真实分布。 - 公式
Hp(q)=∑xq(x)log2(1p(x))H_p(q)=\sum_x{q(x)\log_2(\frac{1}{p(x)})}Hp(q)=x∑q(x)log2(p(x)1) - 意义:不同分布之间的距离度量。
- 应用:最后的损失函数。(交叉熵 本质上相当于衡量两个编码方式之间的差值,只有当猜测的分布约接近于真实分布,其值越小)
具体说明,详见 信息量,信息熵,交叉熵,KL散度和互信息(信息增益),没太懂,以后遇到再细看\color{red}{没太懂,以后遇到再细看}没太懂,以后遇到再细看。
四、KL散度(相对熵)
- 别名:KL距离、相对熵。(D(q∣∣p)、Dq(p):q对p的相对熵D(q||p)、D_q(p):q对p的相对熵D(q∣∣p)、Dq(p):q对p的相对熵)
- 公式(相对熵=交叉熵-信息熵)
Dq(p)=Hq(p)−H(p)=∑xp(x)log2(p(x)q(x))D_q(p)=H_q(p)-H(p)=\sum_x{p(x)\log_2(\frac{p(x)}{q(x)})}Dq(p)=Hq(p)−H(p)=x∑p(x)log2(q(x)p(x)) - 意义:同一随机事件+不同分布 间的距离度量。
- 图示
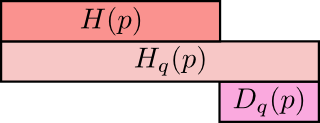
- 性质(非负性):Dq(p)≥0D_q(p)\geq0Dq(p)≥0。
四、联合信息熵和条件信息熵
-
公式
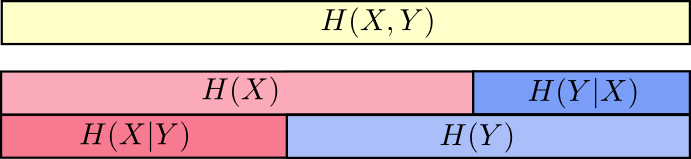
a. 联合信息熵
H(X,Y)=∑x,yp(x,y)log2(1p(x,y))H(X,Y)=\sum_{x,y}p(x,y)\log_2(\frac{1}{p(x,y)})H(X,Y)=x,y∑p(x,y)log2(p(x,y)1)
b. 条件信息熵
H(Y∣X)=H(X,Y)−H(X)H(Y|X)=H(X,Y)-H(X)H(Y∣X)=H(X,Y)−H(X)
=∑xp(x)∑yp(y∣x)log2(1p(y∣x))=\sum_xp(x)\sum_yp(y|x)\log_2(\frac{1}{p(y|x)})=x∑p(x)y∑p(y∣x)log2(p(y∣x)1)
=∑x,yp(x,y)log2(1p(y∣x))=\sum_{x,y}p(x,y)\log_2(\frac{1}{p(y|x)})=x,y∑p(x,y)log2(p(y∣x)1) -
意义:联合分布是 同一个分布中 两变量相互影响的关系。
-
图示
五、互信息(信息增益)
- 定义:一个联合分布中 两个信息的纠缠程度/相互影响那部分的信息量
- 公式
I(X,Y)=H(X)+H(Y)−H(X,Y)I(X,Y)=H(X)+H(Y)-H(X,Y)I(X,Y)=H(X)+H(Y)−H(X,Y)
=H(Y)−H(Y∣X)=H(Y)-H(Y|X)=H(Y)−H(Y∣X) - 性质(非负性):I(X,Y)≥0I(X,Y)\geq0I(X,Y)≥0。
- 图示
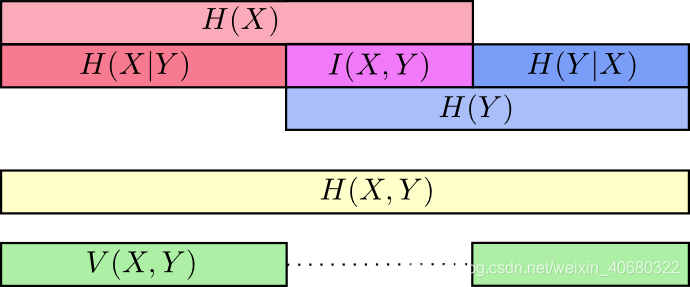
- 应用:决策树。
六、variation of information
- 定义:联合分布(即同一个分布)两个变量相互影响的关系 。
- 公式
V(X,Y)=H(X,Y)−I(X,Y)V(X,Y)=H(X,Y)-I(X,Y)V(X,Y)=H(X,Y)−I(X,Y) - 意义:度量 不同随机变量间的差别。
V(X,Y)=0V(X,Y)=0V(X,Y)=0:说明这两个变量完全一致。
V(X,Y)V(X,Y)V(X,Y)值越大 说明两个变量越独立。
信息量,信息熵,交叉熵,KL散度和互信息(信息增益)
KL散度、JS散度、Wasserstein距离
一文搞懂散度(KL,MMD距离、Wasserstein距离)
- 点赞
- 收藏
- 分享
- 文章举报
 梁小娘子
发布了36 篇原创文章 · 获赞 0 · 访问量 544
私信
关注
梁小娘子
发布了36 篇原创文章 · 获赞 0 · 访问量 544
私信
关注

相关文章推荐
- 机器学习系列(14)_SVM碎碎念part2:SVM中的向量与空间距离
- Finding Similar Items 文本相似度计算的算法——机器学习、词向量空间cosine、NLTK、diff、Levenshtein距离
- 机器学习中的距离
- 机器学习中的各种距离
- 机器学习中的分类距离
- 机器学习中距离和相似性度量方法
- 漫谈:机器学习中距离和相似性度量方法
- 漫谈:机器学习中距离和相似性度量方法
- 机器学习两种距离——欧式距离和马氏距离
- 机器学习中的各种距离总结
- 机器学习笔记八:常见“距离”归纳
- [ 人工智能]模式识别、机器学习、数据挖掘当中的各种距离总结
- 数据挖掘/机器学习 之 距离测度
- 漫谈:机器学习中距离和相似性度量方法
- 机器学习实战2(1):KNN算法与iris数据实现、利用欧式距离手动实现KNN
- 【转】机器学习中距离和相似性度量方法
- 漫谈:机器学习中距离和相似性度量方法
- 机器学习(六)分类模型--线性判别法、距离判别法、贝叶斯分类器
- 机器学习中的各种距离
- 机器学习中各种距离计算