LPL2019职业联赛春季+夏季赛数据分析
2020-02-02 17:25
1506 查看
分析需求1:出场次数最多的10位英雄
分析需求2:胜场次数最多的10位英雄
分析需求3:分析所有英雄的胜率,并取出前10进行图表展示
分析需求4:每个位置的出场英雄数饼图分析
分析需求5:选手UZI的英雄池分析
分析需求6:每个位置胜率最高的英雄
分析需求1:出场次数最多的10位英雄
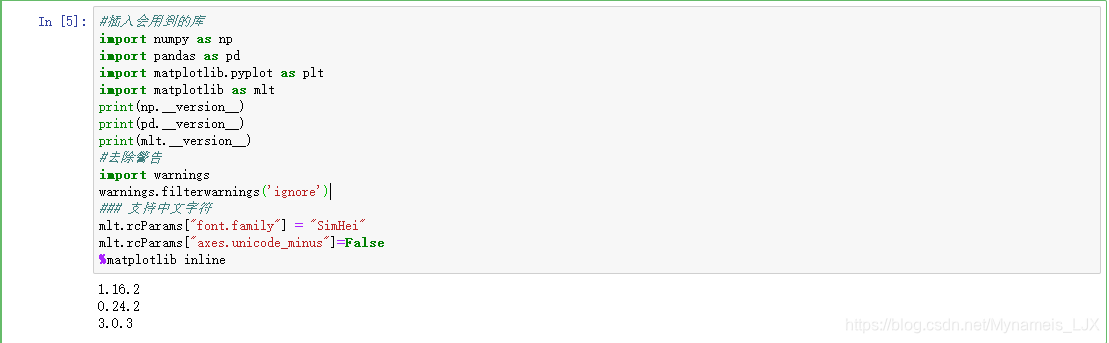
#插入会用到的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mlt
print(np.__version__)
print(pd.__version__)
print(mlt.__version__)
#去除警告
import warnings
warnings.filterwarnings('ignore')
### 支持中文字符
mlt.rcParams["font.family"] = "SimHei"
mlt.rcParams["axes.unicode_minus"]=False
%matplotlib inline
思路:
1.数据导入及清洗;
2.取出需要的字段部分;
3.将所有字段压平成一列字段,并对value进行计数;
4.取出value数量top10,并画出直方图.
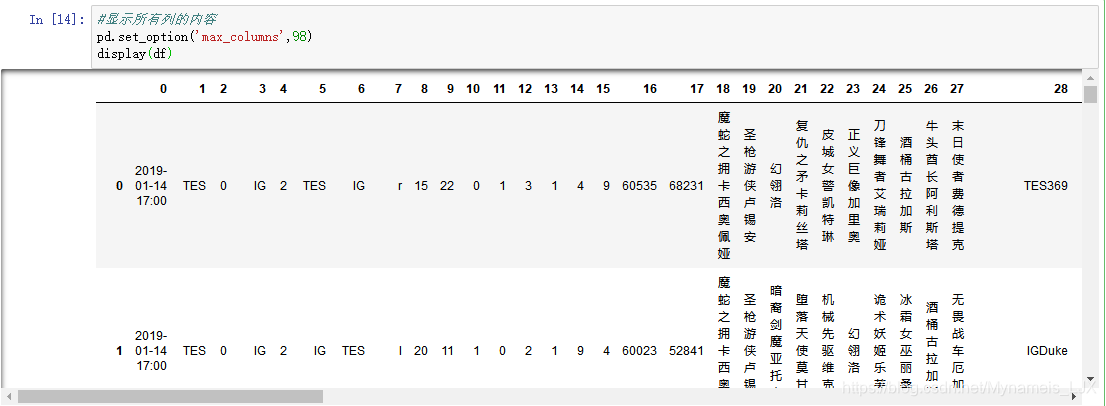
df = pd.read_csv('lol_games_2019.csv',header = None,sep = ',')
display(df)

#显示所有列的内容
pd.set_option('max_columns',98)
display(df)
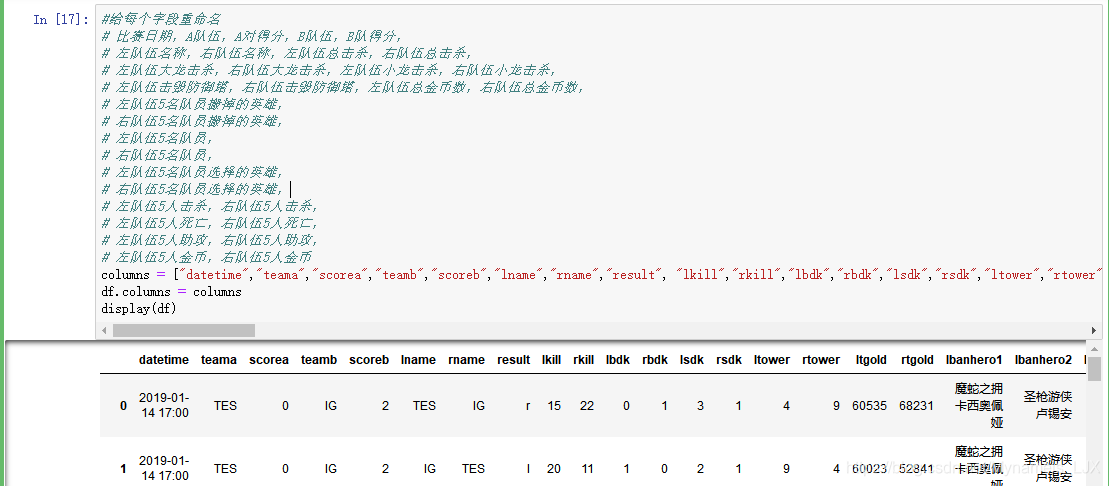
#给每个字段重命名 # 比赛日期,A队伍,A对得分,B队伍,B队得分, # 左队伍名称,右队伍名称,左队伍总击杀,右队伍总击杀, # 左队伍大龙击杀,右队伍大龙击杀,左队伍小龙击杀,右队伍小龙击杀, # 左队伍击毁防御塔,右队伍击毁防御塔,左队伍总金币数,右队伍总金币数, # 左队伍5名队员搬掉的英雄, # 右队伍5名队员搬掉的英雄, # 左队伍5名队员, # 右队伍5名队员, # 左队伍5名队员选择的英雄, # 右队伍5名队员选择的英雄, # 左队伍5人击杀,右队伍5人击杀, # 左队伍5人死亡,右队伍5人死亡, # 左队伍5人助攻,右队伍5人助攻, # 左队伍5人金币,右队伍5人金币 columns = ["datetime","teama","scorea","teamb","scoreb","lname","rname","result", "lkill","rkill","lbdk","rbdk","lsdk","rsdk","ltower","rtower","ltgold","rtgold","lbanhero1","lbanhero2","lbanhero3","lbanhero4","lbanhero5","rbanhero1","rbanhero2","rbanhero3","rbanhero4","rbanhero5","ltm1","ltm2","ltm3","ltm4","ltm5","rtm1","rtm2","rtm3","rtm4","rtm5","lpickhero1","lpickhero2","lpickhero3","lpickhero4","lpickhero5","rpickhero1","rpickhero2","rpickhero3","rpickhero4","rpickhero5","lkill1","lkill2","lkill3","lkill4","lkill5","rkill1","rkill2","rkill3","rkill4","rkill5","ldead1","ldead2","ldead3","ldead4","ldead5","rdead1","rdead2","rdead3","rdead4","rdead5","lassist1","lassist2","lassist3","lassist4","lassist5","rassist1","rassist2","rassist3","rassist4","rassist5","lgold1","lgold2","lgold3","lgold4","lgold5","rgold1","rgold2","rgold3","rgold4","rgold5","lsoldier1","lsoldier2","lsoldier3","lsoldier4","lsoldier5","rsoldier1","rsoldier2","rsoldier3","rsoldier4","rsoldier5"] df.columns = columns display(df)
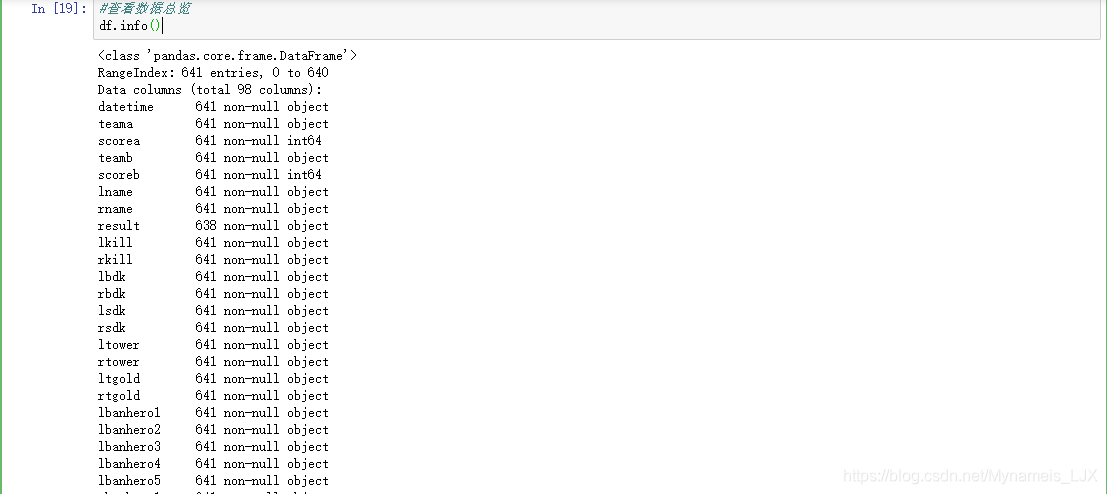
#查看数据总览 df.info()



#result和lpickhero1字段存在3行空值 df[df['lpickhero1'].isnull()]
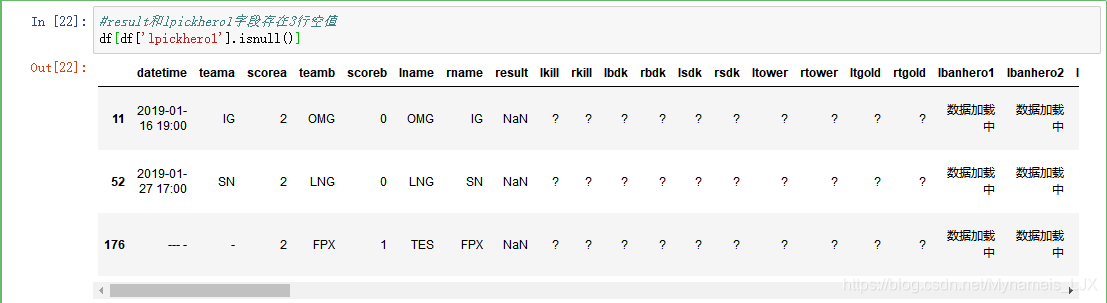
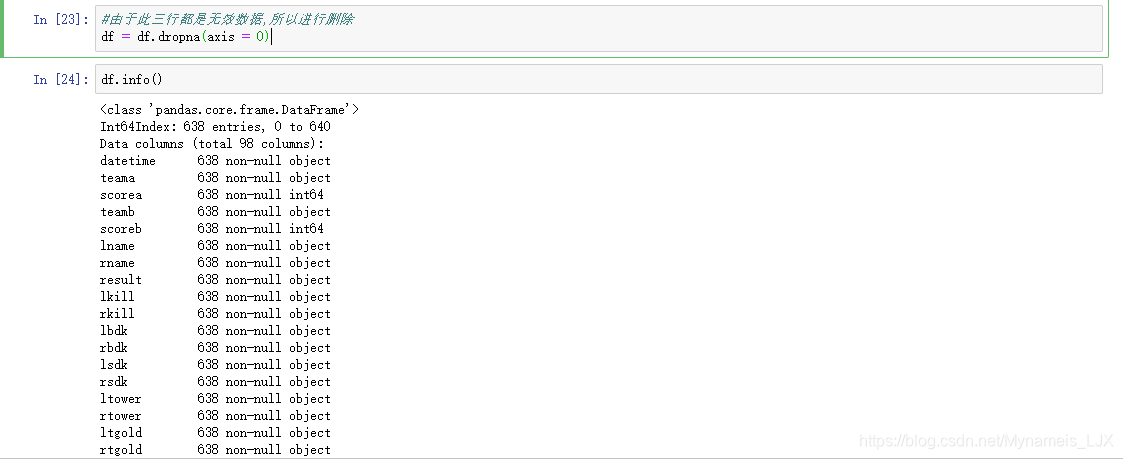
#由于此三行都是无效数据,所以进行删除 df = df.dropna(axis = 0) df.info()
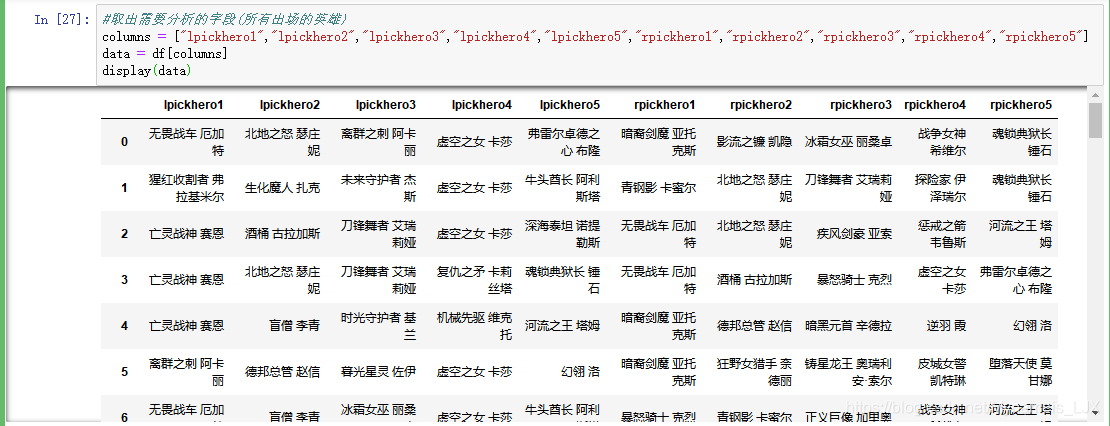
#取出需要分析的字段(所有出场的英雄) columns = ["lpickhero1","lpickhero2","lpickhero3","lpickhero4","lpickhero5","rpickhero1","rpickhero2","rpickhero3","rpickhero4","rpickhero5"] data = df[columns] display(data)
#将所有字段进行压平,形成汇总成一个字段(一列)
data_array = data.values.flatten()
hero_list = pd.DataFrame(data_array)
#将唯一的字段进行重命名
hero_list.columns = ['hero_name']
#计算每个英雄的出场次数
hero_count = hero_list['hero_name'].value_counts()
display(hero_count)
#也可以这么写
# hero_count = hero_list.groupby('hero_name').size().sort_values(ascending= False)
# display(hero_count)

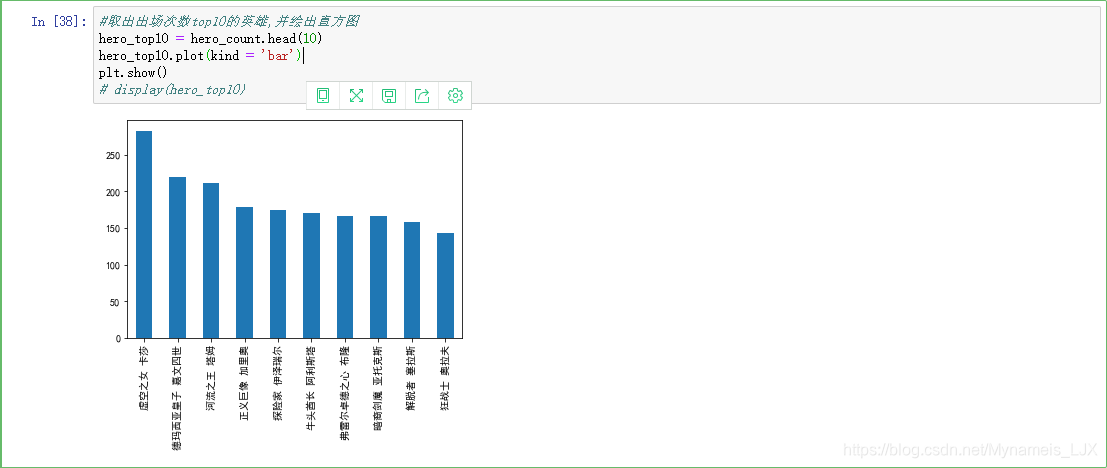
#取出出场次数top10的英雄,并绘出直方图 hero_top10 = hero_count.head(10) hero_top10.plot(kind = 'bar') plt.show() # display(hero_top10)
分析需求2:胜场次数最多的10位英雄
思路 :
1.将r方或者l方胜利的五位英雄提取出来;
2.将提取出来的两个表的字段名进行统一命名,并且组合成一个表;
3,将组合成的表进行压平;
4.进行数据处理并绘出直方图.
#胜负的表现形式: result字段为r时,r方胜,否则l方胜 df['result'].head(5)

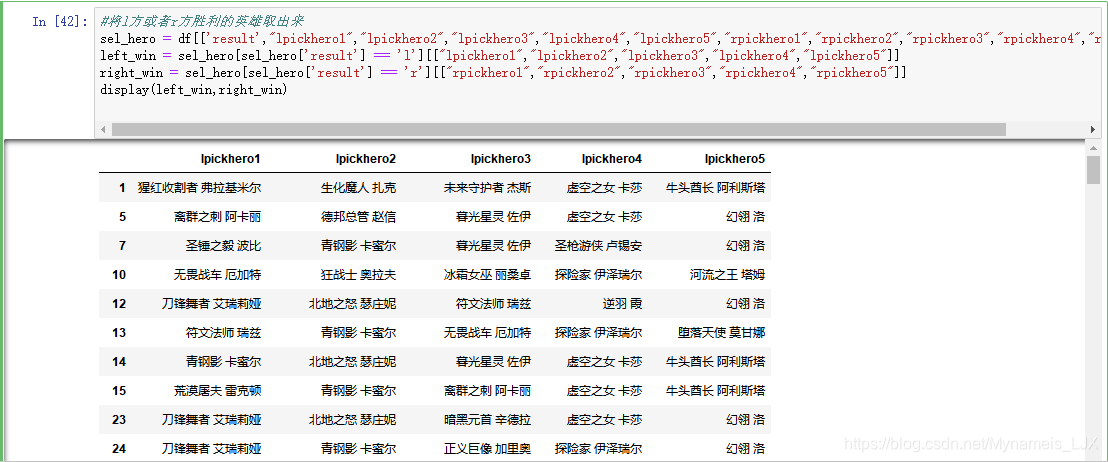
#将l方或者r方胜利的英雄取出来 sel_hero = df[['result',"lpickhero1","lpickhero2","lpickhero3","lpickhero4","lpickhero5","rpickhero1","rpickhero2","rpickhero3","rpickhero4","rpickhero5"]] left_win = sel_hero[sel_hero['result'] == 'l'][["lpickhero1","lpickhero2","lpickhero3","lpickhero4","lpickhero5"]] right_win = sel_hero[sel_hero['result'] == 'r'][["rpickhero1","rpickhero2","rpickhero3","rpickhero4","rpickhero5"]] display(left_win,right_win)
#对提取出来的两个表的字段进行统一,并进行合并 left_win.columns = ['pickhero1','pickhero2','pickhero3','pickhero4','pickhero5'] right_win.columns = ['pickhero1','pickhero2','pickhero3','pickhero4','pickhero5'] win_hero = pd.concat((left_win,right_win)) display(win_hero)

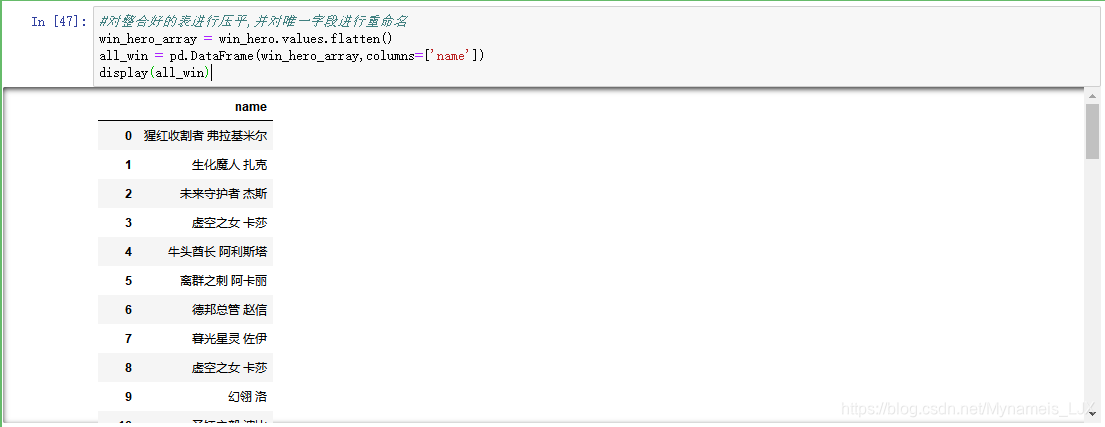
#对整合好的表进行压平,并对唯一字段进行重命名 win_hero_array = win_hero.values.flatten() all_win = pd.DataFrame(win_hero_array,columns=['name']) display(all_win)
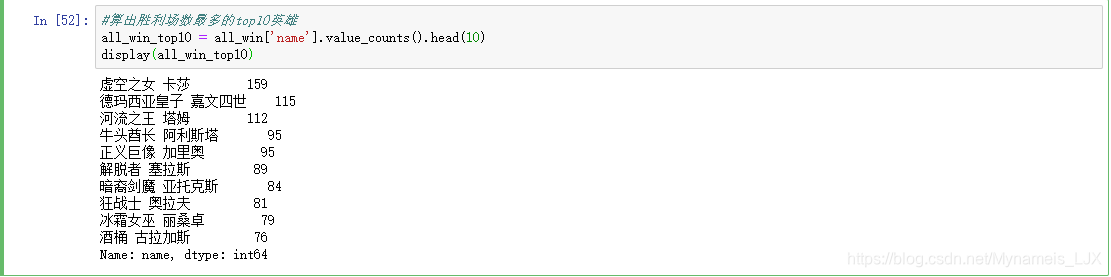
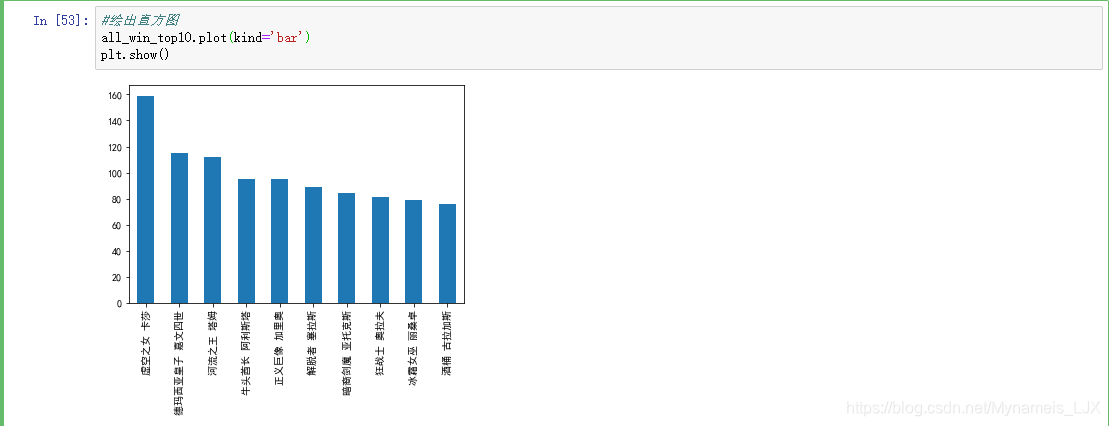
#算出胜利场数最多的top10英雄 all_win_top10 = all_win['name'].value_counts().head(10) display(all_win_top10)
#绘出直方图 all_win_top10.plot(kind='bar') plt.show()
分析需求3:分析每个英雄的胜率以及胜率排行top10
思路:
1.求出胜利场次的所有英雄 --result_hero[‘name’].value_counts()
2.求出胜利场次的所有英雄对应的所有比赛场次 --所有英雄的胜利场次+所有英雄的失败场次 = 所有英雄的所有比赛场次
3.英雄胜率 = 第1点/第2点
#接上面的所有胜利的英雄如下 all_hero_win = all_win['name'].value_counts() display(all_hero_win)

#求出所有英雄失败的场次,方法如分析需求2 left_fail_hero = sel_hero[sel_hero['result'] == 'r'][['lpickhero1',"lpickhero2","lpickhero3","lpickhero4",'lpickhero5']] right_fail_hero = sel_hero[sel_hero['result'] == 'l'][['rpickhero1',"rpickhero2","rpickhero3","rpickhero4",'rpickhero5']] # display(left_fail_hero,right_fail_hero) #将左右两端的字段统一重命名并合并 left_fail_hero.columns = ['pickhero1','pickhero2','pickhero3','pickhero4','pickhero5'] right_fail_hero.columns = ['pickhero1','pickhero2','pickhero3','pickhero4','pickhero5'] all_fail = pd.concat((left_fail_hero,right_fail_hero)) display(all_fail)

#对所有的失败英雄二维表进行压平,并计数
fail_hero_array = all_fail.values.flatten()
fail_hero = pd.DataFrame(fail_hero_array,columns={'name'})
all_hero_fail = fail_hero['name'].value_counts()
display(all_hero_fail)

#所有英雄总场次 all_hero_win+all_hero_fail

#根据每个英雄的胜利场次/总场次,求出其top10胜率的英雄 all_hero_result = pd.concat((all_hero_win,all_hero_fail),axis=1) #将NaN值填充为0,并将all_hero_result进行重命名 all_hero_result.fillna(0,inplace = True) all_hero_result.columns = ['victory','failure'] #all_hero_result添加一个字段vic_rate(胜率) all_hero_result['vic_rate']=all_hero_result['victory']/(all_hero_result['failure']+all_hero_result['victory']) #排序并取出胜率top10英雄 top10_win = all_hero_result['vic_rate'].sort_values(ascending = False).head(10) display(top10_win)
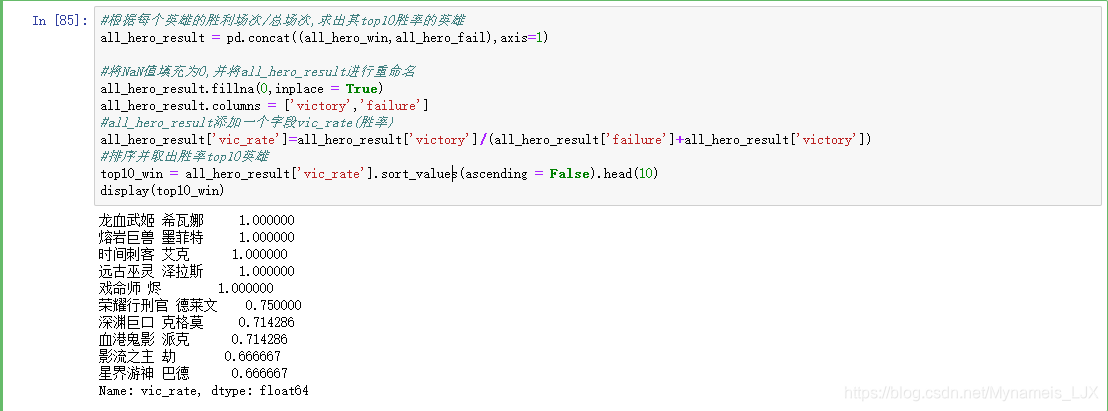
#取出胜率top10的英雄绘出直方图 top10_win.plot(kind = 'bar') plt.show()

分析需求4:每个位置的出场英雄数饼图分析
思路:
1.将所有出场英雄取出(左5个,右5个,合并)
2.将五个位置的英雄单独取出,并作去重计数
3.画出饼图
#英雄列
columns = ["lpickhero1","lpickhero2","lpickhero3","lpickhero4","lpickhero5","rpickhero1","rpickhero2","rpickhero3","rpickhero4","rpickhero5"]
#取出所有的英雄
hero_data = df[columns]
#因为接下来要取到五个对应的英雄位置,所以要对左右的各5个英雄分成2组,然后进行合并成一组
left_data = hero_data[["lpickhero1","lpickhero2","lpickhero3","lpickhero4","lpickhero5"]]
right_data = hero_data[["rpickhero1","rpickhero2","rpickhero3","rpickhero4","rpickhero5"]]
#对两组的所有字段名进行统一
left_data.columns = ['pickhero1','pickhero2','pickhero3','pickhero4','pickhero5']
right_data.columns = ['pickhero1','pickhero2','pickhero3','pickhero4','pickhero5']
total_hero = pd.concat((left_data,right_data))
#对每个位置的英雄单独取出来,进行去重并计数
#top jungle Middle ad support
top = total_hero.groupby('pickhero1').size().count()
jungle = total_hero.groupby('pickhero2').size().count()
middle = total_hero.groupby('pickhero3').size().count()
ad = total_hero.groupby('pickhero4').size().count()
support = total_hero.groupby('pickhero5').size().count()
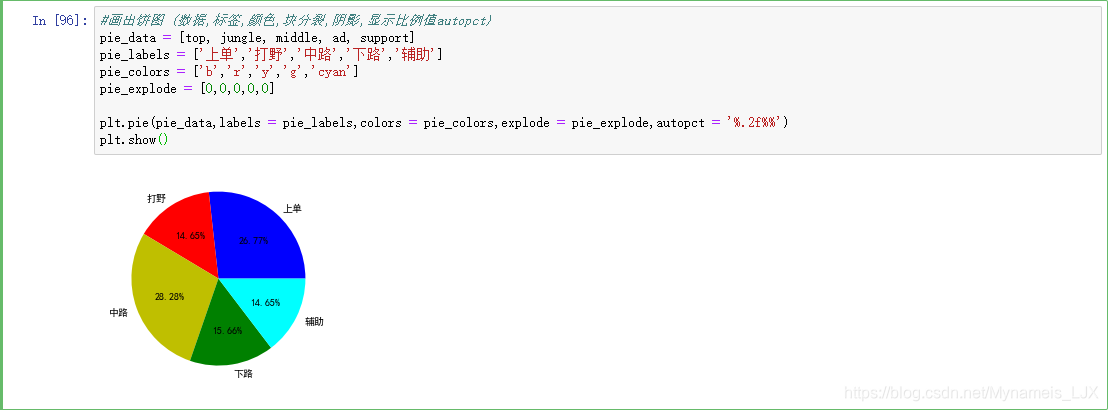
display(top, jungle, middle, ad, support )

#画出饼图 (数据,标签,颜色,块分裂,阴影,显示比例值autopct) pie_data = [top, jungle, middle, ad, support] pie_labels = ['上单','打野','中路','下路','辅助'] pie_colors = ['b','r','y','g','cyan'] pie_explode = [0,0,0,0,0] plt.pie(pie_data,labels = pie_labels,colors = pie_colors,explode = pie_explode,autopct = '%.2f%%') plt.show()
分析需求5:选手UZI的英雄池分析
思路:
1.将UZI的所有场次及其所使用英雄取出来
2.对所有使用的英雄的次数取出来
3.画出饼图
#查看RNG队中uzi的位置 -- 第4位置:ad display(df[df['teama']=='RNG'])

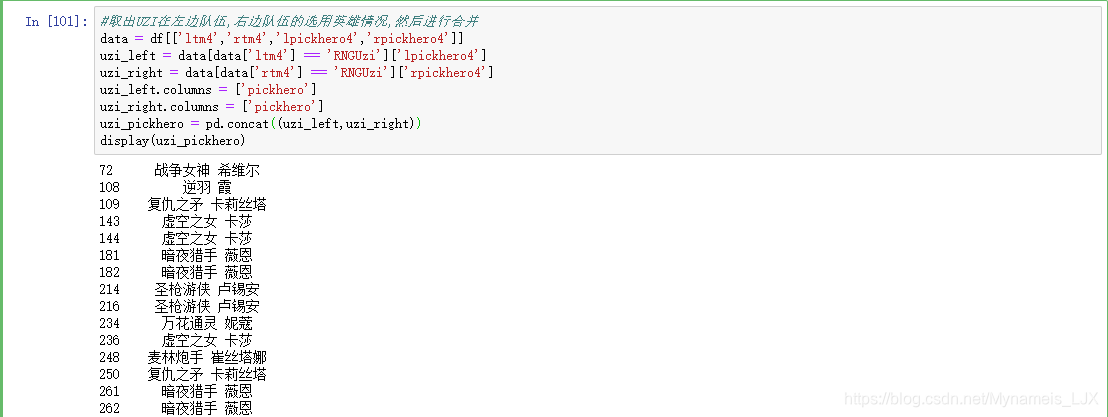
#取出UZI在左边队伍,右边队伍的选用英雄情况,然后进行合并 data = df[['ltm4','rtm4','lpickhero4','rpickhero4']] uzi_left = data[data['ltm4'] == 'RNGUzi']['lpickhero4'] uzi_right = data[data['rtm4'] == 'RNGUzi']['rpickhero4'] uzi_left.columns = ['pickhero'] uzi_right.columns = ['pickhero'] uzi_pickhero = pd.concat((uzi_left,uzi_right)) display(uzi_pickhero)
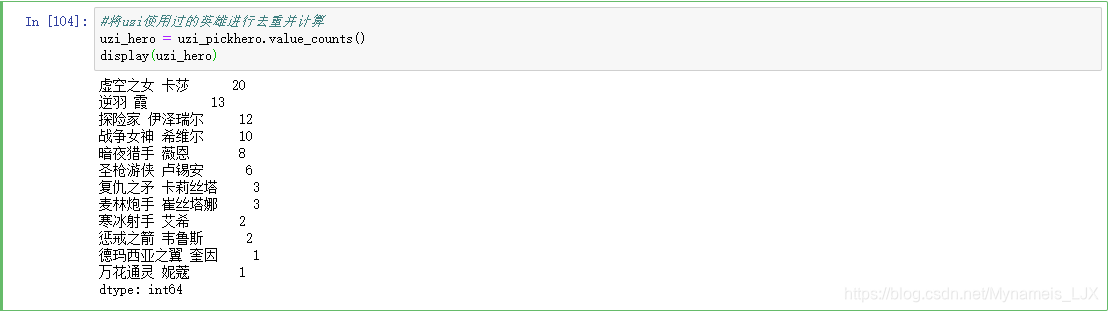
#将uzi使用过的英雄进行去重并计算 uzi_hero = uzi_pickhero.value_counts() display(uzi_hero)
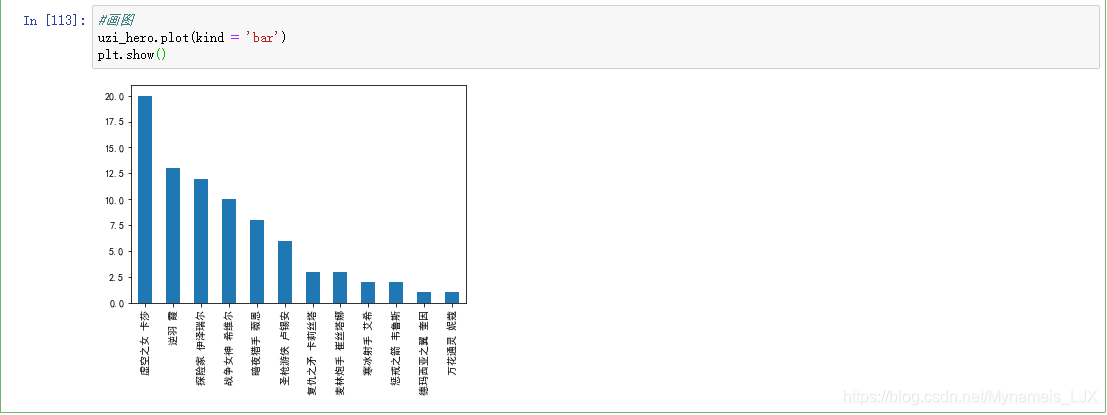
#画图 uzi_hero.plot(kind = 'bar') plt.show()
分析需求6:每个位置胜率最高的英雄
思路:
1.依次求出各个位置所有英雄对应的数量,然后合并成一个表
2.每个英雄加入他的胜率
3.取出各个位置对应的英雄以及他的胜率,然后取出各个位置胜率最高的英雄
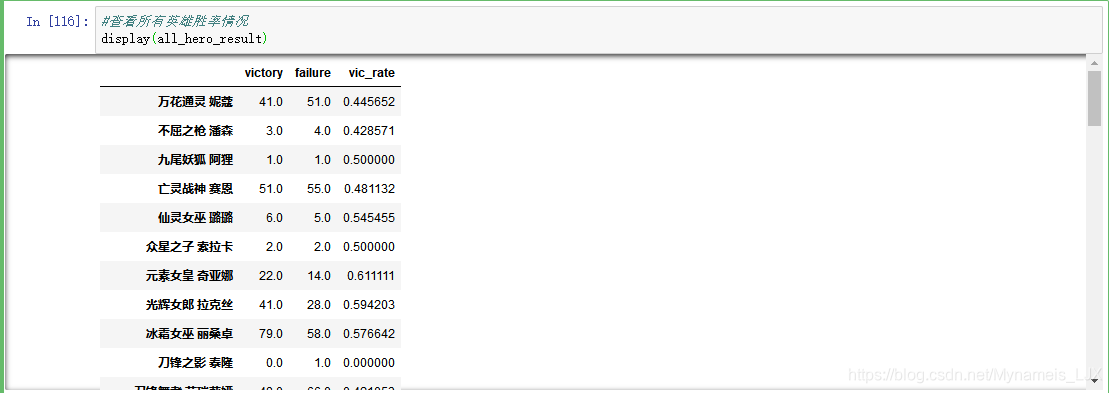
#查看所有英雄胜率情况 display(all_hero_result)
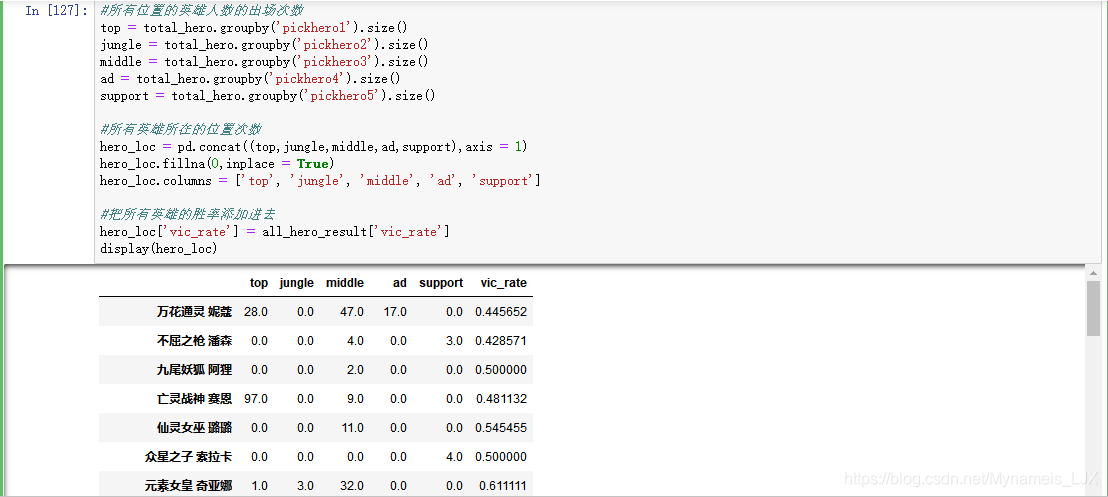
#所有位置的英雄人数的出场次数
top = total_hero.groupby('pickhero1').size()
jungle = total_hero.groupby('pickhero2').size()
middle = total_hero.groupby('pickhero3').size()
ad = total_hero.groupby('pickhero4').size()
support = total_hero.groupby('pickhero5').size()
#所有英雄所在的位置次数
hero_loc = pd.concat((top,jungle,middle,ad,support),axis = 1)
hero_loc.fillna(0,inplace = True)
hero_loc.columns = ['top', 'jungle', 'middle', 'ad', 'support']
#把所有英雄的胜率添加进去
hero_loc['vic_rate'] = all_hero_result['vic_rate']
display(hero_loc)
#将所有有参与top位置的英雄都选出来,标记他的胜率然后进行排名,取出胜率最高的一位,其他位置同理 #1.取出参与各个位置英雄的胜率 top_vic_rate = hero_loc[hero_loc['top'] > 0]['vic_rate'] jungle_vic_rate = hero_loc[hero_loc['jungle'] >0]['vic_rate'] middle_vic_rate = hero_loc[hero_loc['middle'] >0]['vic_rate'] ad_vic_rate = hero_loc[hero_loc['ad'] >0]['vic_rate'] support_vic_rate = hero_loc[hero_loc['support'] >0]['vic_rate'] #2.取出每个位置英雄胜率最高那位 top_best = top_vic_rate.sort_values(ascending = False).head(1) jungle_best = jungle_vic_rate.sort_values(ascending = False).head(1) middle_best = middle_vic_rate.sort_values(ascending = False).head(1) ad_best = ad_vic_rate.sort_values(ascending = False).head(1) support_best = support_vic_rate.sort_values(ascending = False).head(1) display(top_best,jungle_best,middle_best,ad_best,support_best)

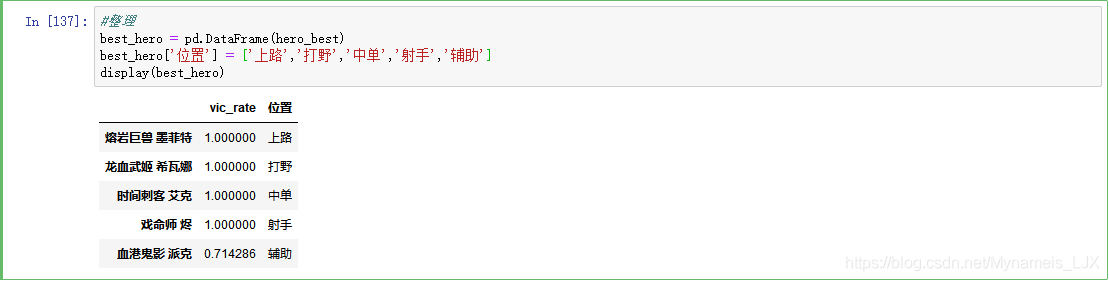
#将每个位置英雄胜率最高的英雄合并成一个表 hero_best = pd.concat((top_best,jungle_best,middle_best,ad_best,support_best),axis = 0) display(hero_best)

#整理 best_hero = pd.DataFrame(hero_best) best_hero['位置'] = ['上路','打野','中单','射手','辅助'] display(best_hero)
- 点赞
- 收藏
- 分享
- 文章举报
 梦想中的麦浪
发布了2 篇原创文章 · 获赞 0 · 访问量 66
私信
关注
梦想中的麦浪
发布了2 篇原创文章 · 获赞 0 · 访问量 66
私信
关注

相关文章推荐
- 数据分析的前途在哪? 职业发展之路?有什么资格认证证书吗?
- 数据分析人员的职业进阶线路
- 数据分析研发工程师职业技能和要求
- 基于SPSS的美国老年夏季运动会运动员数据分析
- 超详细的数据分析职业规划
- 自动分析工具:数据科学家职业的终结者
- 【转载】数据分析职业发展之我见
- Python-2018年"泰迪杯"数据分析职业技能大赛B题任务二-个人代码分享[持续更新]
- 3大领域,4大方向,做好数据分析岗位的职业规划
- Python-2018年"泰迪杯"数据分析职业技能大赛B题任务一-个人代码分享[代码已更新]
- 自动分析工具:数据科学家职业的终结者
- 谁说菜鸟不会数据分析---第1章 1.4数据分析师的职业发展
- 数据分析人员的职业进阶
- Alluxio源码分析写数据:创建文件(二)
- C#抓取网页数据、分析并且去除HTML标签(转载)
- 数据分析与数据仓库建模
- 开源大数据查询分析引擎现状
- scrapy爬虫与数据分析实战
- Cognos做大数据分析也可以棒棒哒
- 常用的数据分析方法都有哪些(一)