实现一个简单的网络爬虫,爬取静态页面数据
2020-02-02 00:43
691 查看
以豆瓣电影为例,爬取《后来的我们》的影评。
找到影评页面
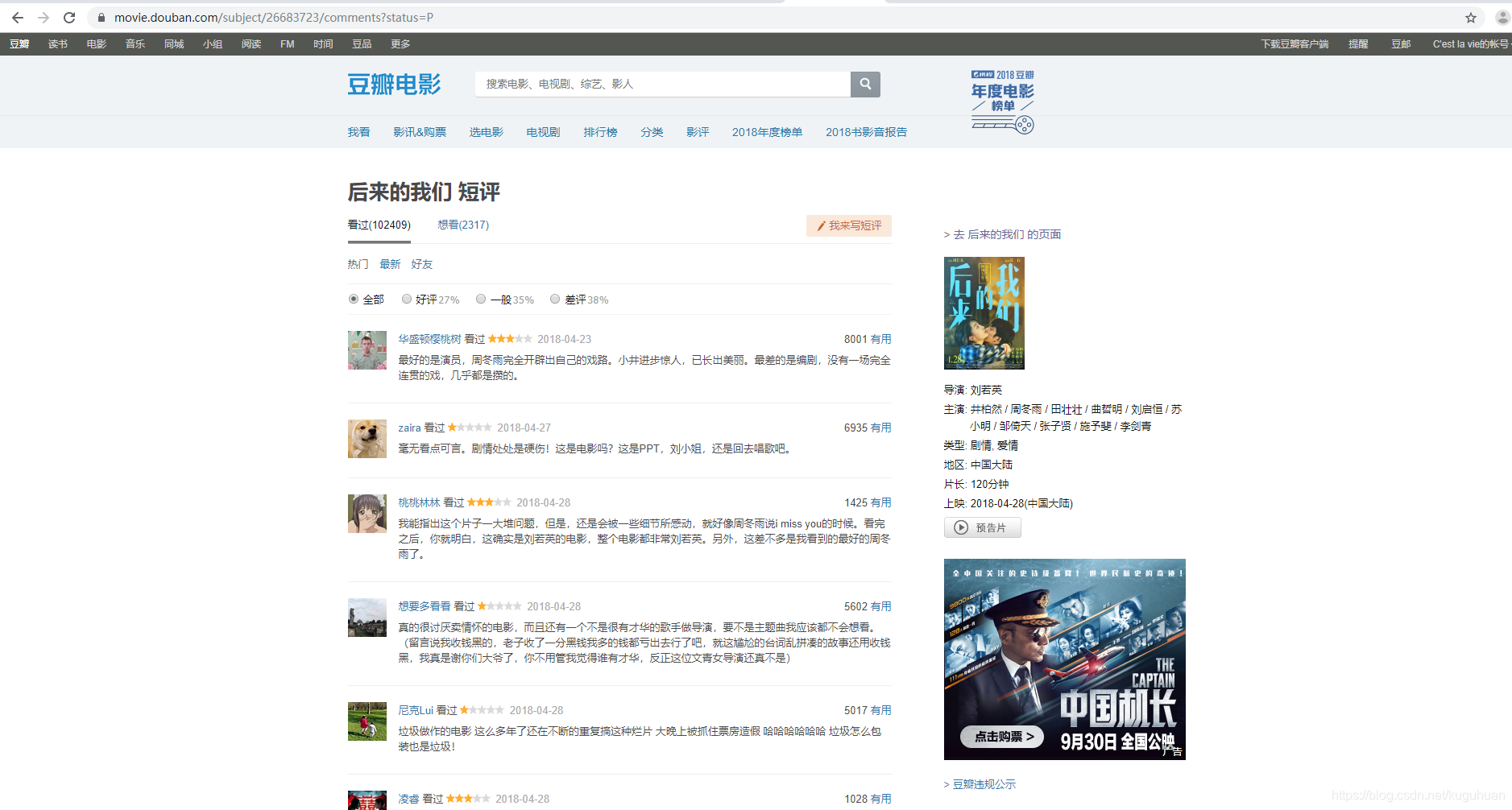
找到链接:https://movie.douban.com/subject/26683723/comments?status=P
右键----点击检查
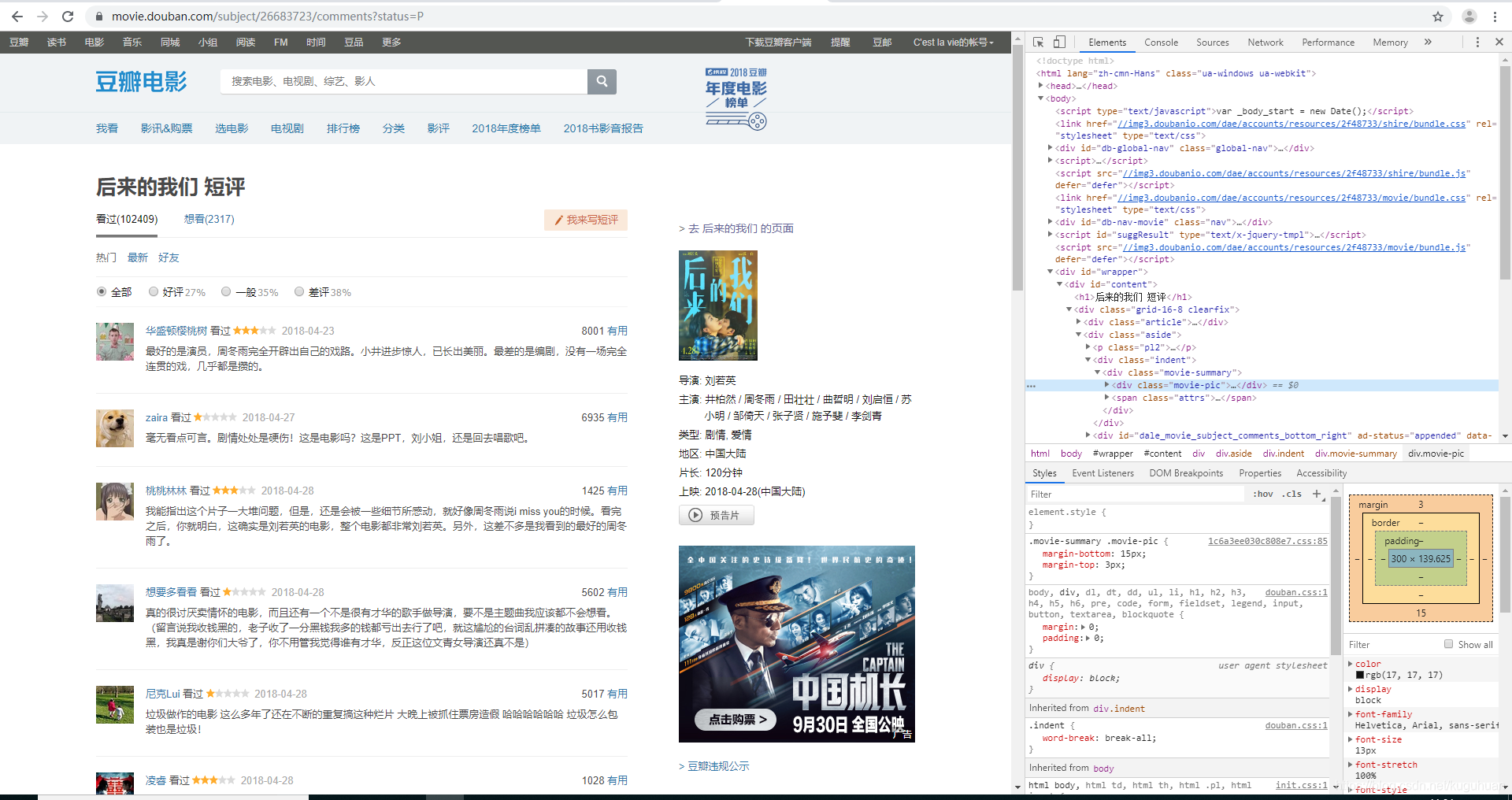
发现影评都是写在span标签里面,class为short

代码如下
# 需要调用的requests 库和 BeautifulSoup库中的bs4工具
import requests
from bs4 import BeautifulSoup
num = 0 # 定义条数的初始值
# 定义一个变量url,为需要爬取数据我网页网址
url = 'https://movie.douban.com/subject/26683723/comments?status=P'
# 获取这个网页的源代码,存放在req中,{}中为不同浏览器的不同User-Agent属性,针对不同浏览器可以自行百度
req = requests.get(url, {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'})
# 生成一个Beautifulsoup对象,用以后边的查找工作
soup = BeautifulSoup(req.text, 'lxml')
# 找到所有span标签中的内容并存放在xml这样一个类似于数组队列的对象中
xml = soup.find_all('span', class_='short')
# 利用循环将xml[]中存放的每一条打印出来
for i in range(len(xml)): # 表示从0到xml的len()长度
msg = xml[i].string
if not msg is None:
num += 1
print('第', num, '条', msg)

爬虫牛逼!!
我们发现,为什么只能爬取到20条评论?不能翻页查询吗?
找到第一页:
https://movie.douban.com/subject/26683723/comments?status=P
第二页:
https://movie.douban.com/subject/26683723/comments?start=20&limit=20&sort=new_score&status=P
第三页:
https://movie.douban.com/subject/26683723/comments?start=40&limit=20&sort=new_score&status=P
第…页:
…
发现规律:只有start= 后面的数字不同,都是20的倍数,原因是因为一页的影评只有20条。
代码修改如下:
# 需要调用的requests 库和 BeautifulSoup库中的bs4工具
import requests
from bs4 import BeautifulSoup
import time
num = 0 # 定义条数的初始值
# 通过循环实现对不同页码的网页的数据爬取
for page in range(10): # 以10页为例
time.sleep(1) # 延时1秒
value = page * 20 # 考虑到start=后边的都是20的整倍数
# 定义一个变量url,为需要爬取数据我网页网址(要将url由'https://movie.douban.com/subject/26683723/comments?status=P'换成'https://movie.douban.com/subject/26683723/comments?start=0&limit=20&sort=new_score&status=P&percent_type=')
# 利用Python中字符串替换的方法:在要替换的地方用%s代替,在语句后%+要替换的内容
url = 'https://movie.douban.com/subject/26683723/comments?start=%s&limit=20&sort=new_score&status=P&percent_type=' % str(value) # str转型
# 获取这个网页的源代码,存放在req中,{}中为不同浏览器的不同User-Agent属性,针对不同浏览器可以自行百度
req = requests.get(url, {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'})
# 生成一个Beautifulsoup对象,用以后边的查找工作
soup = BeautifulSoup(req.text, 'lxml')
# 找到所有span标签中的内容并存放在xml这样一个类似于数组队列的对象中
xml = soup.find_all('span', class_='short')
# 利用循环将xml[]中存放的每一条打印出来
for i in range(len(xml)): # 表示从0到xml的len()长度
msg = xml[i].string
if not msg is None:
num += 1
print('第', num, '条', msg)
效果:

- 点赞
- 收藏
- 分享
- 文章举报
 kuguhuan
发布了42 篇原创文章 · 获赞 11 · 访问量 4323
私信
关注
kuguhuan
发布了42 篇原创文章 · 获赞 11 · 访问量 4323
私信
关注

相关文章推荐
- 网络编程笔记二:一个java爬虫的实现(静态页面)
- Android上实现一个简单的天气预报APP(三) 获取网络数据
- 从零实现一个高性能网络爬虫(二)应对反爬虫之前端数据混淆
- php 爬虫的简单实现, 获取整个页面, 再把页面的数据导入本地的文件当中
- 【Android 网络数据解析实现一个简单的新闻实例(一)】
- 大数据之网络爬虫-一个简单的多线程爬虫
- 【使用JSOUP实现网络爬虫】修改数据-设置一个元素的HTML内容
- Java实现一个简单的网络爬虫
- 使用 PHP中的str_replace函数和preg_replace函数 实现一个简单的 静态数据生成类
- 用java实现一个简单的网络爬虫
- 一个最简单的网络爬虫的实现
- 搜索引擎----Java实现一个简单的网络爬虫
- 【Android 网络数据解析实现一个简单的新闻实例(一)】
- java实现一个简单的网络爬虫代码示例
- 【使用JSOUP实现网络爬虫】修改数据-设置一个元素的HTML内容
- 利用原始套接字实现一个简单的采集网络数据包
- iOS - 网络数据加载等待页面的简单实现
- c#关于网页内容抓取,简单爬虫的实现。(包括动态,静态的)
- 用一个最简单方法解决asp.net页面刷新导致数据的重复提交
- dySE:一个 Java 搜索引擎的实现,第 1 部分: 网络爬虫